
braindecode.models.FBLightConvNet#
- class braindecode.models.FBLightConvNet(n_chans=None, n_outputs=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, n_bands=9, n_filters_spat=32, n_dim=3, stride_factor=4, win_len=250, heads=8, weight_softmax=True, bias=False, activation=<class 'torch.nn.modules.activation.ELU'>, verbose=False, filter_parameters=None)[source]#
LightConvNet from Ma, X et al (2023) [lightconvnet].
Convolution Filterbank
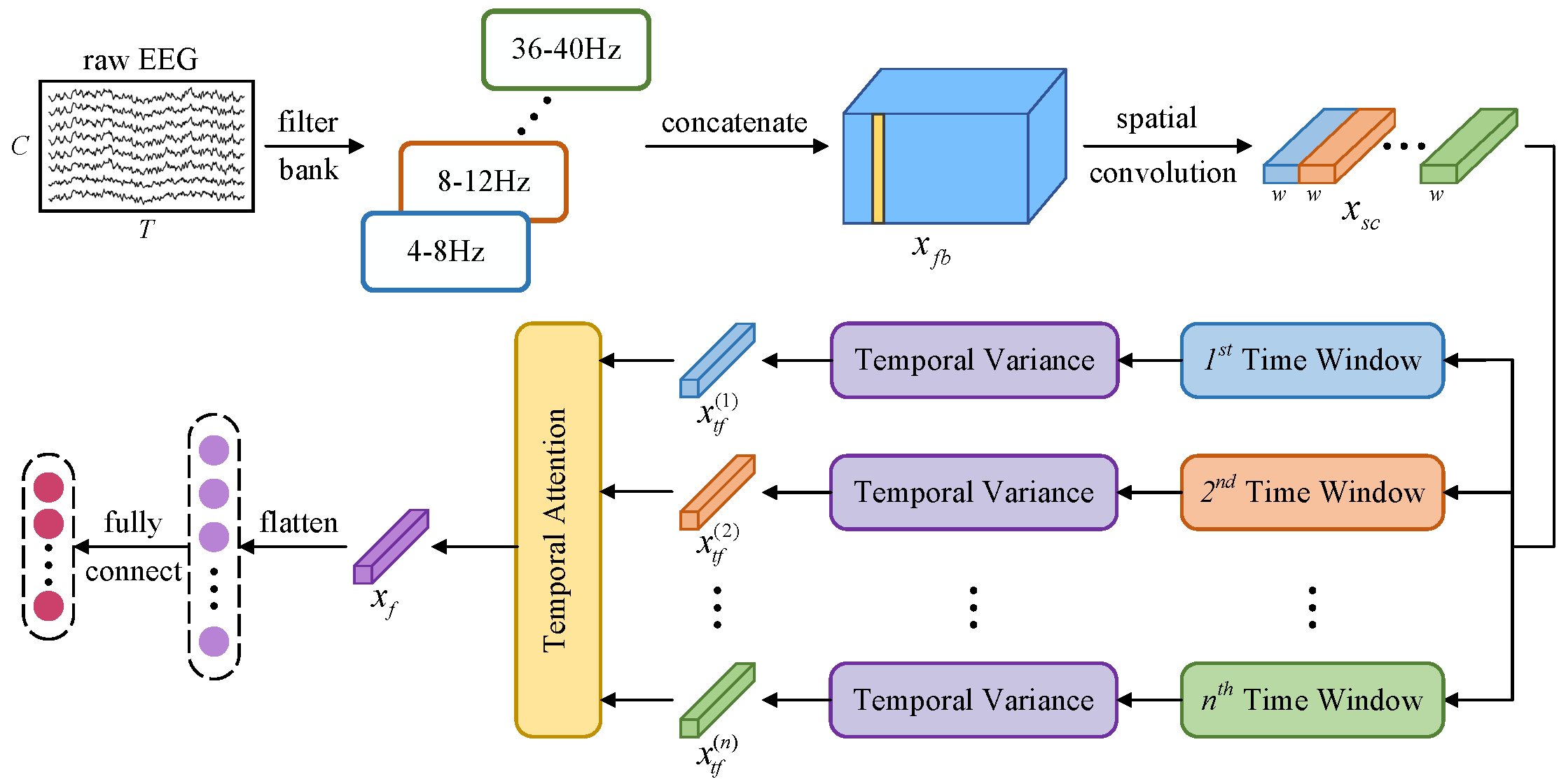
A lightweight convolutional neural network incorporating temporal dependency learning and attention mechanisms. The architecture is designed to efficiently capture spatial and temporal features through specialized convolutional layers and multi-head attention.
The network architecture consists of four main modules:
- Spatial and Spectral Information Learning:
Applies filterbank and spatial convolutions. This module is followed by batch normalization and an activation function to enhance feature representation.
- Temporal Segmentation and Feature Extraction:
Divides the processed data into non-overlapping temporal windows. Within each window, a variance-based layer extracts discriminative features, which are then log-transformed to stabilize variance before being passed to the attention module.
- Temporal Attention Module: Utilizes a multi-head attention
mechanism with depthwise separable convolutions to capture dependencies across different temporal segments. The attention weights are normalized using softmax and aggregated to form a comprehensive temporal representation.
- Final Layer: Flattens the aggregated features and passes them
through a linear layer to with kernel sizes matching the input dimensions to integrate features across different channels generate the final output predictions.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_bands (int or None or list of tuple of int, default=8) – Number of frequency bands or a list of frequency band tuples. If a list of tuples is provided, each tuple defines the lower and upper bounds of a frequency band.
n_filters_spat (
int) – Number of spatial filters in the depthwise convolutional layer.n_dim (
int) – Number of dimensions for the temporal reduction layer.stride_factor (
int) – Stride factor used for reshaping the temporal dimension.win_len (
int) – The description is missing.heads (
int) – Number of attention heads in the multi-head attention mechanism.weight_softmax (
bool) – If True, applies softmax to the attention weights.bias (
bool) – If True, includes a bias term in the convolutional layers.activation (
type[Module]) – Activation function class to apply after convolutional layers.verbose (
bool) – If True, enables verbose output during filter creation using mne.filter_parameters (
Optional[dict]) – Additional parameters for the FilterBankLayer.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct and has not been checked by the original authors; it is a braindecode adaptation from the Pytorch source-code [lightconvnetcode].
References
[lightconvnet]Ma, X., Chen, W., Pei, Z., Liu, J., Huang, B., & Chen, J. (2023). A temporal dependency learning CNN with attention mechanism for MI-EEG decoding. IEEE Transactions on Neural Systems and Rehabilitation Engineering.
[lightconvnetcode]Link to source-code: Ma-Xinzhi/LightConvNet
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import FBLightConvNet # Train your model model = FBLightConvNet(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-fblightconvnet-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import FBLightConvNet # Load pretrained model model = FBLightConvNet.from_pretrained("username/my-fblightconvnet-model") # Load with a different number of outputs (head is rebuilt automatically) model = FBLightConvNet.from_pretrained("username/my-fblightconvnet-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = FBLightConvNet.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods