
braindecode.models.FBCNet#
- class braindecode.models.FBCNet(n_chans=None, n_outputs=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, n_bands=9, n_filters_spat=32, temporal_layer='LogVarLayer', n_dim=3, stride_factor=4, activation=<class 'torch.nn.modules.activation.SiLU'>, linear_max_norm=0.5, cnn_max_norm=2.0, filter_parameters=None)[source]#
FBCNet from Mane, R et al (2021) [fbcnet2021].
Convolution Filterbank
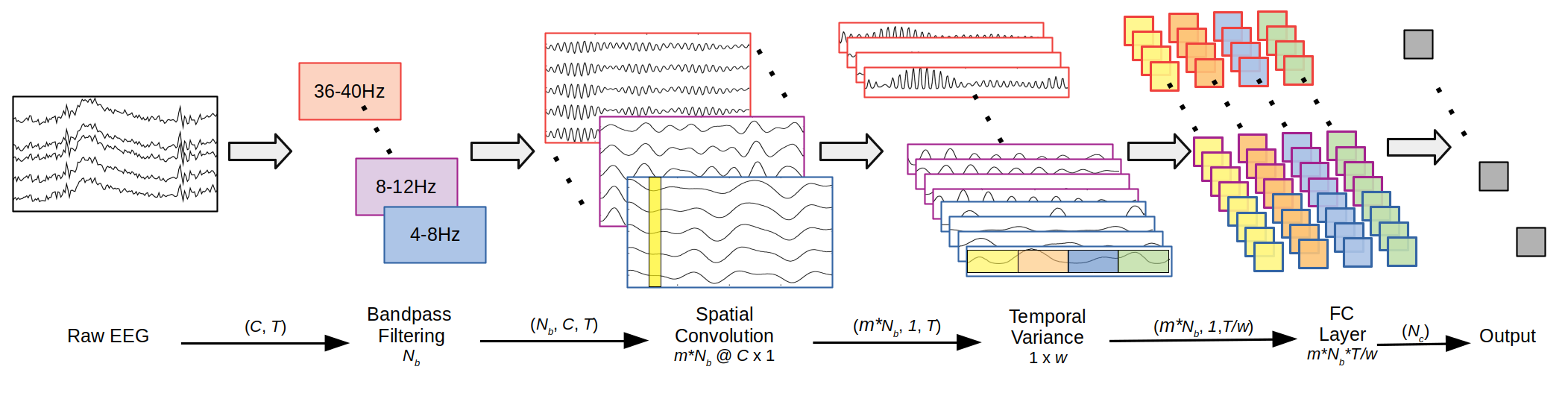
The FBCNet model applies spatial convolution and variance calculation along the time axis, inspired by the Filter Bank Common Spatial Pattern (FBCSP) algorithm.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_bands (int or None or list[tuple[int, int]]], default=9) – Number of frequency bands. Could
n_filters_spat (
int) – Number of spatial filters for the first convolution.temporal_layer (
str) – Type of temporal aggregator layer. Options: ‘VarLayer’, ‘StdLayer’, ‘LogVarLayer’, ‘MeanLayer’, ‘MaxLayer’.n_dim (
int) – Number of dimensions for the temporal reductorstride_factor (
int) – Stride factor for reshaping.activation (
type[Module]) – Activation function class to apply in Spatial Convolution Block.linear_max_norm (
float) – Maximum norm for the final linear layer.cnn_max_norm (
float) – Maximum norm for the spatial convolution layer.filter_parameters (
dict[Any,Any] |None) – Dictionary of parameters to use for the FilterBankLayer. If None, a default Chebyshev Type II filter with transition bandwidth of 2 Hz and stop-band ripple of 30 dB will be used.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct and has not been checked by the original authors; it has only been reimplemented from the paper description and source code [fbcnetcode2021]. There is a difference in the activation function; in the paper, the ELU is used as the activation function, but in the original code, SiLU is used. We followed the code.
References
[fbcnet2021]Mane, R., Chew, E., Chua, K., Ang, K. K., Robinson, N., Vinod, A. P., … & Guan, C. (2021). FBCNet: A multi-view convolutional neural network for brain-computer interface. preprint arXiv:2104.01233.
[fbcnetcode2021]Link to source-code: ravikiran-mane/FBCNet
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import FBCNet # Train your model model = FBCNet(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-fbcnet-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import FBCNet # Load pretrained model model = FBCNet.from_pretrained("username/my-fbcnet-model") # Load with a different number of outputs (head is rebuilt automatically) model = FBCNet.from_pretrained("username/my-fbcnet-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = FBCNet.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods