
braindecode.models.CTNet#
- class braindecode.models.CTNet(n_outputs=None, n_chans=None, sfreq=None, chs_info=None, n_times=None, input_window_seconds=None, activation_patch=<class 'torch.nn.modules.activation.ELU'>, activation_transformer=<class 'torch.nn.modules.activation.GELU'>, cnn_drop_prob=0.3, att_positional_drop_prob=0.1, final_drop_prob=0.5, num_heads=4, embed_dim=40, num_layers=6, n_filters_time=None, kernel_size=64, depth_multiplier=2, pool_size_1=8, pool_size_2=8)[source]#
CTNet from Zhao, W et al (2024) [ctnet].
Convolution Attention/Transformer
A Convolutional Transformer Network for EEG-Based Motor Imagery Classification
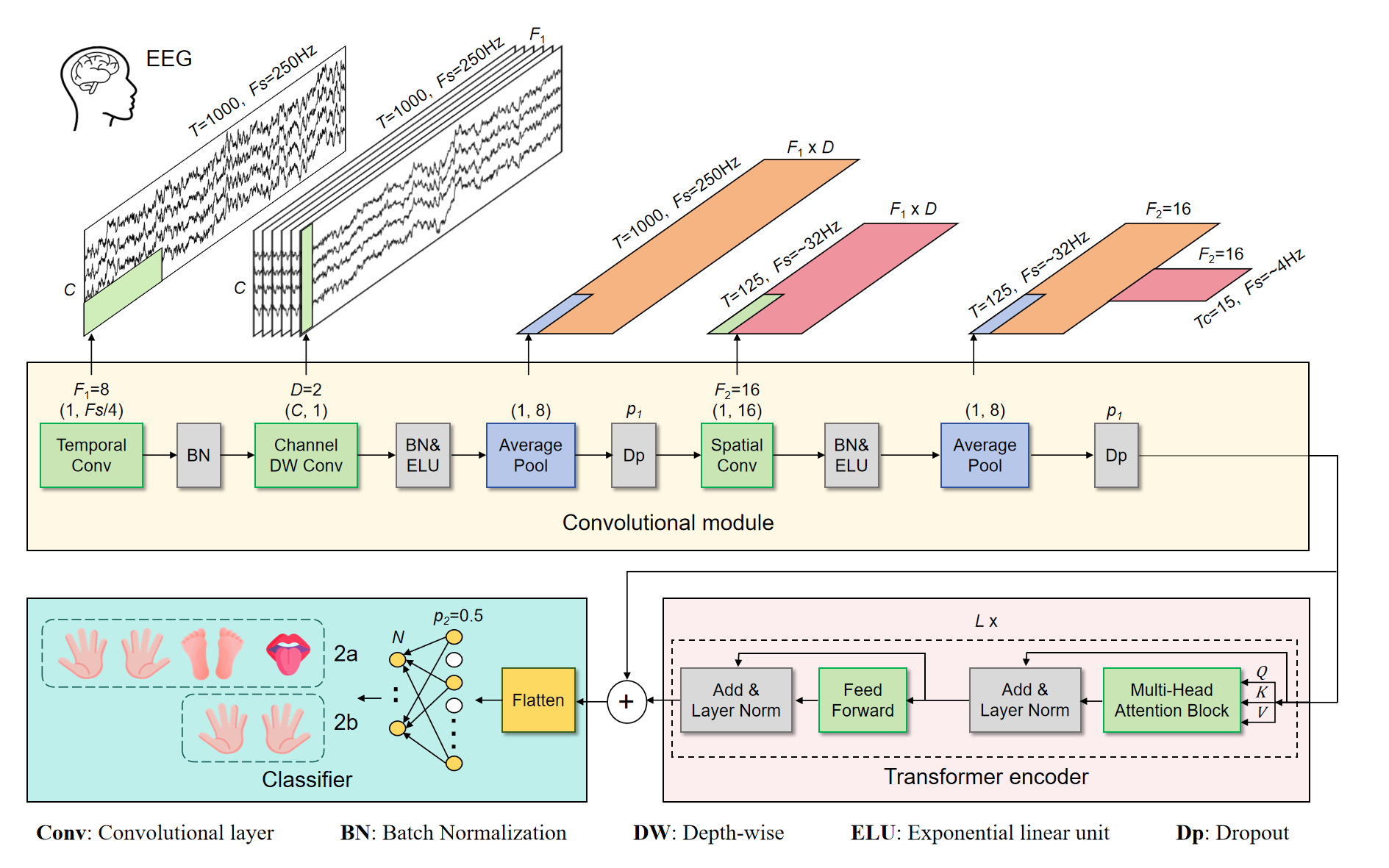
CTNet is an end-to-end neural network architecture designed for classifying motor imagery (MI) tasks from EEG signals. The model combines convolutional neural networks (CNNs) with a Transformer encoder to capture both local and global temporal dependencies in the EEG data.
The architecture consists of three main components:
Convolutional Module:
Apply
EEGNetto perform some feature extraction, denoted here as _PatchEmbeddingEEGNet module.
Transformer Encoder Module:
Utilizes multi-head self-attention mechanisms as EEGConformer but with residual blocks.
Classifier Module:
Combines features from both the convolutional module and the Transformer encoder.
Flattens the combined features and applies dropout for regularization.
Uses a fully connected layer to produce the final classification output.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
sfreq (float) – Sampling frequency of the EEG recordings.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
activation_patch (
type[Module]) – The description is missing.activation_transformer (
type[Module]) – The description is missing.cnn_drop_prob (
float) – The description is missing.att_positional_drop_prob (
float) – Dropout probability for the positional encoding in the Transformer.final_drop_prob (
float) – Dropout probability before the final classification layer.num_heads (
int) – Number of attention heads in the Transformer encoder.embed_dim (
Optional[int]) – Embedding size (dimensionality) for the Transformer encoder.num_layers (
int) – Number of encoder layers in the Transformer.n_filters_time (
Optional[int]) – Number of temporal filters in the first convolutional layer.kernel_size (
int) – Kernel size for the temporal convolutional layer.depth_multiplier (
Optional[int]) – Multiplier for the number of depth-wise convolutional filters.pool_size_1 (
int) – Pooling size for the first average pooling layer.pool_size_2 (
int) – Pooling size for the second average pooling layer. cnn_drop_prob: float, default=0.3 Dropout probability after convolutional layers.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is adapted from the original CTNet source code [ctnetcode] to comply with Braindecode’s model standards.
References
[ctnet]Zhao, W., Jiang, X., Zhang, B., Xiao, S., & Weng, S. (2024). CTNet: a convolutional transformer network for EEG-based motor imagery classification. Scientific Reports, 14(1), 20237.
[ctnetcode]Zhao, W., Jiang, X., Zhang, B., Xiao, S., & Weng, S. (2024). CTNet source code: snailpt/CTNet
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import CTNet # Train your model model = CTNet(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-ctnet-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import CTNet # Load pretrained model model = CTNet.from_pretrained("username/my-ctnet-model") # Load with a different number of outputs (head is rebuilt automatically) model = CTNet.from_pretrained("username/my-ctnet-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = CTNet.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods