
braindecode.models.MEDFormer#
- class braindecode.models.MEDFormer(n_chans=None, n_outputs=None, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None, patch_len_list=None, embed_dim=128, num_heads=8, drop_prob=0.1, no_inter_attn=False, num_layers=6, dim_feedforward=256, activation_trans=<class 'torch.nn.modules.activation.ReLU'>, single_channel=False, output_attention=True, activation_class=<class 'torch.nn.modules.activation.GELU'>)[source]#
Medformer from Wang et al (2024) [Medformer2024].
Convolution Foundation Model
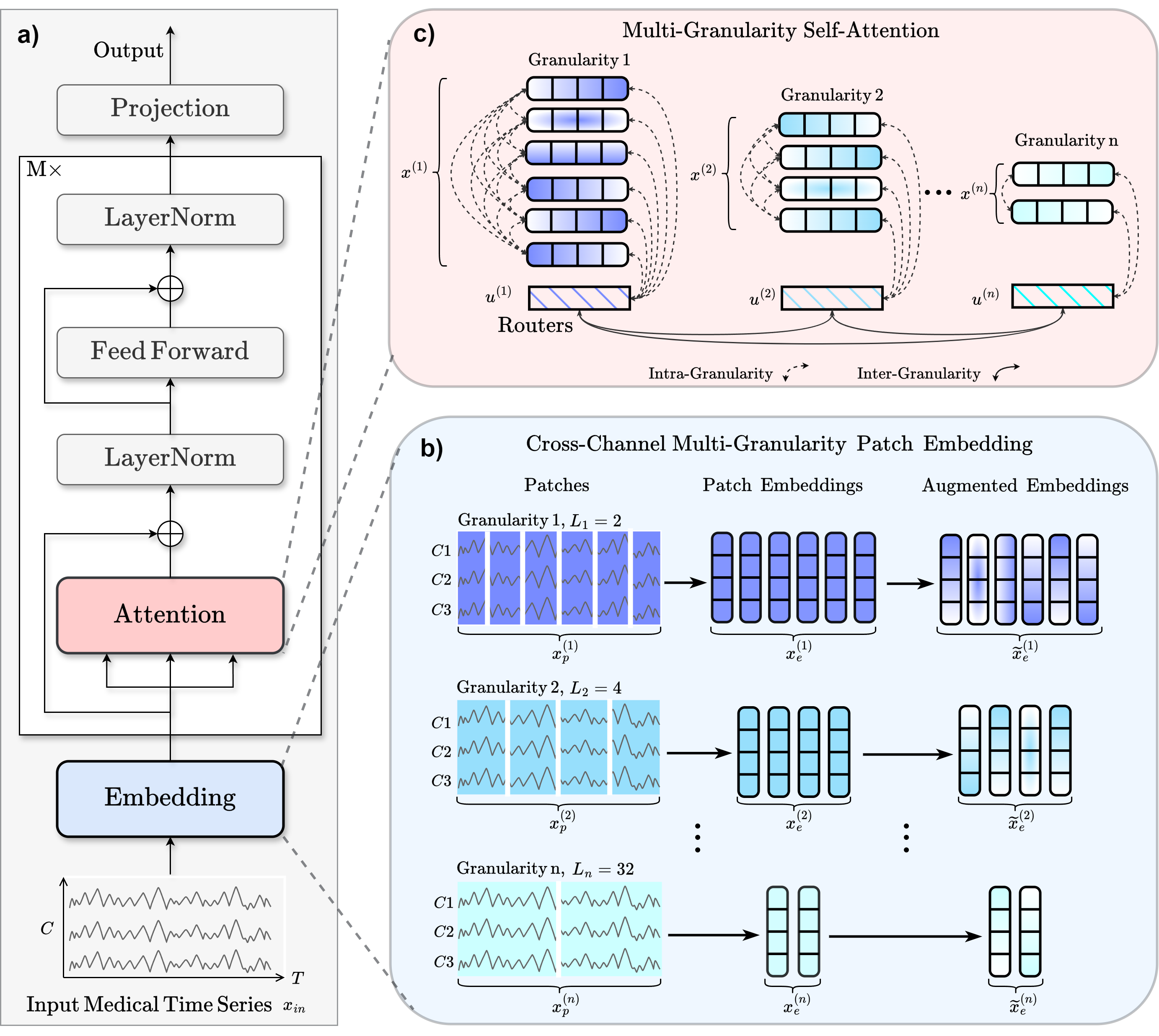
a) Workflow. b) For the input sample \({x}_{\text{in}}\), the authors apply \(n\) different patch lengths in parallel to create patched features \({x}_p^{(i)}\), where \(i\) ranges from 1 to \(n\). Each patch length represents a different granularity. These patched features are linearly transformed into \({x}_e^{(i)}\) and augmented into \(\widetilde{x}_e^{(i)}\). c) The final patch embedding \({x}^{(i)}\) fuses augmented \(\widetilde{x}_e^{(i)}\) with the positional embedding \({W}_{\text{pos}}\) and the granularity embedding \({W}_{\text{gr}}^{(i)}\). Each granularity employs a router \({u}^{(i)}\) to capture aggregated information. Intra-granularity attention focuses within individual granularities, and inter-granularity attention leverages the routers to integrate information across granularities.#
The MedFormer is a multi-granularity patching transformer tailored to medical time-series (MedTS) classification, with an emphasis on EEG and ECG signals. It captures local temporal dynamics, inter-channel correlations, and multi-scale temporal structure through cross-channel patching, multi-granularity embeddings, and two-stage attention [Medformer2024].
Architecture Overview
