
braindecode.models.USleep#
- class braindecode.models.USleep(n_chans=None, sfreq=None, depth=12, n_time_filters=5, complexity_factor=1.67, with_skip_connection=True, n_outputs=5, input_window_seconds=None, time_conv_size_s=0.0703125, ensure_odd_conv_size=False, activation=<class 'torch.nn.modules.activation.ELU'>, chs_info=None, n_times=None)[source]#
Sleep staging architecture from Perslev et al (2021) [1].
Convolution
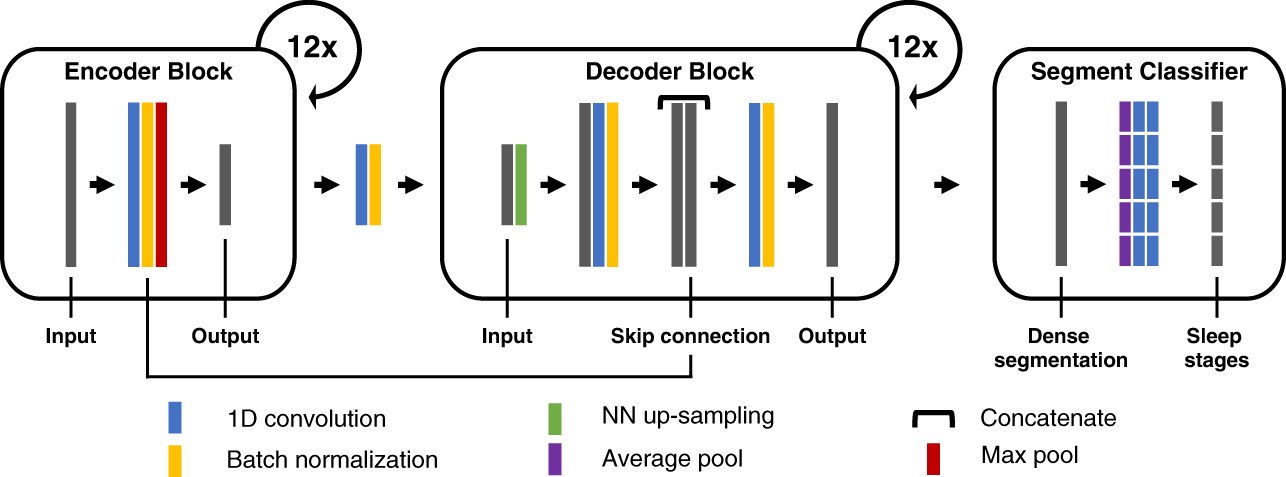
Figure: U-Sleep consists of an encoder (left) which encodes the input signals into dense feature representations, a decoder (middle) which projects the learned features into the input space to generate a dense sleep stage representation, and finally a specially designed segment classifier (right) which generates sleep stages at a chosen temporal resolution.#
Architectural Overview
U-Sleep is a fully convolutional, feed-forward encoder-decoder with a segment classifier head for time-series segmentation (sleep staging). It maps multi-channel PSG (EEG+EOG) to a dense, high-frequency per-sample representation, then aggregates it into fixed-length stage labels (e.g., 30 s). The network processes arbitrarily long inputs in one forward pass (resampling to 128 Hz), allowing whole-night hypnograms in seconds.
(i).
_EncoderBlockextracts progressively deeper temporal features at lower resolution;(ii).
_Decoderupsamples and fuses encoder features via U-Net-style skips to recover a per-sample stage map;(iii). Segment Classifier mean-pools over the target epoch length and applies two pointwise convs to yield per-epoch probabilities. Integrates into the USleep class.
Macro Components
Encoder
_EncoderBlock(multi-scale temporal feature extractor; downsampling x2 per block)Operations.
Conv1d (
torch.nn.Conv1d) with kernel9(stride1, no dilation)ELU (
torch.nn.ELU)Batch Norm (
torch.nn.BatchNorm1d)Max Pool 1d,
torch.nn.MaxPool1d(kernel=2, stride=2).
Filters grow with depth by a factor of
sqrt(2)(startc_1=5); each block exposes a skip (pre-pooling activation) to the matching decoder block. Role. Slow, uniform downsampling preserves early information while expanding the effective temporal context over minutes—foundational for robust cross-cohort staging.
The number of filters grows with depth (capacity scaling); each block also exposes a skip (pre-pool) to the matching decoder block.
- Rationale.
Slow, uniform downsampling (x2 each level) preserves information in early layers while expanding the temporal receptive field over the minutes.
Decoder
_DecoderBlock(progressive upsampling + skip fusion to high-frequency map, 12 blocks; upsampling x2 per block)Operations.
Nearest-neighbor upsample,
nn.Upsample(x2)Convolution2d (k=2),
torch.nn.Conv2dELU,
torch.nn.ELUBatch Norm,
torch.nn.BatchNorm2dConcatenate with the encoder skip at the same temporal scale,
torch.catConvolution,
torch.nn.Conv2dELU,
torch.nn.ELUBatch Norm,
torch.nn.BatchNorm2d.
Output: A multi-class, high-frequency per-sample representation aligned to the input rate (128 Hz).
Segment Classifier incorporate into :class:`braindecode.models.USleep` (aggregation to fixed epochs)
Operations.
Mean-pool,
torch.nn.AvgPool2dper class with kernel = epoch length i and stride i1x1 conv,
torch.nn.Conv2dELU,
torch.nn.ELU1x1 conv,
torch.nn.Conv2dwith(T, K)(epochs x stages).
Role: Learns a non-linear weighted combination over each 30-s window (unlike U-Time’s linear combiner).
Convolutional Details
Temporal (where time-domain patterns are learned).
All convolutions are 1-D along time; depth (12 levels) plus pooling yields an extensive receptive field (reported sensitivity to ±6.75 min around each epoch; theoretical field ≈ 9.6 min at the deepest layer). The decoder restores sample-level resolution before epoch aggregation.
Spatial (how channels are processed).
Convolutions mix across the channel dimension jointly with time (no separate spatial operator). The system is montage-agnostic (any reasonable EEG/EOG pair) and was trained across diverse cohorts/protocols, supporting robustness to channel placement and hardware differences.
Spectral (how frequency content is captured).
No explicit Fourier/wavelet transform is used; the stack of temporal convolutions acts as a learned filter bank whose effective bandwidth grows with depth. The high-frequency decoder output (128 Hz) retains fine temporal detail for the segment classifier.
Attention / Sequential Modules
U-Sleep contains no attention or recurrent units; it is a pure feed-forward, fully convolutional segmentation network inspired by U-Net/U-Time, favoring training stability and cross-dataset portability.
Additional Mechanisms
U-Net lineage with task-specific head. U-Sleep extends U-Time by being deeper (12 vs. 4 levels), switching ReLU→**ELU**, using uniform pooling (2) at all depths, and replacing the linear combiner with a two-layer pointwise head—improving capacity and resilience across datasets.
Arbitrary-length inference. Thanks to full convolutionality and tiling-free design, entire nights can be staged in a single pass on commodity hardware. Inputs shorter than ≈ 17.5 min may reduce performance by limiting long-range context.
Complexity scaling (alpha). Filter counts can be adjusted by a global complexity factor to trade accuracy and memory (as described in the paper’s topology table).
Usage and Configuration
Practice. Resample PSG to 128 Hz and provide at least two channels (one EEG, one EOG). Choose epoch length i (often 30 s); ensure windows long enough to exploit the model’s receptive field (e.g., training on ≥ 17.5 min chunks).
- Parameters:
n_chans (int) – Number of EEG or EOG channels. Set to 2 in [1] (1 EEG, 1 EOG).
depth (int) – Number of conv blocks in encoding layer (number of 2x2 max pools). Note: each block halves the spatial dimensions of the features.
n_time_filters (int) – Initial number of convolutional filters. Set to 5 in [1].
complexity_factor (float) – Multiplicative factor for the number of channels at each layer of the U-Net. Set to 2 in [1].
with_skip_connection (bool) – If True, use skip connections in decoder blocks.
n_outputs (int) – Number of outputs/classes. Set to 5.
input_window_seconds (float) – Size of the input, in seconds. Set to 30 in [1].
time_conv_size_s (float) – Size of the temporal convolution kernel, in seconds. Set to 9 / 128 in [1].
ensure_odd_conv_size (bool) – If True and the size of the convolutional kernel is an even number, one will be added to it to ensure it is odd, so that the decoder blocks can work. This can be useful when using different sampling rates from 128 or 100 Hz.
activation (
type[Module]) – Activation function class to apply. Should be a PyTorch activation module class likenn.ReLUornn.ELU. Default isnn.ELU.chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import USleep # Train your model model = USleep(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-usleep-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import USleep # Load pretrained model model = USleep.from_pretrained("username/my-usleep-model") # Load with a different number of outputs (head is rebuilt automatically) model = USleep.from_pretrained("username/my-usleep-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = USleep.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
Examples using braindecode.models.USleep#
Sleep staging on the Sleep Physionet dataset using U-Sleep network