
braindecode.models.TCFormer#
- class braindecode.models.TCFormer(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, n_filters_time=32, temp_kernel_lengths=(20, 32, 64), depth_multiplier=2, pool_length_1=8, pool_length_2=7, temp_kernel_length_2=16, group_dim=16, se_reduction=4, n_transformer_layers=2, q_heads=4, kv_heads=2, mlp_ratio=2, drop_path_max=0.25, tcn_depth=2, tcn_kernel_length=4, classifier_max_norm=0.25, drop_prob_conv=0.4, drop_prob_trans=0.4, drop_prob_tcn=0.3, activation=<class 'torch.nn.modules.activation.ELU'>, activation_ffn=<class 'torch.nn.modules.activation.GELU'>)[source]#
TCFormer from Altaheri et al (2025) [tcformer].
Convolution Attention/Transformer
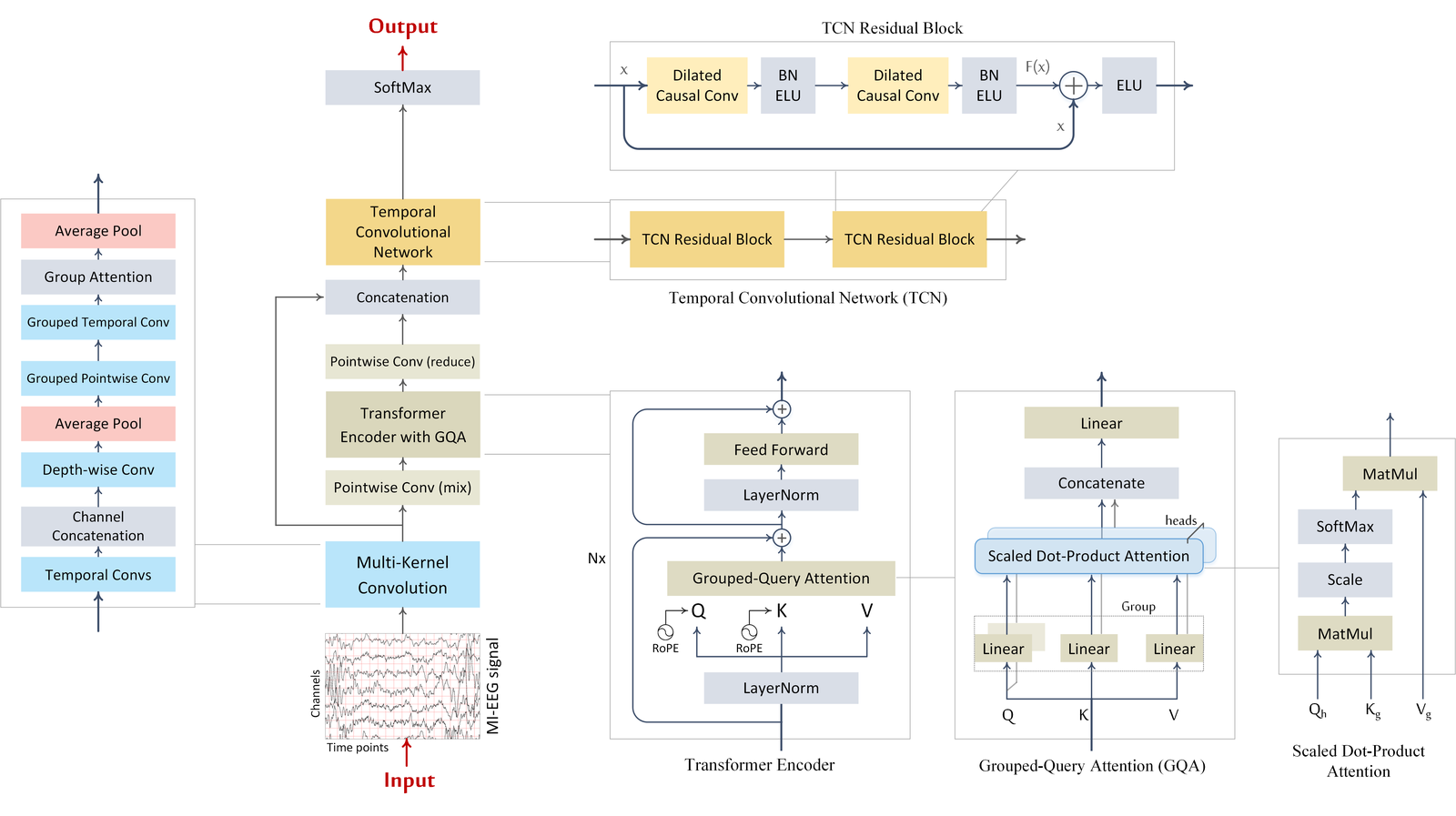
Temporal Convolutional Transformer for EEG-based motor-imagery decoding. It couples a multi-kernel convolutional front-end, a grouped-query Transformer encoder with rotary positional embeddings, and a grouped temporal convolutional network head, reaching state-of-the-art accuracy on BCIC IV-2a, IV-2b and the High-Gamma Dataset while remaining compact (~78k parameters) [tcformer].