MedFormer integrates three mechanisms to enhance representation learning [Medformer2024]:
Cross-channel patching. Leverages inter-channel correlations by forming patches across multiple channels and timestamps, capturing multi-timestamp and cross-channel patterns.
Multi-granularity embedding. Extracts features at different temporal scales from
patch_len_list, emulating frequency-band behavior without hand-crafted filters.Two-stage multi-granularity self-attention. Learns intra- and inter-granularity correlations to fuse information across temporal scales.
Macro Components
MEDFormer.enc_embedding(Embedding Layer)Operations.
_ListPatchEmbeddingimplements cross-channel multi-granularity patching. For each patch length \(L_i\), the input \(\mathbf{x}_{\text{in}} \in \mathbb{R}^{T \times C}\) is segmented into \(N_i\) cross-channel non-overlapping patches \(\mathbf{x}_p^{(i)} \in \mathbb{R}^{N_i \times (L_i \cdot C)}\), where \(N_i = \lceil T/L_i \rceil\). Each patch is linearly projected via_CrossChannelTokenEmbeddingto obtain \(\mathbf{x}_e^{(i)} \in \mathbb{R}^{N_i \times D}\). Data augmentations (masking, jittering) produce augmented embeddings \(\tilde{\mathbf{x}}_e^{(i)}\). The final embedding combines augmented patches, fixed positional embeddings (_PositionalEmbedding), and learnable granularity embeddings \(\mathbf{W}_{\text{gr}}^{(i)}\):\[\mathbf{x}^{(i)} = \tilde{\mathbf{x}}_e^{(i)} + \mathbf{W}_{\text{pos}}[1:N_i] + \mathbf{W}_{\text{gr}}^{(i)}\]Additionally, a router token is initialized for each granularity:
\[\mathbf{u}^{(i)} = \mathbf{W}_{\text{pos}}[N_i+1] + \mathbf{W}_{\text{gr}}^{(i)}\]Role. Converts raw input into granularity-specific patch embeddings \(\{\mathbf{x}^{(1)}, \ldots, \mathbf{x}^{(n)}\}\) and router embeddings \(\{\mathbf{u}^{(1)}, \ldots, \mathbf{u}^{(n)}\}\) for multi-scale processing.
