
braindecode.models.EEGConformer#
- class braindecode.models.EEGConformer(n_outputs=None, n_chans=None, n_filters_time=40, filter_time_length=25, pool_time_length=75, pool_time_stride=15, drop_prob=0.5, num_layers=6, num_heads=10, att_drop_prob=0.5, final_fc_length='auto', return_features=False, activation=<class 'torch.nn.modules.activation.ELU'>, activation_transfor=<class 'torch.nn.modules.activation.GELU'>, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None)[source]#
EEG Conformer from Song et al (2022) [song2022].
Convolution Attention/Transformer
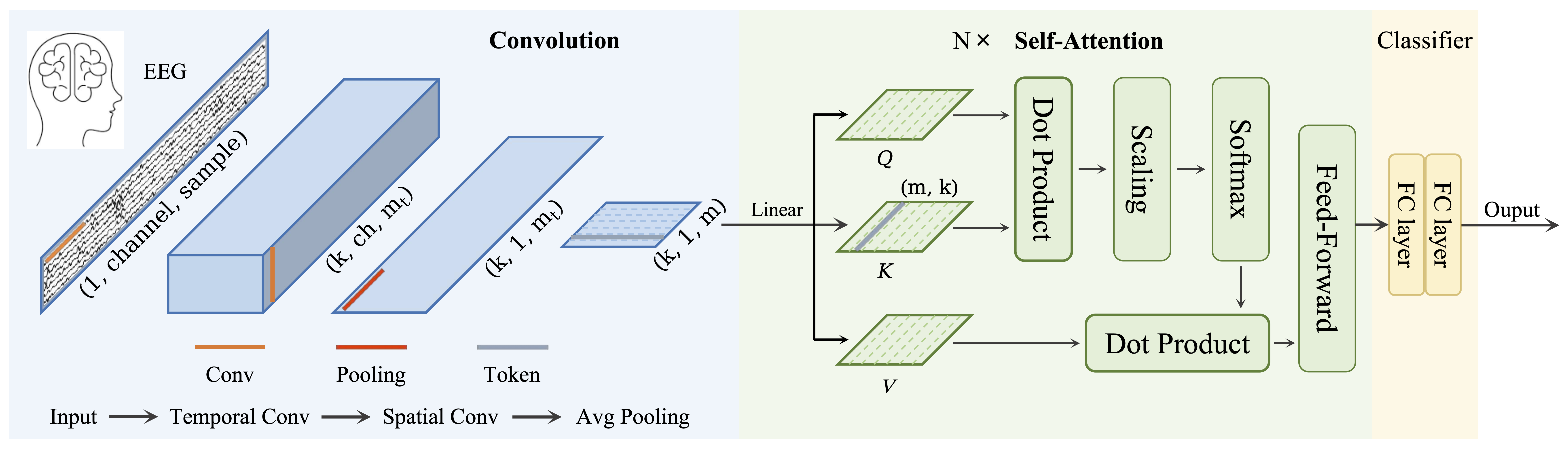
Architectural Overview
EEG-Conformer is a convolution-first model augmented with a lightweight transformer encoder. The end-to-end flow is:
(i)
_PatchEmbeddingconverts the continuous EEG into a compact sequence of tokens via aShallowFBCSPNettemporal–spatial conv stem and temporal pooling;(ii)
_TransformerEncoderapplies small multi-head self-attention to integrate longer-range temporal context across tokens;(iii)
_ClassificationHeadaggregates the sequence and performs a linear readout. This preserves the strong inductive biases of shallow CNN filter banks while adding just enough attention to capture dependencies beyond the pooling horizon [song2022].
Macro Components
_PatchEmbedding(Shallow conv stem → tokens)Operations.
A temporal convolution (:class:torch.nn.Conv2d)
(1 x L_t)forms a data-driven “filter bank”;A spatial convolution (:class:torch.nn.Conv2d) (n_chans x 1)`` projects across electrodes, collapsing the channel axis into a virtual channel.
Normalization function
torch.nn.BatchNormActivation function
torch.nn.ELUAverage Pooling
torch.nn.AvgPoolalong time (kernel(1, P)with stride(1, S))final
1x1torch.nn.Linearprojection.
The result is rearranged to a token sequence
(B, S_tokens, D), whereD = n_filters_time.Interpretability/robustness. Temporal kernels can be inspected as FIR filters; the spatial conv yields channel projections analogous to
ShallowFBCSPNet’s learned spatial filters. Temporal pooling stabilizes statistics and reduces sequence length._TransformerEncoder(context over temporal tokens)Operations.
A stack of
num_layersencoder blocks._TransformerEncoderBlockEach block applies LayerNorm
torch.nn.LayerNormMulti-Head Self-Attention (
num_heads) with dropout + residualMultiHeadAttention(torch.nn.Dropout)LayerNorm
torch.nn.LayerNorm2-layer feed-forward (≈4x expansion,
torch.nn.GELU) with dropout + residual.
Shapes remain
(B, S_tokens, D)throughout.Role. Small attention focuses on interactions among temporal patches (not channels), extending effective receptive fields at modest cost.
ClassificationHead(aggregation + readout)Operations.
Flatten,
torch.nn.Flattenthe sequence(B, S_tokens·D)-MLP (
torch.nn.Linear→ activation (default:torch.nn.ELU) →torch.nn.Dropout→torch.nn.Linear)final Linear to classes.
With
return_features=True, features before the last Linear can be exported for linear probing or downstream tasks.Convolutional Details
- Temporal (where time-domain patterns are learned).
The initial
(1 x L_t)conv per channel acts as a learned filter bank for oscillatory bands and transients. Subsequent AvgPool along time performs local integration, converting activations into “patches” (tokens). Pool length/stride control the token rate and set the lower bound on temporal context within each token.
- Spatial (how electrodes are processed).
A single conv with kernel
(n_chans x 1)spans the full montage to learn spatial projections for each temporal feature map, collapsing the channel axis into a virtual channel before tokenization. This mirrors the shallow spatial step inShallowFBCSPNet(temporal filters → spatial projection → temporal condensation).
- Spectral (how frequency content is captured).
No explicit Fourier/wavelet stage is used. Spectral selectivity emerges implicitly from the learned temporal kernels; pooling further smooths high-frequency noise. The effective spectral resolution is thus governed by
L_tand the pooling configuration.
Attention / Sequential Modules
Type. Standard multi-head self-attention (MHA) with
num_headsheads over the token sequence.Shapes. Input/Output:
(B, S_tokens, D); attention operates along theS_tokensaxis.Role. Re-weights and integrates evidence across pooled windows, capturing dependencies longer than any single token while leaving channel relationships to the convolutional stem. The design is intentionally small—attention refines rather than replaces convolutional feature extraction.
Additional Mechanisms
- Parallel with ShallowFBCSPNet. Both begin with a learned temporal filter bank,
spatial projection across electrodes, and early temporal condensation.
ShallowFBCSPNetthen computes band-power (via squaring/log-variance), whereas EEG-Conformer applies BN/ELU and continues with attention over tokens to refine temporal context before classification.
- Tokenization knob.
pool_time_lengthand especiallypool_time_strideset the number of tokens
S_tokens. Smaller strides → more tokens and higher attention capacity (but higher compute); larger strides → fewer tokens and stronger inductive bias.
- Tokenization knob.
- Embedding dimension = filters.
n_filters_timeserves double duty as both the number of temporal filters in the stem and the transformer’s embedding size
D, simplifying dimensional alignment.
- Embedding dimension = filters.
Usage and Configuration
- Instantiation. Choose
n_filters_time(embedding sizeD) and filter_time_lengthto match the rhythms of interest. Tunepool_time_length/strideto trade temporal resolution for sequence length. Keepnum_layersmodest (e.g., 4–6) and setnum_headsto divideD.final_fc_length="auto"infers the flattened size from PatchEmbedding.
- Instantiation. Choose
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
n_filters_time (int) – Number of temporal filters, defines also embedding size.
filter_time_length (int) – Length of the temporal filter.
pool_time_length (int) – Length of temporal pooling filter.
pool_time_stride (int) – Length of stride between temporal pooling filters.
drop_prob (float) – Dropout rate of the convolutional layer.
num_layers (int) – Number of self-attention layers.
num_heads (int) – Number of attention heads.
att_drop_prob (float) – Dropout rate of the self-attention layer.
final_fc_length (int | str) – The dimension of the fully connected layer.
return_features (bool) – If True, the forward method returns the features before the last classification layer. Defaults to False.
activation (
type[Module]) – Activation function as parameter. Default is nn.ELUactivation_transfor (
type[Module]) – Activation function as parameter, applied at the FeedForwardBlock module inside the transformer. Default is nn.GeLUn_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
The authors recommend using data augmentation before using Conformer, e.g. segmentation and recombination, Please refer to the original paper and code for more details [ConformerCode].
The model was initially tuned on 4 seconds of 250 Hz data. Please adjust the scale of the temporal convolutional layer, and the pooling layer for better performance.
Added in version 0.8.
We aggregate the parameters based on the parts of the models, or when the parameters were used first, e.g.
n_filters_time.Added in version 1.1.
References
[song2022] (1,2)Song, Y., Zheng, Q., Liu, B. and Gao, X., 2022. EEG conformer: Convolutional transformer for EEG decoding and visualization. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31, pp.710-719. https://ieeexplore.ieee.org/document/9991178
[ConformerCode]Song, Y., Zheng, Q., Liu, B. and Gao, X., 2022. EEG conformer: Convolutional transformer for EEG decoding and visualization. eeyhsong/EEG-Conformer.
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import EEGConformer # Train your model model = EEGConformer(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-eegconformer-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import EEGConformer # Load pretrained model model = EEGConformer.from_pretrained("username/my-eegconformer-model") # Load with a different number of outputs (head is rebuilt automatically) model = EEGConformer.from_pretrained("username/my-eegconformer-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = EEGConformer.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(x)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.