Architecture Overview
The raw trial
(batch, n_chans, n_times)flows through three stages: (1)_MultiKernelConvBlockextracts multi-scale spatiotemporal features and emits a short sequence ofd_modeltokens; (2) a stack of_TransformerBlocklayers models global temporal context with grouped-query attention and rotary embeddings; (3) the Transformer output is reduced and concatenated with the convolutional tokens, then a grouped_TCNhead with a per-group_ClassificationHead(final_layer) produces class logits.Macro Components
TCFormer.conv_block(Multi-Kernel Convolutional Embedding)Operations. Parallel temporal convolutions with kernels
temp_kernel_lengths(eachn_filters_timefilters, batch-normed), concatenated, then a depthwise spatial convolution over electrodes (depth_multiplier), average pooling, grouped 1x1 channel reduction tod_model = group_dim * n_groups, a grouped temporal convolution, a grouped squeeze-and-excitation gate, and a second pooling. Role. Turns the raw montage intoTccompact feature tokens, one group per temporal kernel, encoding band-specific rhythms.TCFormer.transformer(Grouped-Query Transformer Encoder)Operations.
n_transformer_layerspre-norm blocks, each applying grouped-query self-attention (q_headsqueries sharingkv_headskey/value groups) with rotary positional embedding, then a position-wise MLP (expansionmlp_ratio); residual connections use a quadratic DropPath schedule up todrop_path_max. Role. Adds global temporal context efficiently (fewer K/V projections than full multi-head attention).TCFormer.tcn+TCFormer.final_layer(Grouped TCN Head)Operations. The reduced Transformer output is concatenated with the convolutional tokens (
d_fused = group_dim * (n_groups + 1)channels,n_groups + 1groups), processed bytcn_depthdilated causal residual blocks (kerneltcn_kernel_length, dilations2**i), the last timestep is taken, and a grouped 1x1 conv produces per-group logits averaged across groups. Role. Long-range causal temporal decoding and read-out.
Temporal, Spatial, and Spectral Encoding
Temporal: multi-kernel and dilated-causal convolutions plus rotary self-attention capture short- and long-range temporal dependencies.
Spatial: a depthwise convolution spanning all electrodes mixes channels per feature map.
Spectral: the three temporal kernel sizes target distinct EEG bands (short kernels -> high frequencies, long kernels -> low frequencies).
Additional Mechanisms
Grouped-query attention and rotary embeddings reduce attention cost while preserving relative-position information.
Group structure is preserved end-to-end: each temporal kernel forms a channel group that stays separated through the grouped reductions, grouped TCN, and per-group classifier.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_filters_time (
int) – Number of temporal filters per kernel (F1). Default32.temp_kernel_lengths (
tuple[int,...]) – Temporal kernel lengths; their count is the number of feature groups. Default(20, 32, 64).depth_multiplier (
int) – Depthwise spatial expansion factor (D). Default2.pool_length_1 (
int) – Average-pool factors after the depthwise and the second temporal conv. Defaults8and7.pool_length_2 (
int) – Average-pool factors after the depthwise and the second temporal conv. Defaults8and7.pool_length_2 – The description is missing.
temp_kernel_length_2 (
int) – Kernel length of the grouped second temporal convolution. Default16.group_dim (
int) – Channels per group (d_group);d_model = group_dim * n_groups. Default16.se_reduction (
int) – Reduction ratio of the grouped squeeze-and-excitation block. Default4.n_transformer_layers (
int) – Number of encoder layers (N). Default2(the 77.8k-parameter headline configuration). Use5for the deeper ~131k variant.q_heads (
int) – Number of query heads and key/value groups for grouped-query attention (q_headsmust be divisible bykv_heads). Defaults4and2.kv_heads (
int) – Number of query heads and key/value groups for grouped-query attention (q_headsmust be divisible bykv_heads). Defaults4and2.kv_heads – The description is missing.
mlp_ratio (
int) – Feed-forward expansion ratio in each encoder block. Default2.drop_path_max (
float) – Maximum stochastic-depth rate (quadratic schedule over depth). Default0.25.tcn_depth (
int) – Number of TCN residual blocks (L). Default2.tcn_kernel_length (
int) – Kernel length of the TCN causal convolutions (KT). Default4.classifier_max_norm (
float) – Max-norm constraint on the classifier convolution weights. Default0.25.drop_prob_conv (
float) – Dropout probabilities of the conv front-end, the Transformer, and the TCN head. Defaults0.4,0.4,0.3.drop_prob_trans (
float) – Dropout probabilities of the conv front-end, the Transformer, and the TCN head. Defaults0.4,0.4,0.3.drop_prob_tcn (
float) – Dropout probabilities of the conv front-end, the Transformer, and the TCN head. Defaults0.4,0.4,0.3.drop_prob_trans – The description is missing.
drop_prob_tcn – The description is missing.
activation (
type[Module]) – Activation class for the convolutional and TCN blocks. Defaulttorch.nn.ELU.activation_ffn (
type[Module]) – Activation class for the Transformer feed-forward sublayer. Defaulttorch.nn.GELU.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is adapted from the original source code [tcformercode] to comply with braindecode’s model conventions. The default configuration reproduces the paper’s headline (Table 1) setup; the released training config additionally uses Adam (lr 0.0009, weight_decay 1e-3), linear warm-up + cosine decay, per-channel z-scoring, and segmentation-and-reconstruction augmentation (handled outside the model, in the training pipeline).
Added in version 1.6.1.
References
[tcformer] (1,2)Altaheri, H., Karray, F., & Karimi, A.-H. (2025). Temporal convolutional transformer for EEG based motor imagery decoding. Scientific Reports, 15, 32959. https://doi.org/10.1038/s41598-025-16219-7
[tcformercode]Altaheri, H. (2025). TCFormer source code. Altaheri/TCFormer
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import TCFormer # Train your model model = TCFormer(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-tcformer-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import TCFormer # Load pretrained model model = TCFormer.from_pretrained("username/my-tcformer-model") # Load with a different number of outputs (head is rebuilt automatically) model = TCFormer.from_pretrained("username/my-tcformer-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = TCFormer.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(x)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.