MEDFormer.encoder(Transformer Encoder Stack)Operations. A stack of
_EncoderLayermodules, each containing a_MedformerLayerthat implements two-stage self-attention. The two-stage mechanism splits self-attention into:(a) Intra-Granularity Self-Attention. For granularity \(i\), the patch embedding \(\mathbf{x}^{(i)} \in \mathbb{R}^{N_i \times D}\) and router embedding \(\mathbf{u}^{(i)} \in \mathbb{R}^{1 \times D}\) are concatenated:
\[\mathbf{z}^{(i)} = [\mathbf{x}^{(i)} \| \mathbf{u}^{(i)}] \in \mathbb{R}^{(N_i+1) \times D}\]Self-attention is applied to update both embeddings:
\[\begin{split}\mathbf{x}^{(i)} &\leftarrow \text{Attn}_{\text{intra}}(\mathbf{x}^{(i)}, \mathbf{z}^{(i)}, \mathbf{z}^{(i)})\\ \mathbf{u}^{(i)} &\leftarrow \text{Attn}_{\text{intra}}(\mathbf{u}^{(i)}, \mathbf{z}^{(i)}, \mathbf{z}^{(i)})\end{split}\]This captures temporal features within each granularity independently.
(b) Inter-Granularity Self-Attention. All router embeddings are concatenated:
\[\mathbf{U} = [\mathbf{u}^{(1)} \| \mathbf{u}^{(2)} \| \cdots \| \mathbf{u}^{(n)}] \in \mathbb{R}^{n \times D}\]Self-attention among routers exchanges information across granularities:
\[\mathbf{u}^{(i)} \leftarrow \text{Attn}_{\text{inter}}(\mathbf{u}^{(i)}, \mathbf{U}, \mathbf{U})\]Role. Learns representations and correlations within and across temporal scales while reducing complexity from \(O((\sum_i N_i)^2)\) to \(O(\sum_i N_i^2 + n^2)\) through the router mechanism.
Temporal, Spatial, and Spectral Encoding
Temporal: Multiple patch lengths in
patch_len_listcapture features at several temporal granularities, while intra-granularity attention supports long-range temporal dependencies.Spatial: Cross-channel patching embeds inter-channel dependencies by applying kernels that span every input channel.
Spectral: Differing patch lengths simulate multiple sampling frequencies analogous to clinically relevant bands (e.g., alpha, beta, gamma).
Additional Mechanisms
Granularity router: Each granularity \(i\) receives a dedicated router token \(\mathbf{u}^{(i)}\). Intra-attention updates the token, and inter-attention exchanges aggregated information across scales.
Complexity: Router-mediated two-stage attention maintains \(O(T^2)\) complexity for suitable patch lengths (e.g., power series), preserving transformer-like efficiency while modeling multiple granularities.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
patch_len_list (
Optional[List[int]]) – Patch lengths for multi-granularity patching; each entry selects a temporal scale. The default is[14, 44, 45].embed_dim (
int) – Embedding dimensionality. The default is128.num_heads (
int) – Number of attention heads, which must divided_model. The default is8.drop_prob (
float) – Dropout probability. The default is0.1.no_inter_attn (
bool) – IfTrue, disables inter-granularity attention. The default isFalse.num_layers (
int) – Number of encoder layers. The default is6.dim_feedforward (
int) – Feedforward dimensionality. The default is256.activation_trans (
type[Module] |None) – Activation module used in transformer encoder layers. The default isnn.ReLU.single_channel (
bool) – IfTrue, processes each channel independently, increasing capacity and cost. The default isFalse.output_attention (
bool) – IfTrue, returns attention weights for interpretability. The default isTrue.activation_class (
type[Module] |None) – Activation used in the final classification layer. The default isnn.GELU.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
MedFormer outperforms strong baselines across six metrics on five MedTS datasets in a subject-independent evaluation [Medformer2024].
Cross-channel patching provides the largest F1 improvement in ablation studies (average +6.10%), highlighting its importance for MedTS tasks [Medformer2024].
Setting
no_inter_attntoTruedisables inter-granularity attention while retaining intra-granularity attention.
References
[Medformer2024] (1,2,3,4,5)Wang, Y., Huang, N., Li, T., Yan, Y., & Zhang, X. (2024). Medformer: A Multi-Granularity Patching Transformer for Medical Time-Series Classification. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, & C. Zhang (Eds.), Advances in Neural Information Processing Systems (Vol. 37, pp. 36314-36341). doi:10.52202/079017-1145.
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import MEDFormer # Train your model model = MEDFormer(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-medformer-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import MEDFormer # Load pretrained model model = MEDFormer.from_pretrained("username/my-medformer-model") # Load with a different number of outputs (head is rebuilt automatically) model = MEDFormer.from_pretrained("username/my-medformer-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = MEDFormer.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods