
braindecode.models.DeepSleepNet#
- class braindecode.models.DeepSleepNet(n_outputs=5, return_feats=False, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, activation_large=<class 'torch.nn.modules.activation.ELU'>, activation_small=<class 'torch.nn.modules.activation.ReLU'>, drop_prob=0.5, bilstm_hidden_size=512, bilstm_num_layers=2, small_n_filters_1=64, small_n_filters_2=128, small_first_kernel_size=50, small_first_stride=6, small_first_padding=22, small_pool1_kernel_size=8, small_pool1_stride=8, small_pool1_padding=2, small_deep_kernel_size=8, small_pool2_kernel_size=4, small_pool2_stride=4, small_pool2_padding=1, large_n_filters_1=64, large_n_filters_2=128, large_first_kernel_size=400, large_first_stride=50, large_first_padding=175, large_pool1_kernel_size=4, large_pool1_stride=4, large_pool1_padding=0, large_deep_kernel_size=6, large_pool2_kernel_size=2, large_pool2_stride=2, large_pool2_padding=1)[source]#
DeepSleepNet from Supratak et al (2017) [Supratak2017].
Convolution Recurrent
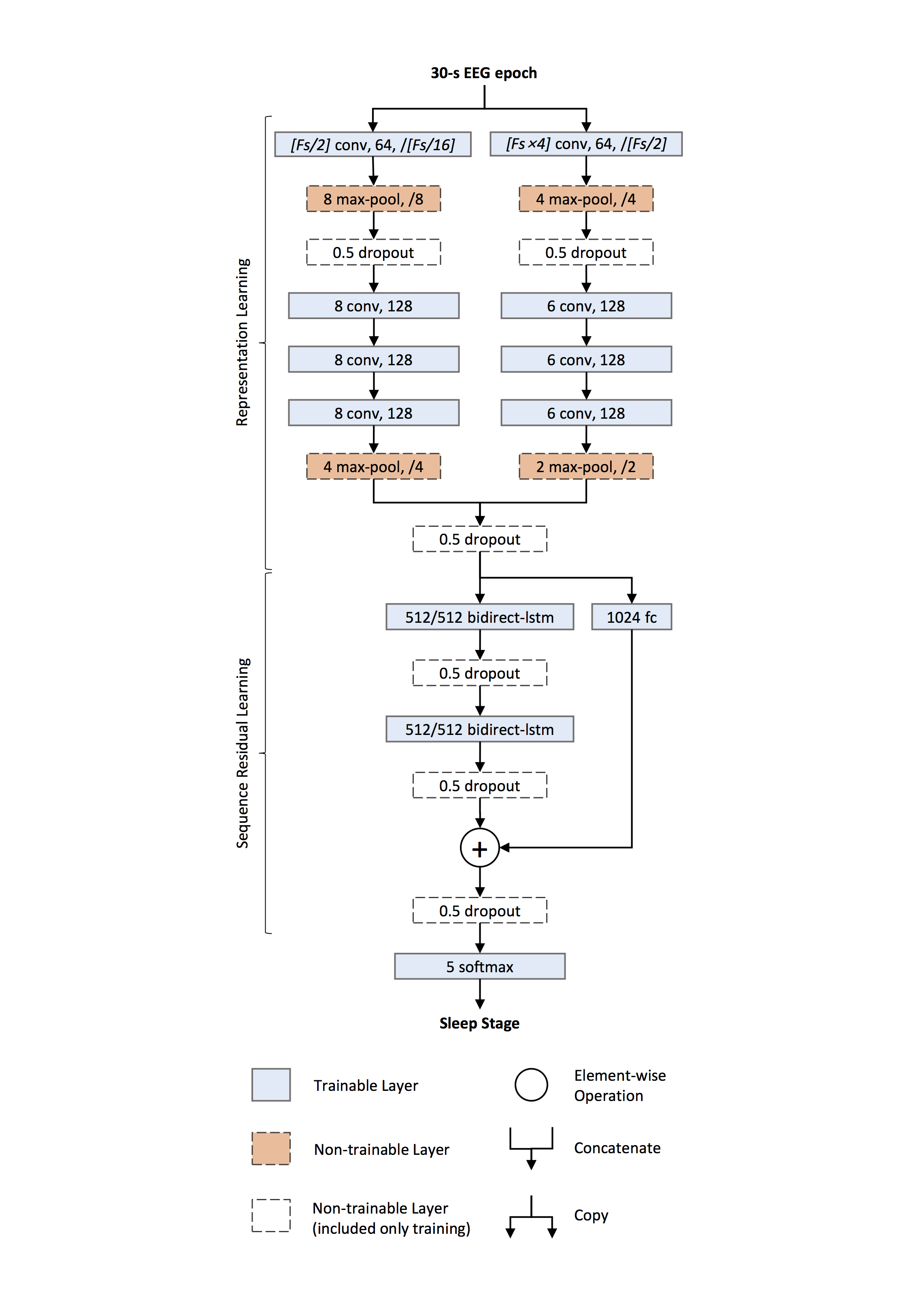
DeepSleepNet is a deep learning model for automatic sleep stage scoring based on raw single-channel EEG. It consists of two main parts:
Representation learning — two CNNs with different filter sizes extract time-invariant features from each 30-s EEG epoch.
