braindecode.models.CodeBrain#
- class braindecode.models.CodeBrain(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, patch_size=200, res_channels=200, skip_channels=200, out_channels=200, num_res_layers=8, drop_prob=0.1, s4_bidirectional=True, s4_layernorm=False, s4_lmax=570, s4_d_state=64, conv_out_chans=25, conv_groups=5, proj_kernel_size=49, proj_padding=24, proj_refine_kernel=3, pos_kernel=(19, 7), spectral_dropout=0.1, mlp_hidden_multiplier=4, swa_window_size=1, codebook_size_t=4096, codebook_size_f=4096, pretrain_mode=False, activation=<class 'torch.nn.modules.activation.ReLU'>)[source]#
CodeBrain: Scalable Code EEG Pre-Training for Unified Downstream BCI Tasks.
Foundation Model Attention/Transformer
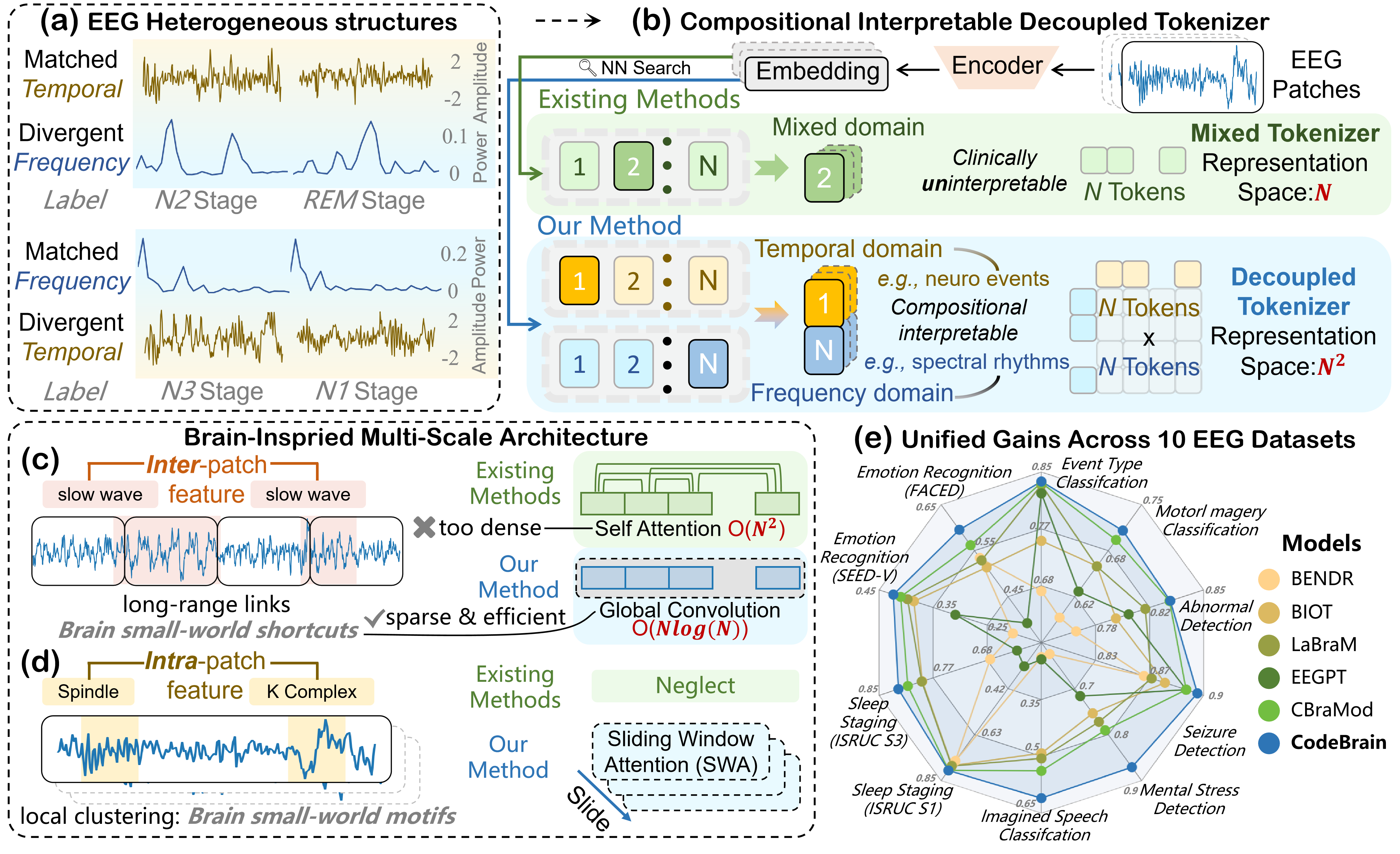
CodeBrain is a foundation model for EEG that pre-trains on large unlabelled corpora using a two-stage vector-quantised masking strategy, then fine-tunes on downstream BCI tasks. It segments EEG signals into fixed-size patches, embeds them with convolutional and spectral projections, and processes them through stacked residual blocks that combine a multi-scale convolutional structured state-space model (
_GConv) with sliding-window self-attention.Stage 2: EEGSSM Backbone (this implementation)
This class implements Stage 2 of CodeBrain — the EEGSSM backbone described in Section 3.3 of [codebrain]. Following
Labram, CodeBrain discretises EEG patches into codebook tokens via VQ-VAE (Stage 1, not implemented here), then trains the backbone to predict masked token indices via cross-entropy. CodeBrain extends this with a dual tokenizer that decouples temporal and frequency representations, as stated in the paper: “the TFDual-Tokenizer, which decouples heterogeneous temporal and frequency EEG signals into discrete tokens to enhance discriminative power.”Macro Components
PatchEmbedding: Splits
(batch, n_chans, n_times)into(batch, n_chans, seq_len, patch_size)patches, projects each patch with a 2-D convolutional stack, adds FFT-based spectral embeddings, and applies depth-wise convolutional positional encoding.Residual blocks (
ResidualGroup): Each block applies RMSNorm, a_GConvSSM layer, and sliding-window multi-head attention, with gated activation and separate residual/skip paths.Classification head (
final_layer): Flattens the output and maps ton_outputsclasses.
Important
Pre-trained Weights Available
This model has pre-trained weights available on the Hugging Face Hub. You can load them using:
from braindecode.models import CodeBrain # Load pre-trained model from Hugging Face Hub model = CodeBrain.from_pretrained("braindecode/codebrain-pretrained")
To push your own trained model to the Hub:
model.push_to_hub("my-username/my-codebrain")
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
patch_size (
int) – Number of time samples per patch. Input length is trimmed to the nearest multiple ofpatch_size.res_channels (
int) – Width of the residual stream inside eachResidualBlock.skip_channels (
int) – Width of the skip-connection stream aggregated across blocks.out_channels (
int) – Output channels offinal_convbefore the classification head.num_res_layers (
int) – Number of stackedResidualBlockmodules.drop_prob (
float) – Dropout rate used inside the_GConvSSM and attention layers.s4_bidirectional (
bool) – Whether the_GConvSSM processes the sequence bidirectionally.s4_layernorm (
bool) – Whether to apply layer normalisation inside the_GConvSSM. Set toFalseto match the released pretrained checkpoint.s4_lmax (
int) – Maximum sequence length for the_GConvSSM kernel. Also determines the patch embedding dimension ass4_lmax // n_chans.s4_d_state (
int) – State dimension of the_GConvSSM.conv_out_chans (
int) – Number of output channels in the patch projection convolutions.conv_groups (
int) – Number of groups forGroupNormin the patch projection.proj_kernel_size (
int) – The description is missing.proj_padding (
int) – The description is missing.proj_refine_kernel (
int) – The description is missing.pos_kernel (
tuple) – The description is missing.spectral_dropout (
float) – The description is missing.mlp_hidden_multiplier (
int) – The description is missing.swa_window_size (
int) – The description is missing.codebook_size_t (
int) – The description is missing.codebook_size_f (
int) – The description is missing.pretrain_mode (
bool) – The description is missing.activation (
type[Module]) – Non-linear activation class used ininit_convandfinal_conv.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[codebrain]Yi Ding, Xuyang Chen, Yong Li, Rui Yan, Tao Wang, Le Wu (2025). CodeBrain: Scalable Code EEG Pre-Training for Unified Downstream BCI Tasks. https://arxiv.org/abs/2506.09110
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import CodeBrain # Train your model model = CodeBrain(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-codebrain-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import CodeBrain # Load pretrained model model = CodeBrain.from_pretrained("username/my-codebrain-model") # Load with a different number of outputs (head is rebuilt automatically) model = CodeBrain.from_pretrained("username/my-codebrain-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = CodeBrain.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(inputs, mask=None, return_features=False)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
inputs – The description is missing.
mask – The description is missing.
return_features – The description is missing.
- load_state_dict(state_dict, *args, **kwargs)[source]#
Remap upstream checkpoint keys to braindecode attribute names.
Handles four kinds of key differences from the original CodeBrain checkpoint (
YjMajy/CodeBrainon HuggingFace):module.prefix fromDataParallelsaving.Attribute renames:
S41->sgconv,sn->rms_norm,.D->.skip_weight.KernelModulewrapper:.kernel_list.N.kernel->.kernel_list.N.Old
weight_normAPI:weight_g/weight_v->parametrizations.weight.original0/original1.
- Parameters:
state_dict – The description is missing.
*args – The description is missing.
**kwargs – The description is missing.