
braindecode.preprocessing.exponential_moving_standardize#
- braindecode.preprocessing.exponential_moving_standardize(data, factor_new=0.001, init_block_size=None, eps=0.0001)[source]#
Perform exponential moving standardization.
Compute the exponential moving mean \(m_t\) at time t as a weighted average: \(m_t = \frac{\sum_{i=0}^t (1-\alpha)^i x_{t-i}}{\sum_{i=0}^t (1-\alpha)^i}\) where \(\alpha\) is
factor_new.Then, compute exponential moving variance \(v_t\) at time t as a weighted average of the squared demeaned signal: \(v_t = \frac{\sum_{i=0}^t (1-\alpha)^i (x_{t-i} - m_{t-i})^2}{\sum_{i=0}^t (1-\alpha)^i}\).
Finally, standardize the data point \(x_t\) at time t as: \(x'_t=(x_t - m_t) / max(\sqrt{v_t}, eps)\).
- Parameters:
- Returns:
standardized – Standardized data.
- Return type:
np.ndarray (n_channels, n_times)
Examples using braindecode.preprocessing.exponential_moving_standardize#
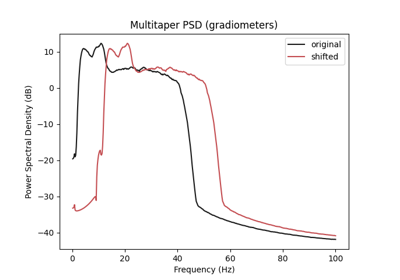
Cleaning EEG Data with EEGPrep for Trialwise Decoding
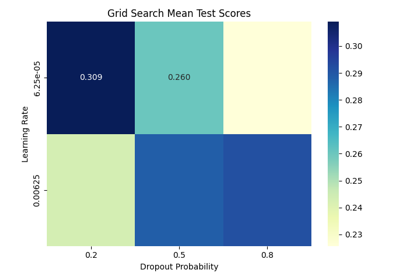


Fingers flexion cropped decoding on BCIC IV 4 ECoG Dataset
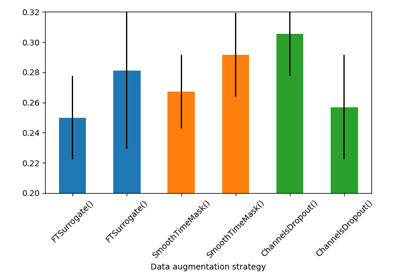
Searching the best data augmentation on BCIC IV 2a Dataset
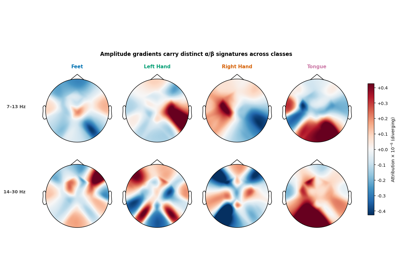

Fingers flexion decoding on BCIC IV 4 ECoG Dataset