Sequence residual learning — bidirectional LSTMs learn temporal information such as stage transition rules, combined with a residual shortcut from the CNN features.
Representation Learning
Two parallel CNN paths process the raw input simultaneously:
Small-filter path — first conv uses filter length ≈ Fs/2 and stride ≈ Fs/16, capturing when characteristic transients occur (temporal precision).
Large-filter path — first conv uses filter length ≈ 4·Fs and stride ≈ Fs/2, capturing which frequency components dominate (frequency precision).
Each path consists of four convolutional layers (1-D convolution →
BatchNorm2d→ activation, configurable via the per-path activation settings) and twoMaxPool2dlayers withDropoutafter the first pooling. Outputs from both paths are concatenated to form the epoch embedding.Sequence Residual Learning
Two layers of bidirectional LSTMs encode temporal dependencies across epochs. A residual shortcut (fully connected →
BatchNorm1d→ReLU) projects the CNN features to the BiLSTM output dimension and is added to the BiLSTM output, improving gradient flow and preserving salient CNN evidence.Implementation Differences
Note
Peephole connections. The original implementation uses TensorFlow
LSTMCellwithuse_peepholes=True, which allows gates to inspect the cell state.torch.nn.LSTMdoes not support peepholes; this implementation uses standard LSTM gates.Sequence length. The original model processes sequences of epochs through the BiLSTM to capture cross-epoch transition rules. This implementation processes single epochs (sequence length 1), so the BiLSTM acts as a nonlinear feature transform with a residual connection. To leverage multi-epoch context, batch consecutive epochs as a sequence externally.
Activation. The original uses
ReLUfor both CNN paths. This implementation defaults toELUfor the large-filter path (activation_large), which can be overridden.Training (from the paper)
Two-step procedure. (i) Pre-train the CNN part on a class-balanced training set using oversampling; (ii) fine-tune the whole network with sequential batches using a lower learning rate for the CNNs and a higher one for the sequence residual part.
Dropout with probability 0.5 is used throughout the model.
L2 weight decay (λ = 10⁻³) is applied only to the first convolutional layers of both CNN paths.
Gradient clipping rescales gradients when their global norm exceeds a threshold.
State handling. BiLSTM states are reinitialized per subject so that temporal context does not leak across recordings.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
return_feats (bool, default=False) – If True, return features before the final linear layer.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
activation_large (
type[Module]) – Activation class for the large-filter CNN path.activation_small (
type[Module]) – Activation class for the small-filter CNN path.drop_prob (
float) – Dropout probability applied throughout the network.bilstm_hidden_size (
int) – Hidden size of the BiLSTM. The residual FC output dimension is2 * bilstm_hidden_sizeto match the concatenated directions.bilstm_num_layers (
int) – Number of stacked BiLSTM layers.small_n_filters_1 (
int) – First-conv output channels for the small-filter path.small_n_filters_2 (
int) – Deep-conv (conv2–conv4) output channels for the small-filter path.small_first_kernel_size (
int) – First-conv kernel size for the small path (paper: Fs/2).small_first_stride (
int) – First-conv stride for the small path (paper: Fs/16).small_first_padding (
int) – First-conv padding for the small path.small_pool1_kernel_size (
int) – First max-pool kernel for the small path.small_pool1_stride (
int) – First max-pool stride for the small path.small_pool1_padding (
int) – First max-pool padding for the small path.small_deep_kernel_size (
int) – Deep-conv kernel size for the small path.small_pool2_kernel_size (
int) – Second max-pool kernel for the small path.small_pool2_stride (
int) – Second max-pool stride for the small path.small_pool2_padding (
int) – Second max-pool padding for the small path.large_n_filters_1 (
int) – First-conv output channels for the large-filter path.large_n_filters_2 (
int) – Deep-conv (conv2–conv4) output channels for the large-filter path.large_first_kernel_size (
int) – First-conv kernel size for the large path (paper: 4*Fs).large_first_stride (
int) – First-conv stride for the large path (paper: Fs/2).large_first_padding (
int) – First-conv padding for the large path.large_pool1_kernel_size (
int) – First max-pool kernel for the large path.large_pool1_stride (
int) – First max-pool stride for the large path.large_pool1_padding (
int) – First max-pool padding for the large path.large_deep_kernel_size (
int) – Deep-conv kernel size for the large path.large_pool2_kernel_size (
int) – Second max-pool kernel for the large path.large_pool2_stride (
int) – Second max-pool stride for the large path.large_pool2_padding (
int) – Second max-pool padding for the large path.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Supratak2017]Supratak, A., Dong, H., Wu, C., & Guo, Y. (2017). DeepSleepNet: A model for automatic sleep stage scoring based on raw single-channel EEG. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 25(11), 1998-2008.
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import DeepSleepNet # Train your model model = DeepSleepNet(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-deepsleepnet-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import DeepSleepNet # Load pretrained model model = DeepSleepNet.from_pretrained("username/my-deepsleepnet-model") # Load with a different number of outputs (head is rebuilt automatically) model = DeepSleepNet.from_pretrained("username/my-deepsleepnet-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = DeepSleepNet.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(x)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
x – The description is missing.