
braindecode.models.SSTDPN#
- class braindecode.models.SSTDPN(n_chans=None, n_times=None, n_outputs=None, input_window_seconds=None, sfreq=None, chs_info=None, n_spectral_filters_temporal=9, n_fused_filters=48, temporal_conv_kernel_size=75, mvp_kernel_sizes=None, return_features=False, proto_sep_maxnorm=1.0, proto_cpt_std=1.0, spt_attn_global_context_kernel=250, spt_attn_epsilon=1e-05, spt_attn_mode='var', activation=<class 'torch.nn.modules.activation.ELU'>)[source]#
SSTDPN from Can Han et al (2025) [Han2025].
Attention/Transformer Convolution
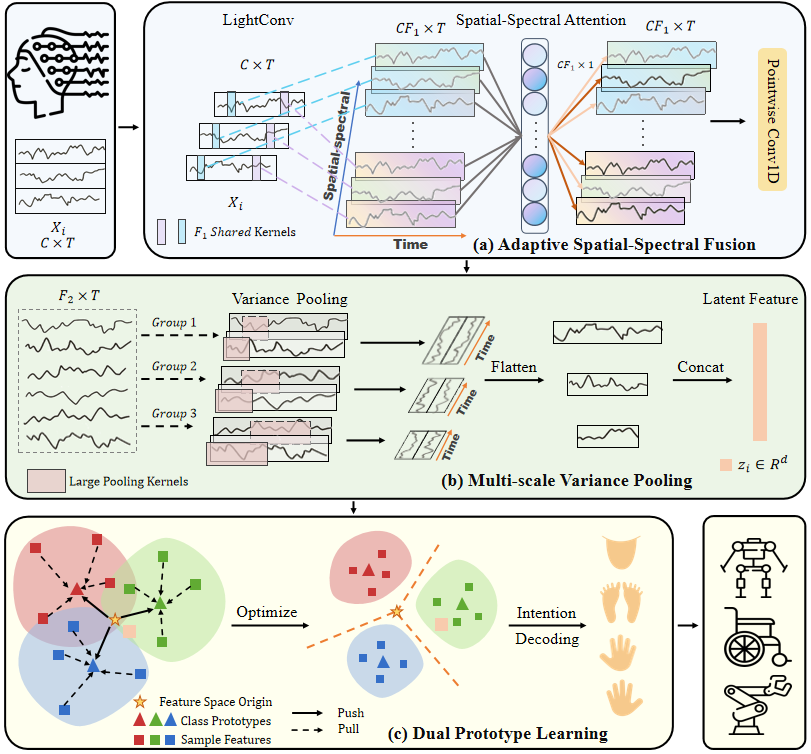
The Spatial-Spectral and Temporal - Dual Prototype Network (SST-DPN) is an end-to-end 1D convolutional architecture designed for motor imagery (MI) EEG decoding, aiming to address challenges related to discriminative feature extraction and small-sample sizes [Han2025].
The framework systematically addresses three key challenges: multi-channel spatial–spectral features and long-term temporal features [Han2025].
Architectural Overview
SST-DPN consists of a feature extractor (_SSTEncoder, comprising Adaptive Spatial-Spectral Fusion and Multi-scale Variance Pooling) followed by Dual Prototype Learning classification [Han2025].
- Adaptive Spatial-Spectral Fusion (ASSF): Uses
_DepthwiseTemporalConv1dto generate a multi-channel spatial-spectral representation, followed by
_SpatSpectralAttn(Spatial-Spectral Attention) to model relationships and highlight key spatial-spectral channels [Han2025].
- Adaptive Spatial-Spectral Fusion (ASSF): Uses
- Multi-scale Variance Pooling (MVP): Applies
_MultiScaleVarPoolerwith variance pooling at multiple temporal scales to capture long-range temporal dependencies, serving as an efficient alternative to transformers [Han2025].
- Multi-scale Variance Pooling (MVP): Applies
- Dual Prototype Learning (DPL): A training strategy that employs two sets of
prototypes—Inter-class Separation Prototypes (proto_sep) and Intra-class Compact Prototypes (proto_cpt)—to optimize the feature space, enhancing generalization ability and preventing overfitting on small datasets [Han2025]. During inference (forward pass), classification decisions are based on the distance (dot product) between the feature vector and proto_sep for each class [Han2025].
