
braindecode.models.MetaNeuromotorHand#
- class braindecode.models.MetaNeuromotorHand(n_outputs=100, n_chans=16, sfreq=2000.0, mpf_window_length=160, mpf_stride=40, mpf_n_fft=64, mpf_fft_stride=10, mpf_frequency_bins=((0.0, 50.0), (30.0, 100.0), (100.0, 225.0), (225.0, 375.0), (375.0, 700.0), (700.0, 1000.0)), mask_max_num_masks=(3, 2), mask_max_lengths=(5, 1), mask_dims='TF', mask_value=0.0, invariance_hidden_dims=(64, ), invariance_offsets=(-1, 0, 1), num_adjacent_cov=8, conformer_input_dim=64, conformer_ffn_dim=128, conformer_kernel_size=8, conformer_stride=(1, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1), conformer_num_heads=4, conformer_attn_window_size=(16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 8, 8, 8, 8, 8), conformer_num_layers=15, drop_prob=0.1, time_reduction_stride=2, log_softmax=False, activation=<class 'torch.nn.modules.activation.SiLU'>, invariance_activation=<class 'torch.nn.modules.activation.LeakyReLU'>, n_times=None, input_window_seconds=None, chs_info=None)[source]#
Generic neuromotor interface for handwriting from Meta (2025) [gni2025].
Attention/Transformer Convolution
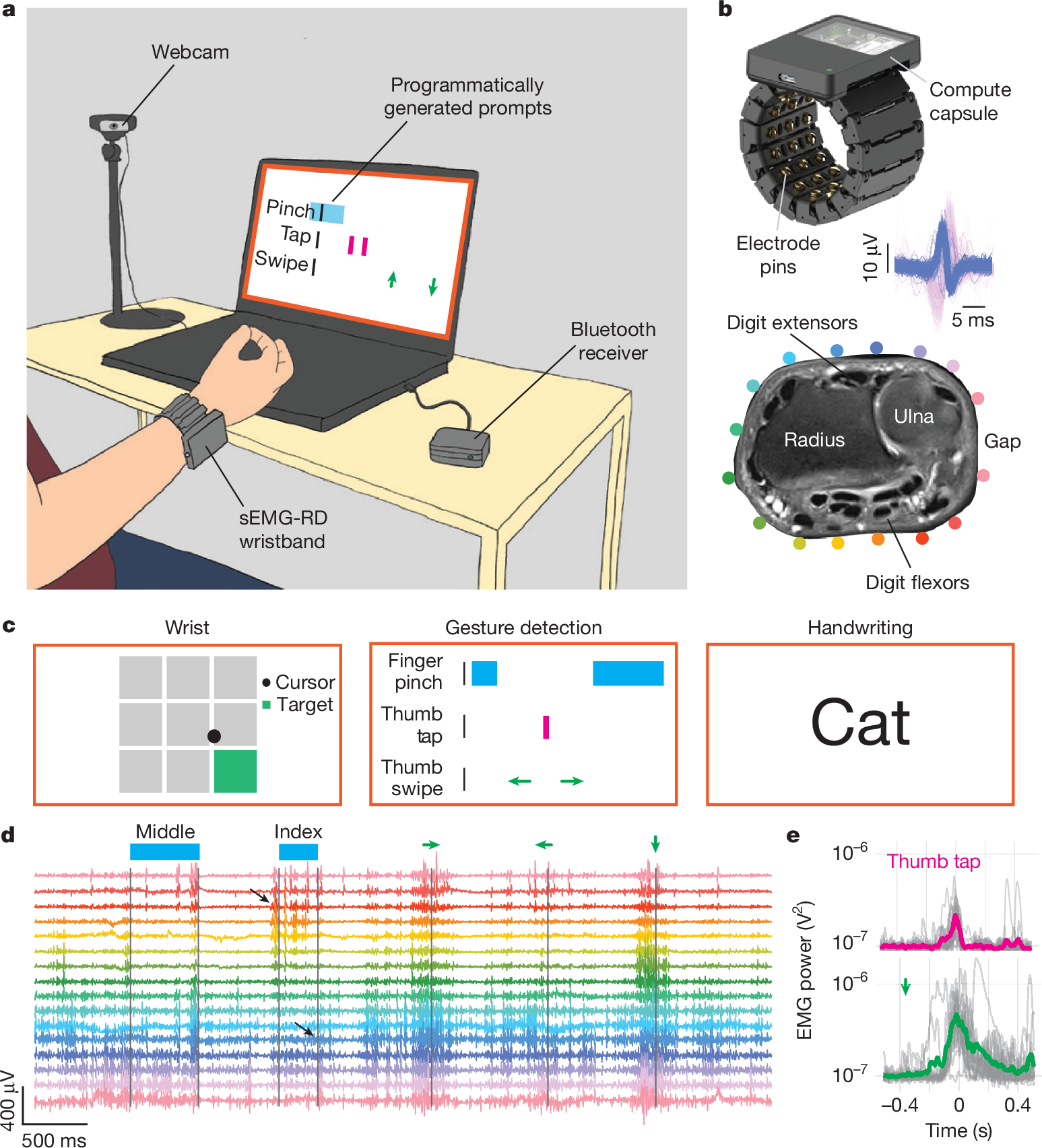
Figure 1 from the paper [gni2025] - “A hardware and software platform for high-throughput recording and real-time decoding of sEMG at the wrist.” Shows the 16-channel sEMG-RD wristband, the three tasks (handwriting, gestures, wrist control) and the per-task decoding pipeline at a block level.#
Conformer-based surface-EMG-to-character decoder for the handwriting task of Meta’s generic neuromotor interface (CTRL-labs at Reality Labs, Nature 2025). Takes raw 16-channel surface EMG recorded at the wrist and emits a per-token score sequence for CTC decoding [graves2006ctc]. The upstream repository (facebookresearch/generic-neuromotor-interface) ships one architecture per task: 1-DOF wrist control, discrete gestures and handwriting. Only the handwriting head is ported here.
Macro Components
The forward pass is a strict sequence of five modules, in order:
_MultivariatePowerFrequencyFeatures(MPF features, fixed signal-processing stage, no trainable parameters).Channel-wise STFT (
torch.stft()) –n_fft=64(32 ms), hop10(5 ms), Hann window.Strided windowing of consecutive STFT bins into
mpf_window_length(80 ms) windows sliding everympf_stride(20 ms).Per-pair cross-spectral density across channels, squared magnitude.
Frequency-band averaging over 6 bands (0-50, 30-100, 100-225, 225-375, 375-700, 700-1000 Hz).
SPD matrix logarithm via eigendecomposition (Barachant et al. 2012; [pyriemann]).
Output shape
(batch, num_freq_bins, n_chans, n_chans, time')at 50 Hz (=sfreq / mpf_stride)._MaskAug– SpecAugment [park2019specaug] on the MPF features during training, no-op at eval. Zero parameters. Hyperparametersmask_max_num_masks=(3, 2)andmask_max_lengths=(5, 1)match the released checkpoints._RotationInvariantMPFMLP– armband-rotation invariance.Circular roll of the 16-channel cross-spectral matrix by each offset in
invariance_offsets(default{-1, 0, +1}).Vectorize upper triangle keeping only
num_adjacent_covoff-diagonals (assumes circular adjacency of the armband).Shared MLP applied to each rotated vector.
Mean-pool across rotations – enforces approximate invariance to rigid rotations of the armband around the wrist.
Output shape
(batch, hidden_dim, time')withhidden_dim = 64by default.Causal conformer encoder [gulati2020conformer].
Block structure: FF(half) -> windowed causal multi-head attention -> depthwise convolution -> FF(half) ->
torch.nn.LayerNorm.Depth: 15 blocks. The paper’s schedule has stride
2at blocks 5 and 10 (total 4x temporal downsampling) and attention window16for blocks 1-10 then8for blocks 11-15.Causality: attention is restricted to a fixed local window ending at the current frame, so the encoder runs as a streaming causal decoder. A frame-stacking step before the stack halves the frame rate once more.
torch.nn.Linearclassification head, optionally followed bytorch.nn.functional.log_softmax(). The final linear projects ton_outputs(vocabulary size, default100). Log-softmax is gated bylog_softmax; disabled by default since braindecode models conventionally return logits.
Hardware, signal and training corpus
The upstream sEMG-RD research wristband has 48 electrode pins arranged as 16 bipolar channels aligned with the proximal-distal forearm axis, a 2 kHz sample rate, a ~2.46 uVrms noise floor, and an analog front-end with a 20 Hz high-pass and 850 Hz low-pass. Before featurization the raw signal is rescaled by
2.46e-6(to unit noise s.d.) and digitally high-passed at 40 Hz (4th-order Butterworth) to suppress motion artifacts.The published handwriting decoder was trained on recordings from ~6,627 participants (~1 h 15 min each) prompted to “write” text sampled from Simple English Wikipedia, the Google Schema-guided Dialogue dataset and Reddit, in three postures (seated on surface, seated on leg, standing on leg). Participants wrote letters, digits, words and phrases; spaces were either implicit or prompted by a right-dash token produced via a right-index swipe. Training sizes scale geometrically from 25 to 6,527 participants; validation and test sets hold 50 participants each.
MPF featurizer (paper defaults)
sEMG (2 kHz)->STFT(n_fft=64 samples / 32 ms, hop=10 samples / 5 ms)-> per-pair complex cross-spectrum -> squared magnitude, band-averaged into 6 bins, then matrix-log on each 16x16 SPD matrix, produced everympf_stride = 40 samples (20 ms)over ampf_window_length = 160 samples (80 ms)window. Output rate: 50 Hz before the conformer’stime_reduction_strideand the 2x internal strides.The paper’s frequency bins are non-overlapping (0-62.5, 62.5-125, 125-250, 250-375, 375-687.5, 687.5-1000 Hz), but the upstream training config – matched by the
mpf_frequency_binsdefault – uses slightly overlapping bins (0-50, 30-100, 100-225, 225-375, 375-700, 700-1000 Hz); the code default reproduces the released checkpoints.Training recipe (paper values, not defaults of this class)
Loss: CTC [graves2006ctc] with FastEmit regularization [fastemit2021] to reduce streaming latency.
Vocabulary: lowercase
[a-z], digits[0-9], punctuation[,.?'!]and four control gestures (space,dash,backspace,pinch); the deployed networks usedvocab_size = 100(the default) to reserve blank / unused slots. Greedy CTC decoding (collapse repeats) was used at test.Optimizer: AdamW,
weight_decay = 5e-2.Learning rate: cosine annealing from
6e-4(1 M-parameter model) or3e-4(60 M) with a 1,500-step warmup andmin_lr = 0.Batching: global batch size 512 (= 32 processes x 16), prompts zero-padded to the longest in the batch; gradient clipping at norm
0.1; 200 epochs. Training the largest model took ~4 d 17 h on 4 x NVIDIA A10G GPUs.Augmentation: SpecAugment on the MPF features (time and frequency masks;
mask_max_num_masks=(3, 2),mask_max_lengths=(5, 1)) plus random circular channel rotations of{-1, 0, +1}.
Reported closed-loop performance:
20.9 WPMon held-out naive users (n = 20), compared with25.1 WPMon a pen-and-paper baseline and36 WPMon a mobile keyboard; personalization with 20 min of data improves offline CER by ~16 %.Output shape and CTC usage
The forward pass returns a tensor of shape
(batch, T_out, n_outputs), the natural layout for CTC.T_outis the downsampled emission sequence length and can be obtained from the input length viacompute_output_lengths(). Fortorch.nn.CTCLoss, move the time dimension first:emissions.transpose(0, 1).Warning
The rotation-invariant MLP assumes circular channel adjacency (the 16-electrode EMG armband used in the paper). For arbitrary EEG montages the rotation invariance is not meaningful and this model should not be used as-is.
Warning
License – noncommercial use only. This module is a derivative of Meta’s reference implementation and is released under CC BY-NC 4.0, the same license as the upstream repository. The paper itself is distributed under CC BY-NC-ND 4.0. Neither is covered by braindecode’s BSD-3 license, and both must not be used in commercial products or services. Using the pretrained weights carries the same restriction.
Added in version 1.5.
- Parameters:
n_outputs (
int) – Vocabulary size for CTC. Defaults to100(handwriting charset).n_chans (
int) – Number of EMG channels. Defaults to16(one armband).sfreq (
float) – Sampling frequency in Hz. Defaults to2000.mpf_window_length (
int) – MPF window length in samples.mpf_stride (
int) – MPF frame stride in samples.mpf_n_fft (
int) – STFT window / FFT size.mpf_fft_stride (
int) – STFT hop size. Must dividempf_strideand be<= mpf_n_fft.mpf_frequency_bins (
Sequence[Sequence[float]] |None) –(low, high)Hz bands to average the cross-spectrum over. IfNone, all FFT frequency bins are used.mask_max_num_masks (
Sequence[int]) – Max number of SpecAugment masks per dim (order matchesmask_dims).mask_max_lengths (
Sequence[int]) – Max mask length per dim (order matchesmask_dims).mask_dims (
str) – Axes to mask, among"CFT". Defaults to"TF".mask_value (
float) – Filler value for masked regions.invariance_hidden_dims (
Sequence[int]) – Hidden layer sizes of the per-rotation MLP. Output feature dim isinvariance_hidden_dims[-1].invariance_offsets (
Sequence[int]) – Circular channel rotations to average over.num_adjacent_cov (
int) – Number of adjacent off-diagonals of the cross-channel covariance matrix to keep.conformer_input_dim (
int) – Conformer embedding dimensionD.conformer_ffn_dim (
int) – Feed-forward hidden dim inside each block.conformer_kernel_size (
int|Sequence[int]) – Depthwise-conv kernel size per block.conformer_stride (
int|Sequence[int]) – Depthwise-conv stride per block. As a scalar, applied only to the last block (entire encoder downsamples bystride); as a sequence of lengthconformer_num_layers, applied per block. Defaults to the paper’s 15-layer schedule(1, 1, 1, 1, 2) * 2 + (1,) * 5(2x downsampling at blocks 5 and 10). When overridingconformer_num_layers, also pass a matching schedule or a scalar.conformer_num_heads (
int) – Number of attention heads.conformer_attn_window_size (
int|Sequence[int]) – Attention receptive field per block. Defaults to the paper’s 15-layer schedule(16,) * 10 + (8,) * 5. When overridingconformer_num_layers, also pass a matching schedule or a scalar.conformer_num_layers (
int) – Number of conformer blocks.drop_prob (
float) – Dropout probability applied throughout the conformer (FFN, conv and attention blocks).time_reduction_stride (
int) – Frame-stacking stride applied before the conformer.1disables it.log_softmax (
bool) – IfTrue, applytorch.nn.functional.log_softmax()to the emissions. Disabled by default (braindecode models return logits).activation (
type[Module]) – Activation class used inside the conformer feed-forward and convolution blocks. Defaults totorch.nn.SiLU.invariance_activation (
type[Module]) – Activation class used inside the rotation-invariant MLP. Defaults totorch.nn.LeakyReLU.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
Examples
Load Meta’s pretrained handwriting checkpoint (download script in the upstream repo):
import torch from braindecode.models import MetaNeuromotorHand ckpt = torch.load("model_checkpoint.ckpt", weights_only=False) sd = { k[len("network."):]: v for k, v in ckpt["state_dict"].items() if k.startswith("network.") } model = MetaNeuromotorHand(n_times=32000, log_softmax=True) # load_state_dict applies the class-level ``mapping`` for # upstream keys. model.load_state_dict(sd, strict=True)
References
[gni2025] (1,2)CTRL-labs at Reality Labs (Kaifosh, P., Reardon, T. R. et al.), 2025. A generic non-invasive neuromotor interface for human-computer interaction. Nature 645, 702-710. https://doi.org/10.1038/s41586-025-09255-w
[gulati2020conformer]Gulati, A. et al., 2020. Conformer: convolution-augmented transformer for speech recognition. Proc. Interspeech, 5036-5040.
[graves2006ctc] (1,2)Graves, A., Fernandez, S., Gomez, F., Schmidhuber, J., 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. Proc. ICML, 369-376.
[park2019specaug]Park, D. S. et al., 2019. SpecAugment: a simple data augmentation method for automatic speech recognition. Proc. Interspeech, 2613-2617.
[fastemit2021]Yu, J. et al., 2021. FastEmit: low-latency streaming ASR with sequence-level emission regularization. Proc. ICASSP.
[pyriemann]Barachant, A., Barthelemy, Q., King, J.-R., Gramfort, A., Chevallier, S., Rodrigues, P. L. C., … Aristimunha, B., 2026. pyRiemann (v0.10). Zenodo. https://doi.org/10.5281/zenodo.593816
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import MetaNeuromotorHand # Train your model model = MetaNeuromotorHand(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-metaneuromotorhand-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import MetaNeuromotorHand # Load pretrained model model = MetaNeuromotorHand.from_pretrained("username/my-metaneuromotorhand-model") # Load with a different number of outputs (head is rebuilt automatically) model = MetaNeuromotorHand.from_pretrained("username/my-metaneuromotorhand-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = MetaNeuromotorHand.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- compute_output_lengths(input_lengths)[source]#
Compute the valid emission length for each input sequence.
This is the length that should be passed to
CTCLossasinput_lengths.
- get_output_shape()[source]#
Shape of
forwardoutput for a batch of size 1.Overrides the base implementation to explicitly construct an input with the requested
n_times(the default dummy may be too short for the MPF featurizer’s left-context window).