
braindecode.models.PBT#
- class braindecode.models.PBT(n_chans=None, n_outputs=None, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None, d_input=64, embed_dim=128, num_layers=4, num_heads=4, drop_prob=0.1, learnable_cls=True, bias_transformer=False, activation=<class 'torch.nn.modules.activation.GELU'>)[source]#
Patched Brain Transformer (PBT) model from Klein et al (2025) [pbt].
Foundation Model
This implementation was based in timonkl/PatchedBrainTransformer
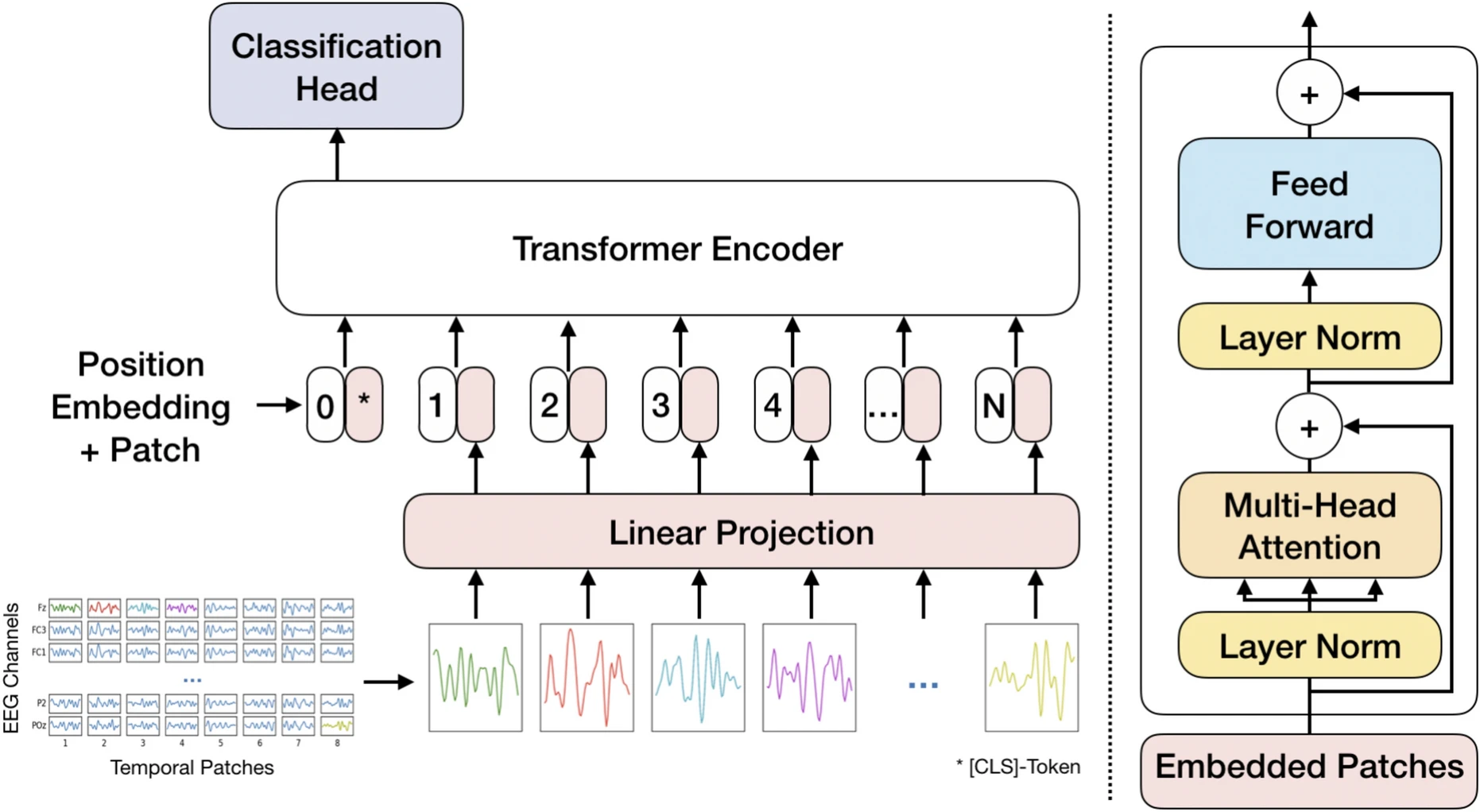
PBT tokenizes EEG trials into per-channel patches, linearly projects each patch to a model embedding dimension, prepends a classification token and adds channel-aware positional embeddings. The token sequence is processed by a Transformer encoder stack and classification is performed from the classification token.
Macro Components
PBT.tokenization(patch extraction)Operations. The pre-processed EEG signal \(X \in \mathbb{R}^{C \times T}\) (with \(C = \text{n_chans}\) and \(T = \text{n_times}\)) is divided into non-overlapping patches of size \(d_{\text{input}}\) along the time axis. This process yields \(N\) total patches, calculated as \(N = C \left\lfloor \frac{T}{D} \right\rfloor\) (where \(D = d_{\text{input}}\)). When time shifts are applied, \(N\) decreases to \(N = C \left\lfloor \frac{T - T_{\text{aug}}}{D} \right\rfloor\).
Role. Tokenizes EEG trials into fixed-size, per-channel patches so the model remains adaptive to different numbers of channels and recording lengths. Process is inspired by Vision Transformers [visualtransformer] and adapted for GPT context from [efficient-batchpacking].
PBT.patch_projection(patch embedding)Operations. The linear layer
PBT.patch_projectionmaps the tokens from dimension \(d_{\text{input}}\) to the Transformer embedding dimension \(d_{\text{model}}\). Patches \(X_P\) are projected as \(X_E = X_P W_E^\top\), where \(W_E \in \mathbb{R}^{d_{\text{model}} \times D}\). In this configuration \(d_{\text{model}} = 2D\) with \(D = d_{\text{input}}\).Interpretability. Learns periodic structures similar to frequency filters in the first convolutional layers of CNNs (for example
EEGNet). The learned filters frequently focus on the high-frequency range (20-40 Hz), which correlates with beta and gamma waves linked to higher concentration levels.PBT.cls_token(classification token)Operations. A classification token \([c_{\text{ls}}] \in \mathbb{R}^{1 \times d_{\text{model}}}\) is prepended to the projected patch sequence \(X_E\). The CLS token can optionally be learnable (see
learnable_cls).Role. Acts as a dedicated readout token that aggregates information through the Transformer encoder stack.
PBT.pos_embedding(positional embedding)Operations. Positional indices are generated by
PBT.linear_projection, an instance of_ChannelEncoding, and mapped to vectors throughEmbedding. The embedding table \(W_{\text{pos}} \in \mathbb{R}^{(N+1) \times d_{\text{model}}}\) is added to the token sequence, yielding \(X_{\text{pos}} = [c_{\text{ls}}, X_E] + W_{\text{pos}}\).Role/Interpretability. Introduces spatial and temporal dependence to counter the position invariance of the Transformer encoder. The learned positional embedding exposes spatial relationships, often revealing a symmetric pattern in central regions (C1-C6) associated with the motor cortex.
PBT.transformer_encoder(sequence processing and attention)Operations. The token sequence passes through \(n_{\text{blocks}}\) Transformer encoder layers. Each block combines a Multi-Head Self-Attention (MHSA) module with
num_headsattention heads and a Feed-Forward Network (FFN). Both MHSA and FFN use parallel residual connections with Layer Normalization inside the blocks and apply dropout (drop_prob) within the Transformer components.Role/Robustness. Self-attention enables every token to consider all others, capturing global temporal and spatial dependencies immediately and adaptively. This architecture accommodates arbitrary numbers of patches and channels, supporting pre-training across diverse datasets.
PBT.final_layer(readout)Operations. A linear layer operates on the processed CLS token only, and the model predicts class probabilities as \(y = \operatorname{softmax}([c_{\text{ls}}] W_{\text{class}}^\top + b_{\text{class}})\).
Role. Performs the final classification from the information aggregated into the CLS token after the Transformer encoder stack.
Convolutional Details
PBT omits convolutional layers; equivalent feature extraction is carried out by the patch pipeline and attention stack.
Temporal. Tokenization slices the EEG into fixed windows of size \(D = d_{\text{input}}\) (for the default configuration, \(D=64\) samples \(\approx 0.256\,\text{s}\) at \(250\,\text{Hz}\)), while
PBT.patch_projectionlearns periodic patterns within each patch. The Transformer encoder then models long- and short-range temporal dependencies through self-attention.Spatial. Patches are channel-specific, keeping the architecture adaptive to any electrode montage. Channel-aware positional encodings \(W_{\text{pos}}\) capture relationships between nearby sensors; learned embeddings often form symmetric motifs across motor cortex electrodes (C1–C6), and self-attention propagates information across all channels jointly.
Spectral.
PBT.patch_projectionacts similarly to the first convolutional layer inEEGNet, learning frequency-selective filters without an explicit Fourier transform. The highest-energy filters typically reside between \(20\) and \(40\,\text{Hz}\), aligning with beta/gamma rhythms tied to focused motor imagery.
Attention / Sequential Modules
Attention Details.
PBT.transformer_encoderstacks \(n_{\text{blocks}}\) Transformer encoder layers with Multi-Head Self-Attention. Every token attends to all others, enabling immediate global integration across time and channels and supporting heterogeneous datasets. Attention rollout visualisations highlight strong activations over motor cortex electrodes (C3, C4, Cz) during motor imagery decoding.
Warning
Important: As the other Foundation Models in Braindecode,
PBTis designed for large-scale pre-training and fine-tuning. Training from scratch on small datasets may lead to suboptimal results. Cross-Dataset pre-training and subsequent fine-tuning is recommended to leverage the full potential of this architecture.- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
d_input (
int) – Size (in samples) of each patch (token) extracted along the time axis.embed_dim (
int) – Transformer embedding dimensionality.num_layers (
int) – Number of Transformer encoder layers.num_heads (
int) – Number of attention heads.drop_prob (
float) – Dropout probability used in Transformer components.learnable_cls (bool, optional) – Whether the classification token is learnable.
bias_transformer (bool, optional) – Whether to use bias in Transformer linear layers.
activation (
type[Module]) – Activation function class to use in Transformer feed-forward layers.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[pbt]Klein, T., Minakowski, P., & Sager, S. (2025). Flexible Patched Brain Transformer model for EEG decoding. Scientific Reports, 15(1), 1-12. https://www.nature.com/articles/s41598-025-86294-3
[visualtransformer]Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J. & Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations (ICLR).
[efficient-batchpacking]Krell, M. M., Kosec, M., Perez, S. P., & Fitzgibbon, A. (2021). Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance. arXiv preprint arXiv:2107.02027.
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import PBT # Train your model model = PBT(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-pbt-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import PBT # Load pretrained model model = PBT.from_pretrained("username/my-pbt-model") # Load with a different number of outputs (head is rebuilt automatically) model = PBT.from_pretrained("username/my-pbt-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = PBT.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(X)[source]#
The implementation follows the original code logic
split input into windows of size (num_embeddings - 1) * d_input
for each window: reshape into tokens, map positional indices to embeddings, add cls token, run Transformer encoder and collect CLS outputs
aggregate CLS outputs across windows (if >1) and pass through final_layer