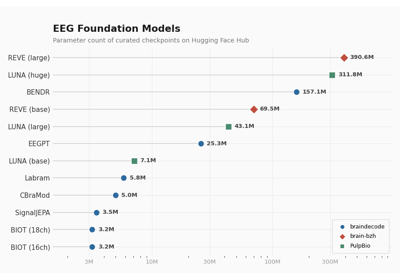
braindecode.models.REVE#
- class braindecode.models.REVE(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, embed_dim=512, depth=22, heads=8, head_dim=64, mlp_dim_ratio=2.66, use_geglu=True, freqs=4, patch_size=200, patch_overlap=20, attention_pooling=False)[source]#
Representation for EEG with Versatile Embeddings (REVE) from El Ouahidi et al. (2025) [reve].
Foundation Model Attention/Transformer
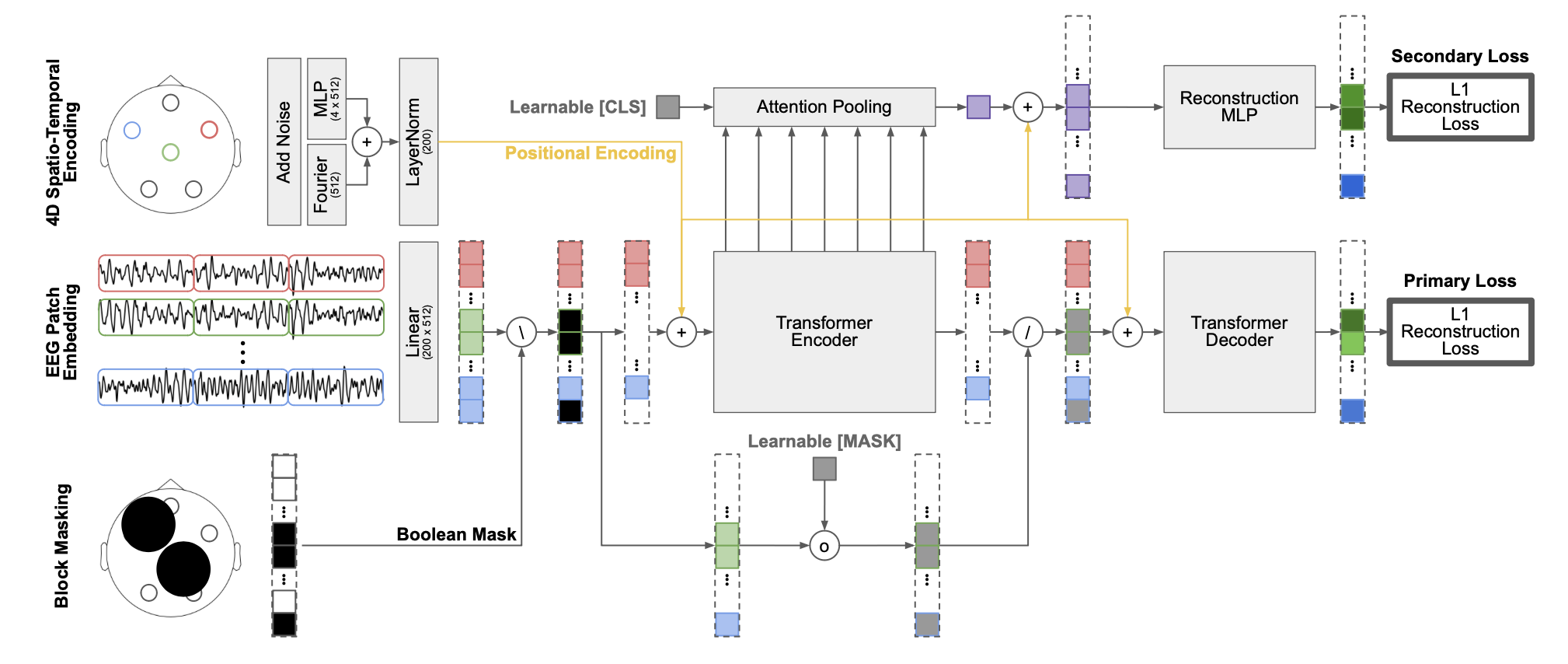
Foundation models have transformed machine learning by reducing reliance on task-specific data and induced biases through large-scale pretraining. While successful in language and vision, their adoption in EEG has lagged due to the heterogeneity of public datasets, which are collected under varying protocols, devices, and electrode configurations. Existing EEG foundation models struggle to generalize across these variations, often restricting pretraining to a single setup and resulting in suboptimal performance, particularly under linear probing.
