braindecode.models.SignalJEPA#
- class braindecode.models.SignalJEPA(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, *, feature_encoder__conv_layers_spec=((8, 32, 8), (16, 2, 2), (32, 2, 2), (64, 2, 2), (64, 2, 2)), drop_prob=0.0, feature_encoder__mode='default', feature_encoder__conv_bias=False, activation=<class 'torch.nn.modules.activation.GELU'>, pos_encoder__spat_dim=30, pos_encoder__time_dim=34, pos_encoder__sfreq_features=1.0, pos_encoder__spat_kwargs=None, transformer__d_model=64, transformer__num_encoder_layers=8, transformer__num_decoder_layers=4, transformer__nhead=8, channel_embedding='scratch')[source]#
Architecture introduced in signal-JEPA for self-supervised pre-training, Guetschel, P et al (2024) [1]
Convolution Channel Foundation Model
This model is not meant for classification but for SSL pre-training. Its output shape depends on the input shape. For classification purposes, three variants of this model are available:
The classification architectures can either be instantiated from scratch (random parameters) or from a pre-trained
SignalJEPAmodel.Added in version 0.9.
Pretrained Weights
Two checkpoint variants are published on HuggingFace:
braindecode/signal-jepa: full encoder + pre-trained channel embedding table (62 rows, one per pre-training channel). Use when your channel names are a subset of the pre-training set (channel_embedding='pretrain_aligned').braindecode/signal-jepa_without-chans: same encoder, channel embedding weights stripped. Use when your channel set differs from pre-training; the table is freshly initialized from your channel locations (channel_embedding='scratch', the default).
Important
Pre-trained Weights Available
from braindecode.models import SignalJEPA # Load encoder + pre-trained channel embeddings (62 channels): model = SignalJEPA.from_pretrained("braindecode/signal-jepa") # Select a subset of the 62 pre-training channels: model = SignalJEPA.from_pretrained( "braindecode/signal-jepa", chs_info=[{"ch_name": "Fp1", "loc": [...]}, {"ch_name": "Cz", "loc": [...]}], ) # Arbitrary channel set (channel embedding re-initialized from your locs): model = SignalJEPA.from_pretrained( "braindecode/signal-jepa_without-chans", chs_info=[{"ch_name": "A", "loc": [...]}, ...], strict=False, )
To push your own trained model to the Hub:
model.push_to_hub( repo_id="username/my-sjepa-model", commit_message="Upload trained SignalJEPA model", )
Requires installing
braindecode[hub]for Hub integration.Usage
from braindecode.models import SignalJEPA model = SignalJEPA( chs_info=[{"ch_name": "Fp1", "loc": [...]}, ...], input_window_seconds=16.0, sfreq=128, ) # Forward: (batch, n_chans, n_times) -> (batch, n_chans * n_patches, emb_dim) features = model(eeg_data)
Warning
Pre-trained at 128 Hz on EEG bandpass-filtered between 0.5 and 40 Hz and rescaled by a factor of \(10^{6}\) (volts to microvolts). Apply the same preprocessing to your data to match the pre-training distribution.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
feature_encoder__conv_layers_spec (
Sequence[tuple[int,int,int]]) –tuples have shape
(dim, k, stride)where:dim: number of output channels of the layer (unrelated to EEG channels);k: temporal length of the layer’s kernel;stride: temporal stride of the layer’s kernel.
drop_prob (
float)feature_encoder__mode (
str) – Normalisation mode. Eitherdefaultorlayer_norm.feature_encoder__conv_bias (
bool)activation (
type[Module]) – Activation layer for the feature encoder.pos_encoder__spat_dim (
int) – Number of dimensions to use to encode the spatial position of the patch, i.e. the EEG channel.pos_encoder__time_dim (
int) – Number of dimensions to use to encode the temporal position of the patch.pos_encoder__sfreq_features (
float) – The “downsampled” sampling frequency returned by the feature encoder.pos_encoder__spat_kwargs (
dict|None) – Additional keyword arguments to pass to thenn.Embeddinglayer used to embed the channel names.transformer__d_model (
int) – The number of expected features in the encoder/decoder inputs.transformer__num_encoder_layers (
int) – The number of encoder layers in the transformer.transformer__num_decoder_layers (
int) – The number of decoder layers in the transformer.transformer__nhead (
int) – The number of heads in the multiheadattention models.channel_embedding (
str) –How to initialize the
_ChannelEmbeddingtable."scratch": table haslen(chs_info)rows, initialized from user locations.chs_infois required."pretrain_aligned": table has 62 rows, initialized from the pre-training locations. Ifchs_infois provided, every channel name must match one in the pre-training set (case-insensitive);forwardwill then expect input with as many channels aschs_infohas. Ifchs_info=None, the model runs on the full 62 channels in the pre-training order.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[1]Guetschel, P., Moreau, T., & Tangermann, M. (2024). S-JEPA: towards seamless cross-dataset transfer through dynamic spatial attention. In 9th Graz Brain-Computer Interface Conference, https://www.doi.org/10.3217/978-3-99161-014-4-003
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import SignalJEPA # Train your model model = SignalJEPA(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-signaljepa-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import SignalJEPA # Load pretrained model model = SignalJEPA.from_pretrained("username/my-signaljepa-model") # Load with a different number of outputs (head is rebuilt automatically) model = SignalJEPA.from_pretrained("username/my-signaljepa-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = SignalJEPA.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(X, return_features=False)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
X – The description is missing.
return_features – The description is missing.
Examples using braindecode.models.SignalJEPA#
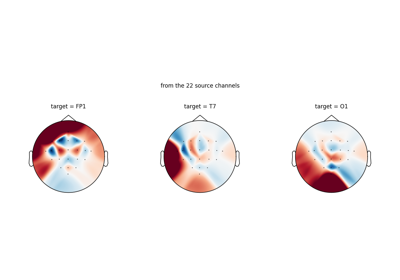
Loading Pretrained Foundation Models on Arbitrary Channel Sets