Macro Components
SSTDPN.encoder (Feature Extractor)
Operations. Combines Adaptive Spatial-Spectral Fusion and Multi-scale Variance Pooling via an internal
_SSTEncoder.Role. Maps the raw MI-EEG trial \(X_i \in \mathbb{R}^{C \times T}\) to the feature space \(z_i \in \mathbb{R}^d\).
_SSTEncoder.temporal_conv (Depthwise Temporal Convolution for Spectral Extraction)
Operations. Internal
_DepthwiseTemporalConv1dapplying separate temporal convolution filters to each channel with kernel size temporal_conv_kernel_size and depth multiplier n_spectral_filters_temporal (equivalent to \(F_1\) in the paper).Role. Extracts multiple distinct spectral bands from each EEG channel independently.
_SSTEncoder.spt_attn (Spatial-Spectral Attention for Channel Gating)
Operations. Internal
_SpatSpectralAttnmodule using Global Context Embedding via variance-based pooling, followed by adaptive channel normalization and gating.Role. Reweights channels in the spatial-spectral dimension to extract efficient and discriminative features by emphasizing task-relevant regions and frequency bands.
_SSTEncoder.chan_conv (Pointwise Fusion across Channels)
Operations. A 1D pointwise convolution with n_fused_filters output channels (equivalent to \(F_2\) in the paper), followed by BatchNorm and the specified activation function (default: ELU).
Role. Fuses the weighted spatial-spectral features across all electrodes to produce a fused representation \(X_{fused} \in \mathbb{R}^{F_2 \times T}\).
_SSTEncoder.mvp (Multi-scale Variance Pooling for Temporal Extraction)
Operations. Internal
_MultiScaleVarPoolerusing_VariancePool1Dlayers at multiple scales (mvp_kernel_sizes), followed by concatenation.Role. Captures long-range temporal features at multiple time scales. The variance operation leverages the prior that variance represents EEG spectral power.
SSTDPN.proto_sep / SSTDPN.proto_cpt (Dual Prototypes)
Operations. Learnable vectors optimized during training using prototype learning losses. The proto_sep (Inter-class Separation Prototype) is constrained via L2 weight-normalization (\(\lVert s_i \rVert_2 \leq\) proto_sep_maxnorm) during inference.
Role. proto_sep achieves inter-class separation; proto_cpt enhances intra-class compactness.
How the information is encoded temporally, spatially, and spectrally
- Temporal.
The initial
_DepthwiseTemporalConv1duses a large kernel (e.g., 75). The MVP module employs pooling kernels that are much larger (e.g., 50, 100, 200 samples) to capture long-term temporal features effectively. Large kernel pooling layers are shown to be superior to transformer modules for this task in EEG decoding according to [Han2025].
- Spatial.
The initial convolution at the classes
_DepthwiseTemporalConv1dgroups parameter \(h=1\), meaning \(F_1\) temporal filters are shared across channels. The Spatial-Spectral Attention mechanism explicitly models the relationships among these channels in the spatial-spectral dimension, allowing for finer-grained spatial feature modeling compared to conventional GCNs according to the authors [Han2025]. In other words, all electrode channels share \(F_1\) temporal filters independently to produce the spatial-spectral representation.
- Spectral.
Spectral information is implicitly extracted via the \(F_1\) filters in
_DepthwiseTemporalConv1d. Furthermore, the use of Variance Pooling (in MVP) explicitly leverages the neurophysiological prior that the variance of EEG signals represents their spectral power, which is an important feature for distinguishing different MI classes [Han2025].
Additional Mechanisms
- Attention. A lightweight Spatial-Spectral Attention mechanism models spatial-spectral relationships
at the channel level, distinct from applying attention to deep feature dimensions, which is common in comparison methods like
ATCNet.
- Regularization. Dual Prototype Learning acts as a regularization technique
by optimizing the feature space to be compact within classes and separated between classes. This enhances model generalization and classification performance, particularly useful for limited data typical of MI-EEG tasks, without requiring external transfer learning data, according to [Han2025].
- Parameters:
n_chans (int) – Number of EEG channels.
n_times (int) – Number of time samples of the input window.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_spectral_filters_temporal (
int) – Number of spectral filters extracted per channel via temporal convolution. These represent the temporal spectral bands (equivalent to \(F_1\) in the paper). Default is 9.n_fused_filters (
int) – Number of output filters after pointwise fusion convolution. These fuse the spectral filters across all channels (equivalent to \(F_2\) in the paper). Default is 48.temporal_conv_kernel_size (
int) – Kernel size for the temporal convolution layer. Controls the receptive field for extracting spectral information. Default is 75 samples.mvp_kernel_sizes (
Optional[List[int]]) – Kernel sizes for Multi-scale Variance Pooling (MVP) module. Larger kernels capture long-term temporal dependencies .return_features (
bool) – If True, the forward pass returns (features, logits). If False, returns only logits. Default is False.proto_sep_maxnorm (
float) – Maximum L2 norm constraint for Inter-class Separation Prototypes during forward pass. This constraint acts as an implicit force to push features away from the origin. Default is 1.0.proto_cpt_std (
float) –Standard deviation for Intra-class Compactness Prototype initialization. Default is 1.0, matching the source
torch.randninitialization.Changed in version 1.6.1: Default changed from
0.01to1.0to match the original implementation.spt_attn_global_context_kernel (
int) – Kernel size for global context embedding in Spatial-Spectral Attention module. Default is 250 samples.spt_attn_epsilon (
float) – Small epsilon value for numerical stability in Spatial-Spectral Attention. Default is 1e-5.spt_attn_mode (
str) – Embedding computation mode for Spatial-Spectral Attention (‘var’, ‘l2’, or ‘l1’). Default is ‘var’ (variance-based mean-var operation).activation (
type[Module] |None) – Activation function to apply after the pointwise fusion convolution in_SSTEncoder. Should be a PyTorch activation module class. Default is nn.ELU.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
The implementation of the DPL loss functions (\(\mathcal{L}_S\), \(\mathcal{L}_C\), \(\mathcal{L}_{EF}\)) and the optimization of ICPs are typically handled outside the primary
forwardmethod, within the training strategy (see Ref. 52 in [Han2025]).The default parameters are configured based on the BCI Competition IV 2a dataset.
The use of Prototype Learning (PL) methods is novel in the field of EEG-MI decoding.
Lowest FLOPs: Achieves the lowest Floating Point Operations (FLOPs) (9.65 M) among competitive SOTA methods, including braindecode models like
ATCNet(29.81 M) andEEGConformer(63.86 M), demonstrating computational efficiency [Han2025].Transformer Alternative: Multi-scale Variance Pooling (MVP) provides a accuracy improvement over temporal attention transformer modules in ablation studies, offering a more efficient alternative to transformer-based approaches like
EEGConformer[Han2025].
Warning
Important: To utilize the full potential of SSTDPN with Dual Prototype Learning (DPL), users must implement the DPL optimization strategy outside the model’s forward method. For implementation details and training strategies, please consult the official code at [Han2025Code]: hancan16/SST-DPN
References
[Han2025] (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15)Han, C., Liu, C., Wang, J., Wang, Y., Cai, C., & Qian, D. (2025). A spatial–spectral and temporal dual prototype network for motor imagery brain–computer interface. Knowledge-Based Systems, 315, 113315.
[Han2025Code]Han, C., Liu, C., Wang, J., Wang, Y., Cai, C., & Qian, D. (2025). A spatial–spectral and temporal dual prototype network for motor imagery brain–computer interface. Knowledge-Based Systems, 315, 113315. GitHub repository. hancan16/SST-DPN.
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import SSTDPN # Train your model model = SSTDPN(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-sstdpn-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import SSTDPN # Load pretrained model model = SSTDPN.from_pretrained("username/my-sstdpn-model") # Load with a different number of outputs (head is rebuilt automatically) model = SSTDPN.from_pretrained("username/my-sstdpn-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = SSTDPN.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods