
braindecode.models.MSVTNet#
- class braindecode.models.MSVTNet(n_chans=None, n_outputs=None, n_times=None, input_window_seconds=None, sfreq=None, chs_info=None, n_filters_list=(9, 9, 9, 9), conv1_kernels_size=(15, 31, 63, 125), conv2_kernel_size=15, depth_multiplier=2, pool1_size=8, pool2_size=7, drop_prob=0.3, num_heads=8, ffn_expansion_factor=1, att_drop_prob=0.5, num_layers=2, activation=<class 'torch.nn.modules.activation.ELU'>, return_features=False)[source]#
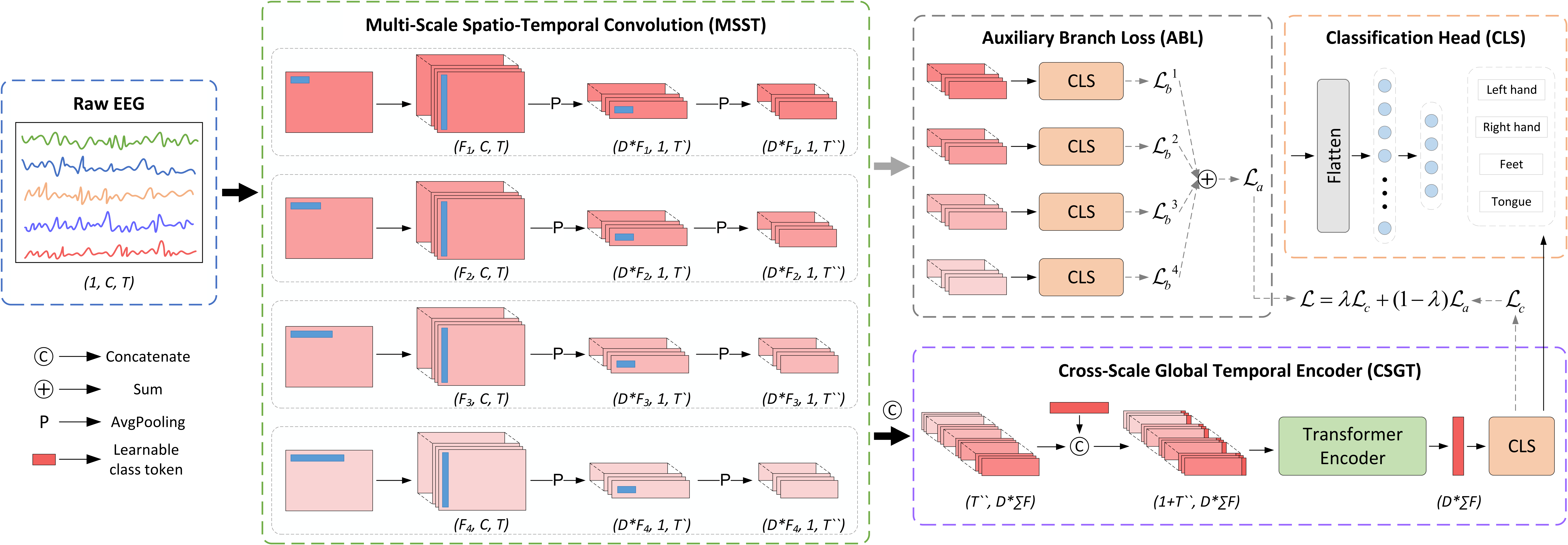
MSVTNet model from Liu K et al (2024) from [msvt2024].
Convolution Recurrent Attention/Transformer
This model implements a multi-scale convolutional transformer network for EEG signal classification, as described in [msvt2024].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_filters_list (
tuple[int,...]) – List of filter numbers for each TSConv block, by default (9, 9, 9, 9).conv1_kernels_size (
tuple[int,...]) – List of kernel sizes for the first convolution in each TSConv block, by default (15, 31, 63, 125).conv2_kernel_size (
int) – Kernel size for the second convolution in TSConv blocks, by default 15.depth_multiplier (
int) – Depth multiplier for depthwise convolution, by default 2.pool1_size (
int) – Pooling size for the first pooling layer in TSConv blocks, by default 8.pool2_size (
int) – Pooling size for the second pooling layer in TSConv blocks, by default 7.drop_prob (
float) – Dropout probability for convolutional layers, by default 0.3.num_heads (
int) – Number of attention heads in the transformer encoder, by default 8.ffn_expansion_factor (
float) – Ratio to compute feedforward dimension in the transformer, by default 1.att_drop_prob (
float) – Dropout probability for the transformer, by default 0.5.num_layers (
int) – Number of transformer encoder layers, by default 2.activation (
Type[Module]) – Activation function class to use, by default nn.ELU.return_features (
bool) – Whether to return predictions from branch classifiers, by default False.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented based on the original code [msvt2024code].
References
[msvt2024] (1,2)Liu, K., et al. (2024). MSVTNet: Multi-Scale Vision Transformer Neural Network for EEG-Based Motor Imagery Decoding. IEEE Journal of Biomedical an Health Informatics.
[msvt2024code]Liu, K., et al. (2024). MSVTNet: Multi-Scale Vision Transformer Neural Network for EEG-Based Motor Imagery Decoding. Source Code: SheepTAO/MSVTNet
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import MSVTNet # Train your model model = MSVTNet(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-msvtnet-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import MSVTNet # Load pretrained model model = MSVTNet.from_pretrained("username/my-msvtnet-model") # Load with a different number of outputs (head is rebuilt automatically) model = MSVTNet.from_pretrained("username/my-msvtnet-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = MSVTNet.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(x)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.