REVE is a pretrained model explicitly designed to generalize across diverse EEG signals. It introduces a 4D positional encoding scheme that enables processing signals of arbitrary length and electrode arrangement. Using a masked autoencoding objective, REVE was pretrained on over 60,000 hours of EEG data from 92 datasets spanning 25,000 subjects, the largest EEG pretraining effort to date.
Channels Invariant Positional Encoding
Prior EEG foundation models (
Labram,BIOT) rely on fixed positional embeddings, making direct transfer to unseen electrode layouts infeasible. CBraMod uses convolution-based positional encoding that requires fine-tuning when adapting to new configurations. As noted in the CBraMod paper: “fixing the pre-trained parameters during training on downstream datasets will lead to a very large performance decline.”REVE’s 4D positional encoding jointly encodes spatial \((x, y, z)\) and temporal \((t)\) positions using Fourier embeddings, enabling true cross-configuration transfer without retraining. The fourier embedding have inspiration on brainmodule [brainmodule], generalized to 4D for EEG with the channel spatial coordinates and temporal patch index.
Linear Probing Performance
A key advantage of REVE is producing useful latent representation without heavy fine-tuning. Under linear probing (frozen encoder), REVE achieves state-of-the-art results on downstream EEG tasks. This enables practical deployment in low-data scenarios where extensive fine-tuning is not feasible.
Architecture
The model adopts modern Transformer components validated through ablation studies:
Normalization: RMSNorm outperforms LayerNorm;
Activation: GEGLU outperforms GELU;
Attention: Flash Attention via PyTorch’s SDPA;
Masking ratio: 55% optimal for spatio-temporal block masking
These choices align with best practices from large language models and were empirically validated on EEG data.
Secondary Loss
A secondary reconstruction objective using attention pooling across layers prevents over-specialization in the final layer. This pooling acts as an information bottleneck, forcing the model to distill key information from the entire sequence. Ablations show this loss is crucial for linear probing quality: removing it drops average performance in 10% under the frozen evaluation.
Macro Components
REVE.to_patch_embeddingPatch TokenizationThe EEG signal is split into overlapping patches along the time dimension, generating \(p = \left\lceil \frac{T - w}{w - o} \right\rceil + \mathbf{1}[(T - w) \bmod (w - o) \neq 0]\) patches of size \(w\) with overlap \(o\), where \(T\) is the signal length. Each patch is linearly projected to the embedding dimension.
REVE.fourier4d+REVE.mlp4d4D Positional Embedding (4DPE)The 4DPE encodes each token’s 4D coordinates \((x, y, z, t)\) where \((x, y, z)\) are the 3D spatial coordinates from a standardized electrode position bank, and \(t\) is the temporal patch index. The encoding combines:
Fourier embedding: Sinusoidal encoding across multiple frequencies for smooth interpolation to unseen positions
MLP embedding:
Linear(4 → embed_dim) →GELU→LayerNormfor learnable refinement
Both components are summed and normalized. The 4DPE adds negligible computational overhead, scaling linearly with the number of tokens.
REVE.transformerTransformer EncoderPre-LayerNorm Transformer with multi-head self-attention (
RMSNorm), feed-forward networks (GEGLU activation), and residual connections. Default configuration: 22 layers, 8 heads, 512 embedding dimension (~72M parameters).REVE.final_layerClassification HeadTwo modes (controlled by the
attention_poolingparameter):
Known Limitations
Sparse electrode setups: Performance degrades with very few channels. On motor imagery, accuracy drops from 0.824 (64 channels) to 0.660 (1 channel). For tasks requiring broad spatial coverage (e.g., imagined speech), performance with <4 channels approaches chance level.
Demographic bias: The pretraining corpus aggregates publicly available datasets, most originating from North America and Europe, resulting in limited demographic diversity, more details about the datasets used for pretraining can be found in the REVE paper [reve].
Pretrained Weights
Weights are available on HuggingFace, but you must agree to the data usage terms before downloading:
brain-bzh/reve-base: 72M parameters, 512 embedding dim, 22 layers (~260 A100 GPU hours)brain-bzh/reve-large: ~400M parameters, 1250 embedding dim
Important
Pre-trained Weights Available (Registration Required)
This model has pre-trained weights available on the Hugging Face Hub. You must first register and agree to the data usage terms on the authors’ HuggingFace repository before you can access the weights. Link here.
You can load them using:
from braindecode.models import REVE # Load pre-trained model from Hugging Face Hub model = REVE.from_pretrained("brain-bzh/reve-base")
To push your own trained model to the Hub:
# After training your model model.push_to_hub( repo_id="username/my-reve-model", commit_message="Upload trained REVE model" )
Requires installing
braindecode[hug]for Hub integration.Usage
from braindecode.models import REVE model = REVE( n_outputs=4, # e.g., 4-class motor imagery n_chans=22, n_times=1000, # 5 seconds at 200 Hz sfreq=200, chs_info=[{"ch_name": "C3"}, {"ch_name": "C4"}, ...], ) # Forward pass: (batch, n_chans, n_times) -> (batch, n_outputs) output = model(eeg_data, pos=channel_positions)
Warning
Input data must be sampled at 200 Hz to match pretraining. The model applies z-score normalization followed by clipping at 15 standard deviations internally during pretraining-users should apply similar preprocessing.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
embed_dim (
int) – Embedding dimension. Use 512 for REVE-Base, 1250 for REVE-Large.depth (
int) – Number of Transformer layers.heads (
int) – Number of attention heads.head_dim (
int) – Dimension per attention head.mlp_dim_ratio (
float) – FFN hidden dimension ratio:mlp_dim = embed_dim × mlp_dim_ratio.use_geglu (
bool) – Use GEGLU activation (recommended) or standard GELU.freqs (
int) – Number of frequencies for Fourier positional embedding.patch_size (
int) – Temporal patch size in samples (200 samples = 1 second at 200 Hz).patch_overlap (
int) – Overlap between patches in samples.attention_pooling (
bool) – Pooling strategy for aggregating transformer outputs before classification. IfFalse(default), all tokens are flattened into a single vector of size(n_chans x n_patches x embed_dim), which is then passed through LayerNorm and a linear classifier. IfTrue, uses attention-based pooling with a learnable query token that attends to all encoder outputs, producing a single embedding of sizeembed_dim. Attention pooling is more parameter-efficient for long sequences and variable-length inputs.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
The position bank is downloaded from HuggingFace on first initialization, mapping standard 10-20/10-10/10-05 electrode names to 3D coordinates. This enables the 4D positional encoding to generalize across electrode configurations without requiring matched layouts between pretraining and downstream tasks.
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import REVE # Train your model model = REVE(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-reve-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import REVE # Load pretrained model model = REVE.from_pretrained("username/my-reve-model") # Load with a different number of outputs (head is rebuilt automatically) model = REVE.from_pretrained("username/my-reve-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = REVE.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
References
[reve] (1,2)El Ouahidi, Y., Lys, J., Thölke, P., Farrugia, N., Pasdeloup, B., Gripon, V., Jerbi, K. & Lioi, G. (2025). REVE: A Foundation Model for EEG - Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects. The Thirty-Ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=ZeFMtRBy4Z
[brainmodule]Défossez, A., Caucheteux, C., Rapin, J., Kabeli, O., & King, J. R. (2023). Decoding speech perception from non-invasive brain recordings. Nature Machine Intelligence, 5(10), 1097-1107.
Methods
- forward(eeg, pos=None, return_output=False, return_features=False)[source]#
Forward pass of the model.
Goes through the following steps: 1. Patch extraction from the EEG signal. 2. 4D positional embedding computation. 3. Transformer encoding. 4. Final layer processing (if return_output is False).
- Parameters:
eeg (
Tensor) – Input EEG tensor of shape (batch_size, channels, sequence_length).pos (
Optional[Tensor]) – Position tensor of shape (batch_size, channels, 3) representing (x, y, z) coordinates.return_output (
bool) – If True, returns the output from the transformer directly. If False, applies the final layer and returns the processed output. Default is False.return_features (
bool) – If True, returns a dict{"features": Tensor, "cls_token": None}with encoder features before the final layer. Default is False.
- Returns:
Default:
torch.Tensorafter the final layer. Ifreturn_output=True:list[torch.Tensor]from transformer layers. Ifreturn_features=True:dictwith"features"and"cls_token"keys.- Return type:
- get_positions(channel_names)[source]#
Fetch channel positions from the position bank. The position bank is downloaded when the model is instantiated.
- reset_head(n_outputs)[source]#
Replace the classification head for a new number of outputs.
This is called automatically by
from_pretrained()when the user passes ann_outputsthat differs from the saved config. Override in subclasses that need a model-specific head structure.- Parameters:
n_outputs (int) – New number of output classes.
Examples
>>> from braindecode.models import BENDR >>> model = BENDR(n_chans=22, n_times=1000, n_outputs=4) >>> model.reset_head(10) >>> model.n_outputs 10
Added in version 1.4.