
braindecode.models.EEGInceptionERP#
- class braindecode.models.EEGInceptionERP(n_chans=None, n_outputs=None, n_times=1000, sfreq=128, drop_prob=0.5, scales_samples_s=(0.5, 0.25, 0.125), n_filters=8, activation=<class 'torch.nn.modules.activation.ELU'>, batch_norm_alpha=0.01, depth_multiplier=2, pooling_sizes=(4, 2, 2, 2), chs_info=None, input_window_seconds=None)[source]#
EEG Inception for ERP-based from Santamaria-Vazquez et al (2020) [santamaria2020].
Convolution
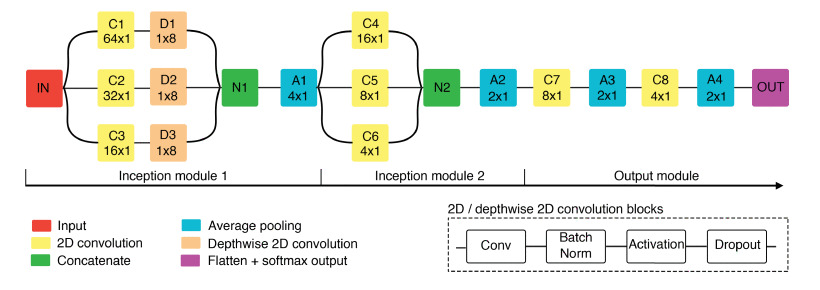
Figure: Overview of EEG-Inception architecture. 2D convolution blocks and depthwise 2D convolution blocks include batch normalization, activation and dropout regularization. The kernel size is displayed for convolutional and average pooling layers.#
Architectural Overview
A two-stage, multi-scale CNN tailored to ERP detection from short (0-1000 ms) single-trial epochs. Signals are mapped through * (i)
_InceptionModule1multi-scale temporal feature extraction plus per-branch spatial mixing; * (ii)_InceptionModule2deeper multi-scale refinement at a reduced temporal resolution; and * (iii)_OutputModulecompact aggregation and linear readout.Macro Components
_InceptionModule1(multi-scale temporal + spatial mixing)Operations.
EEGInceptionERP.c1:
torch.nn.Conv2dk=(64,1), stride(1,1), same pad on input reshaped to(B,1,128,8)→ BN → activation → dropout.EEGInceptionERP.d1:
torch.nn.Conv2d(depthwise)k=(1,8), valid pad over channels → BN → activation → dropout.EEGInceptionERP.c2:
torch.nn.Conv2dk=(32,1)→ BN → activation → dropout; then EEGInceptionERP.d2 depthwisek=(1,8)→ BN → activation → dropout.EEGInceptionERP.c3:
torch.nn.Conv2dk=(16,1)→ BN → activation → dropout; then EEGInceptionERP.d3 depthwisek=(1,8)→ BN → activation → dropout.EEGInceptionERP.n1:
torch.nn.Concatover branch features.EEGInceptionERP.a1:
torch.nn.AvgPool2dpool=(4,1), stride(4,1)for temporal downsampling.
Interpretability/robustness. Depthwise 1 x n_chans layers act as learnable montage-wide spatial filters per temporal scale; pooling stabilizes against jitter.
_InceptionModule2(refinement at coarser timebase)Operations.
EEGInceptionERP.c4:
torch.nn.Conv2dk=(16,1)→ BN → activation → dropout.EEGInceptionERP.c5:
torch.nn.Conv2dk=(8,1)→ BN → activation → dropout.EEGInceptionERP.c6:
torch.nn.Conv2dk=(4,1)→ BN → activation → dropout.EEGInceptionERP.n2:
torch.nn.Concat(merge C4-C6 outputs).EEGInceptionERP.a2:
torch.nn.AvgPool2dpool=(2,1), stride(2,1).EEGInceptionERP.c7:
torch.nn.Conv2dk=(8,1)→ BN → activation → dropout; then EEGInceptionERP.a3:torch.nn.AvgPool2dpool=(2,1).EEGInceptionERP.c8:
torch.nn.Conv2dk=(4,1)→ BN → activation → dropout; then EEGInceptionERP.a4:torch.nn.AvgPool2dpool=(2,1).
Role. Adds higher-level, shorter-window evidence while progressively compressing temporal dimension.
_OutputModule(aggregation + readout)Operations.
torch.nn.Flattentorch.nn.Linear(features → 2)
Convolutional Details
Temporal (where time-domain patterns are learned).
First module uses 1D temporal kernels along the 128-sample axis:
64,32,16(≈500, 250, 125 ms at 128 Hz). Afterpool=(4,1), the second module applies16,8,4(≈125, 62.5, 31.25 ms at the pooled rate). All strides are1in convs; temporal resolution changes only via average pooling.Spatial (how electrodes are processed).
Depthwise convs with
k=(1,8)span all channels and are applied per temporal branch, yielding scale-specific channel projections (no cross-branch mixing until concatenation). There is no full 2D mixing kernel; spatial mixing is factorized and lightweight.Spectral (how frequency information is captured).
No explicit transform; multiple temporal kernels form a learned filter bank over ERP-relevant bands. Successive pooling acts as low-pass integration to emphasize sustained post-stimulus components.
Additional Mechanisms
Every conv/depthwise block includes BatchNorm, nonlinearity (paper used grid-searched activation), and dropout.
Two Inception stages followed by short convs and pooling keep parameters small (≈15k reported) while preserving multi-scale evidence.
Expected input: epochs of shape
(B,1,128,8)(time x channels as a 2D map) or reshaped from(B,8,128)with an added singleton feature dimension.
Usage and Configuration
Key knobs. Number of filters per branch; kernel lengths in both Inception modules; depthwise kernel over channels (typically
n_chans); pooling lengths/strides; dropout rate; choice of activation.Training tips. Use 0-1000 ms windows at 128 Hz with CAR; tune activation and dropout (they strongly affect performance); early-stop on validation loss when overfitting emerges.
Implementation Details
The model is strongly based on the original InceptionNet for an image. The main goal is to extract features in parallel with different scales. The authors extracted three scales proportional to the window sample size. The network had three parts: 1-larger inception block largest, 2-smaller inception block followed by 3-bottleneck for classification.
One advantage of the EEG-Inception block is that it allows a network to learn simultaneous components of low and high frequency associated with the signal. The winners of BEETL Competition/NeurIps 2021 used parts of the model [beetl].
The code for the paper and this model is also available at [santamaria2020] and an adaptation for PyTorch [2].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int, optional) – Size of the input, in number of samples. Set to 128 (1s) as in [santamaria2020].
sfreq (float, optional) – EEG sampling frequency. Defaults to 128 as in [santamaria2020].
drop_prob (float, optional) – Dropout rate inside all the network. Defaults to 0.5 as in [santamaria2020].
scales_samples_s (list(float), optional) – Windows for inception block. Temporal scale (s) of the convolutions on each Inception module. This parameter determines the kernel sizes of the filters. Defaults to 0.5, 0.25, 0.125 seconds, as in [santamaria2020].
n_filters (int, optional) – Initial number of convolutional filters. Defaults to 8 as in [santamaria2020].
activation (
type[Module]) – Activation function. Defaults to ELU activation as in [santamaria2020].batch_norm_alpha (float, optional) – Momentum for BatchNorm2d. Defaults to 0.01.
depth_multiplier (int, optional) – Depth multiplier for the depthwise convolution. Defaults to 2 as in [santamaria2020].
pooling_sizes (list(int), optional) – Pooling sizes for the inception blocks. Defaults to 4, 2, 2 and 2, as in [santamaria2020].
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[santamaria2020] (1,2,3,4,5,6,7,8,9,10)Santamaria-Vazquez, E., Martinez-Cagigal, V., Vaquerizo-Villar, F., & Hornero, R. (2020). EEG-inception: A novel deep convolutional neural network for assistive ERP-based brain-computer interfaces. IEEE Transactions on Neural Systems and Rehabilitation Engineering , v. 28. Online: http://dx.doi.org/10.1109/TNSRE.2020.3048106
[2]Grifcc. Implementation of the EEGInception in torch (2022). Online: Grifcc/EEG
[beetl]Wei, X., Faisal, A.A., Grosse-Wentrup, M., Gramfort, A., Chevallier, S., Jayaram, V., Jeunet, C., Bakas, S., Ludwig, S., Barmpas, K., Bahri, M., Panagakis, Y., Laskaris, N., Adamos, D.A., Zafeiriou, S., Duong, W.C., Gordon, S.M., Lawhern, V.J., Śliwowski, M., Rouanne, V. & Tempczyk, P. (2022). 2021 BEETL Competition: Advancing Transfer Learning for Subject Independence & Heterogeneous EEG Data Sets. Proceedings of the NeurIPS 2021 Competitions and Demonstrations Track, in Proceedings of Machine Learning Research 176:205-219 Available from https://proceedings.mlr.press/v176/wei22a.html.
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import EEGInceptionERP # Train your model model = EEGInceptionERP(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-eeginceptionerp-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import EEGInceptionERP # Load pretrained model model = EEGInceptionERP.from_pretrained("username/my-eeginceptionerp-model") # Load with a different number of outputs (head is rebuilt automatically) model = EEGInceptionERP.from_pretrained("username/my-eeginceptionerp-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = EEGInceptionERP.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.