
braindecode.models.FBMSNet#
- class braindecode.models.FBMSNet(n_chans=None, n_outputs=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, n_bands=9, n_filters_spat=36, temporal_layer='LogVarLayer', n_dim=3, stride_factor=4, dilatability=8, activation=<class 'torch.nn.modules.activation.SiLU'>, kernels_weights=(15, 31, 63, 125), cnn_max_norm=2, linear_max_norm=0.5, verbose=False, filter_parameters=None, return_features=False)[source]#
FBMSNet from Liu et al (2022) [fbmsnet].
Convolution Filterbank
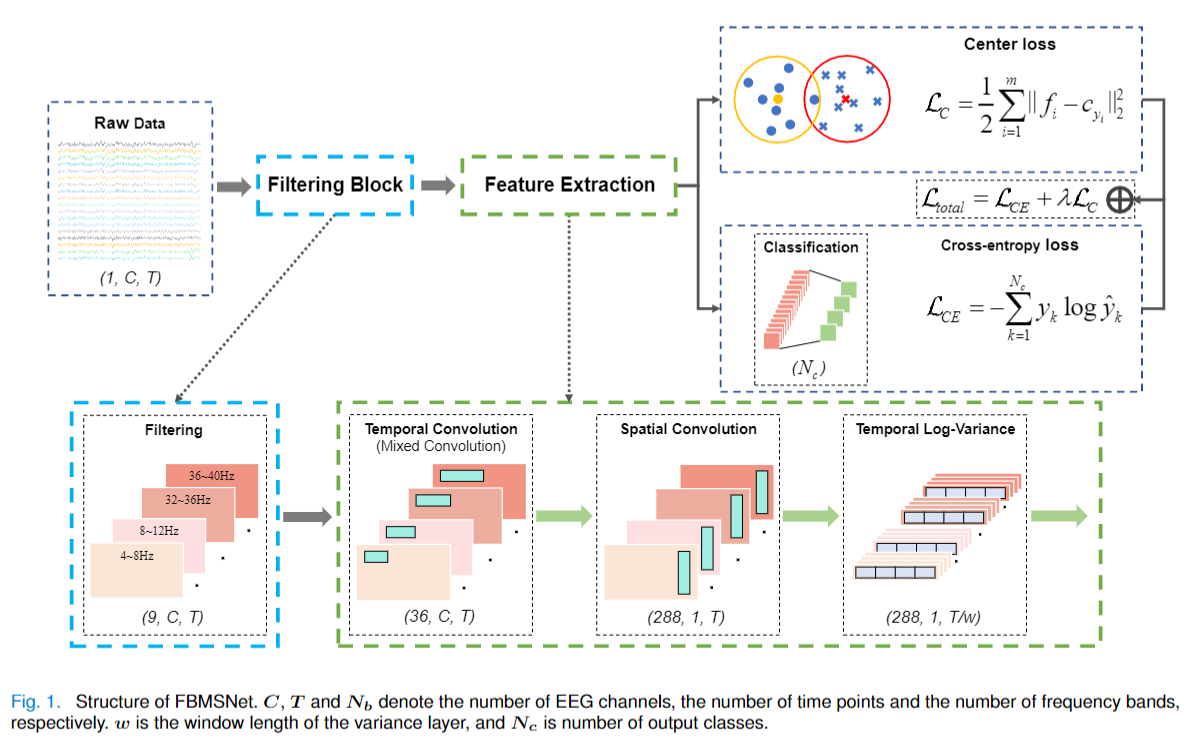
FilterBank Layer: Applying filterbank to transform the input.
Temporal Convolution Block: Utilizes mixed depthwise convolution (MixConv) to extract multiscale temporal features from multiview EEG representations. The input is split into groups corresponding to different views each convolved with kernels of varying sizes. Kernel sizes are set relative to the EEG sampling rate, with ratio coefficients [0.5, 0.25, 0.125, 0.0625], dividing the input into four groups.
Spatial Convolution Block: Applies depthwise convolution with a kernel size of (n_chans, 1) to span all EEG channels, effectively learning spatial filters. This is followed by batch normalization and the Swish activation function. A maximum norm constraint of 2 is imposed on the convolution weights to regularize the model.
Temporal Log-Variance Block: Computes the log-variance.
Classification Layer: A fully connected with weight constraint.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_bands (
int) – Number of input channels (e.g., number of frequency bands).n_filters_spat (
int) – Number of output channels from the MixedConv2d layer.temporal_layer (
str) – Temporal aggregation layer to use.n_dim (
int) – Dimension of the temporal reduction layer.stride_factor (
int) – Stride factor for temporal segmentation.dilatability (
int) – Expansion factor for the spatial convolution block.activation (
type[Module]) – Activation function class to apply.kernels_weights (
Sequence[int]) – Kernel sizes for the MixedConv2d layer.cnn_max_norm (
float) – Maximum norm constraint for the convolutional layers.linear_max_norm (
float) – Maximum norm constraint for the linear layers.verbose (
bool) – Verbose parameter to create the filter using mne.filter_parameters (
dict[Any,Any] |None) – Dictionary of parameters to use for the FilterBankLayer. If None, a default Chebyshev Type II filter with transition bandwidth of 2 Hz and stop-band ripple of 30 dB will be used.return_features (
bool) – If True, the forward method returns the class logits and the flattened features before the final classification layer.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct and has not been checked by the original authors; it has only been reimplemented from the paper description and source code [fbmsnetcode]. There is an extra layer here to compute the filterbank during bash time and not on data time. This avoids data-leak, and allows the model to follow the braindecode convention.
References
[fbmsnet]Liu, K., Yang, M., Yu, Z., Wang, G., & Wu, W. (2022). FBMSNet: A filter-bank multi-scale convolutional neural network for EEG-based motor imagery decoding. IEEE Transactions on Biomedical Engineering, 70(2), 436-445.
[fbmsnetcode]Liu, K., Yang, M., Yu, Z., Wang, G., & Wu, W. (2022). FBMSNet: A filter-bank multi-scale convolutional neural network for EEG-based motor imagery decoding. Want2Vanish/FBMSNet
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import FBMSNet # Train your model model = FBMSNet(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-fbmsnet-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import FBMSNet # Load pretrained model model = FBMSNet.from_pretrained("username/my-fbmsnet-model") # Load with a different number of outputs (head is rebuilt automatically) model = FBMSNet.from_pretrained("username/my-fbmsnet-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = FBMSNet.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(x)[source]#
Forward pass of the FBMSNet model.
- Parameters:
x (torch.Tensor) – Input tensor with shape (batch_size, n_chans, n_times).
- Returns:
Output tensor with shape (batch_size, n_outputs). If
return_featuresis True, a tuple containing the output tensor and flattened features with shape (batch_size, out_channels_spatial * stride_factor) is returned. In TorchScript mode, only the output tensor is returned.- Return type: