braindecode.datasets.BaseConcatDataset#
- class braindecode.datasets.BaseConcatDataset(list_of_ds, target_transform=None, *, lazy=False)[source]#
A base class for concatenated datasets.
Holds either mne.Raw or mne.Epoch in self.datasets and has a pandas DataFrame with additional description.
Includes Hugging Face Hub integration via HubDatasetMixin for uploading and downloading datasets.
- Parameters:
list_of_ds (
list[TypeVar(T, bound=RecordDataset)] |list[BaseConcatDataset[TypeVar(T, bound=RecordDataset)]] |list[Union[TypeVar(T, bound=RecordDataset),BaseConcatDataset[TypeVar(T, bound=RecordDataset)]]]) – list of RecordDatasettarget_transform (
Callable|None) – Optional function to call on targets before returning them.lazy (
bool) – If True, defer computing cumulative sizes until length or item access.
Methods
- get_metadata()[source]#
Concatenate the metadata and description of the wrapped Epochs.
- Returns:
metadata – DataFrame containing as many rows as there are windows in the BaseConcatDataset, with the metadata and description information for each window.
- Return type:
DataFrame
- save(path, overwrite=False, offset=0)[source]#
Save datasets to files by creating one subdirectory for each dataset:
path/ 0/ 0-raw.fif | 0-epo.fif description.json raw_preproc_kwargs.json (if raws were preprocessed) window_kwargs.json (if this is a windowed dataset) window_preproc_kwargs.json (if windows were preprocessed) target_name.json (if target_name is not None and dataset is raw) 1/ 1-raw.fif | 1-epo.fif description.json raw_preproc_kwargs.json (if raws were preprocessed) window_kwargs.json (if this is a windowed dataset) window_preproc_kwargs.json (if windows were preprocessed) target_name.json (if target_name is not None and dataset is raw)
- Parameters:
path (
str) –- Directory in which subdirectories are created to store
-raw.fif | -epo.fif and .json files to.
overwrite (
bool) – Whether to delete old subdirectories that will be saved to in this call.offset (
int) – If provided, the integer is added to the id of the dataset in the concat. This is useful in the setting of very large datasets, where one dataset has to be processed and saved at a time to account for its original position.
- set_description(description, overwrite=False)[source]#
Update (add or overwrite) the dataset description.
- set_return_ch_pos(value=True)[source]#
Toggle returning electrode positions from every subdataset.
When enabled, each windowed subdataset’s
__getitem__appends a(n_ch, 3)array of electrode positions (x, y, z), so a batch yields(X, y, crop_inds, ch_pos). Heterogeneous (variable-channel) collections additionally needbraindecode.datasets.pad_channels_collate()as the DataLoadercollate_fn. Default-off: leaves the(X, y, crop_inds)contract untouched.- Parameters:
value (
bool) – Whether to return channel positions (defaultTrue).- Returns:
self
- Return type:
- set_target(column)[source]#
Use
columnas the targetyfor every subdataset.Dispatches on the subdataset type:
For
WindowsDataset/EEGWindowsDataset,columnis looked up in per-windowmetadatafirst, then in the per-recorddescription(broadcast to every window). The resolved values overwriteds.metadata['target']andds.y. ForWindowsDataset, the underlyingds.windows.metadatais kept in sync soget_metadata()and the repr reflect the new target.For
RawDataset,columnmust exist on thedescription.ds.target_nameis set tocolumnso__getitem__readsdescription[column]asyon every access — no rebuild needed.
- Parameters:
column (
Hashable) – Name of a metadata column or description field (BIDS entity, participants.tsv extra, …). Typically a string, but any hashable that pandas accepts as a column label is allowed.- Returns:
self
- Return type:
- Raises:
TypeError – If any subdataset is not a
WindowsDataset,EEGWindowsDataset, orRawDataset, or if a windowed subdataset has lazy (non-DataFrame) metadata.ValueError – If
columnis not present on a subdataset’s metadata or description, or if a windowed subdataset hastargets_from='channels'(which would make this a silent no-op since__getitem__reads y from misc channels, not frommetadata['target']).
- split(by=None, property=None, split_ids=None)[source]#
Split the dataset based on information listed in its description.
The format could be based on a DataFrame or based on indices.
- Parameters:
by (
str|list[int] |list[list[int]] |dict[str,list[int]] |None) – Ifbyis a string, splitting is performed based on the description DataFrame column with this name. Ifbyis a (list of) list of integers, the position in the first list corresponds to the split id and the integers to the datapoints of that split. If a dict then each key will be used in the returned splits dict and each value should be a list of int.Deprecated
Some property which is listed in the info DataFrame.
split_ids (
list[int] |list[list[int]] |dict[str,list[int]] |None) –Deprecated
List of indices to be combined in a subset. It can be a list of int or a list of list of int.
- Returns:
splits – A dictionary with the name of the split (a string) as key and the dataset as value.
- Return type:
- to_epochs_dataset()[source]#
Converts this
BaseConcatDatasetsuch that all datasets areWindowsDatasetwithmne.Epochs.In Braindecode, the data can either be stored as
mne.io.Raw(inEEGWindowsDataset) or asmne.Epochs(inWindowsDataset). This function converts all the underlying datasets toWindowsDatasetwithmne.Epochs. This can be useful for reducing disk space when you want to save a dataset.- Returns:
A new
BaseConcatDatasetwhere all datasets areWindowsDatasetwithmne.Epochs.- Return type:
- Raises:
ValueError – If any of the underlying datasets is a
RawDatasetor any other type that is notEEGWindowsDatasetorWindowsDataset, as they cannot be converted to epochs.
Examples using braindecode.datasets.BaseConcatDataset#
Cleaning EEG Data with EEGPrep for Trialwise Decoding
Loading Pretrained Foundation Models on Arbitrary Channel Sets

Training on recordings with different channels (heterogeneous montages)

Comprehensive Preprocessing with MNE-based Classes
Convolutional neural network regression model on fake data.

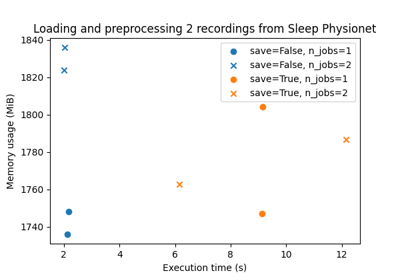
Benchmarking preprocessing with parallelization and serialization


Uploading and downloading datasets to Hugging Face Hub





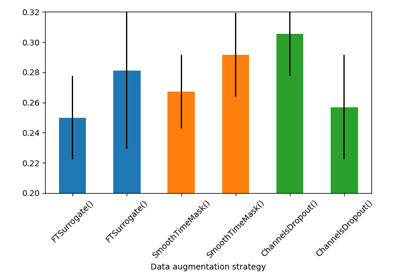
Searching the best data augmentation on BCIC IV 2a Dataset


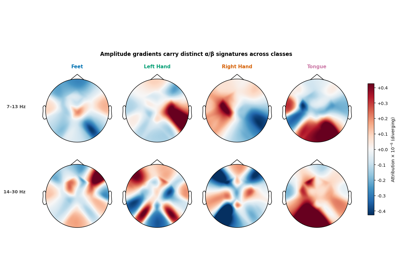
Self-supervised learning on EEG with relative positioning

Sleep staging on the Sleep Physionet dataset using Chambon2018 network

Sleep staging on the Sleep Physionet dataset using Eldele2021
Sleep staging on the Sleep Physionet dataset using U-Sleep network