braindecode.models.CBraMod#
- class braindecode.models.CBraMod(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, patch_size=200, dim_feedforward=800, n_layer=12, nhead=8, activation=<class 'torch.nn.modules.activation.GELU'>, emb_dim=200, channels_kernel_stride_padding_norm=((25, 49, 25, 24, (5, 25)), (25, 3, 1, 1, (5, 25)), (25, 3, 1, 1, (5, 25))), drop_prob=0.1, return_encoder_output=False)[source]#
Criss-Cross Brain Model for EEG Decoding from Wang et al. (2025) [cbramod].
Foundation Model Attention/Transformer
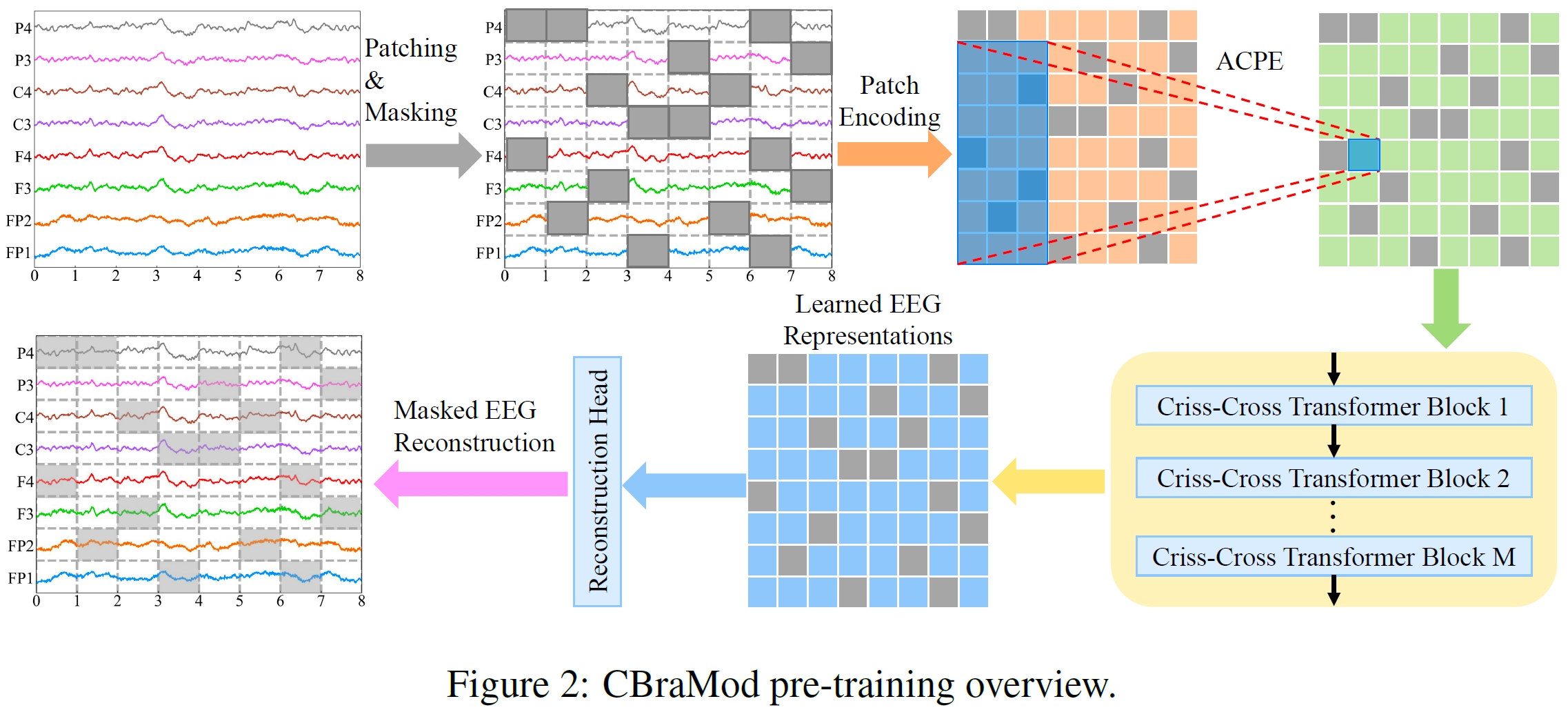
CBraMod is a foundation model for EEG decoding that leverages a novel criss-cross transformer architecture to effectively model the unique spatial and temporal characteristics of EEG signals. Pre-trained on the Temple University Hospital EEG Corpus (TUEG)—the largest public EEG corpus— using masked EEG patch reconstruction, CBraMod achieves state-of-the-art performance across diverse downstream BCI and clinical applications.
Key Innovation: Criss-Cross Attention
Unlike existing EEG foundation models that use full attention to model all spatial and temporal dependencies together, CBraMod separates spatial and temporal dependencies through a criss-cross transformer architecture:
Spatial Attention: Models dependencies between channels while keeping patches separate
Temporal Attention: Models dependencies between temporal patches while keeping channels separate
This design is inspired by criss-cross strategies from computer vision and effectively leverages the inherent structural characteristics of EEG signals. The criss-cross approach reduces computational complexity (FLOPs reduced by ~32% compared to full attention) while improving performance and enabling faster convergence.
Asymmetric Conditional Positional Encoding (ACPE)
Rather than using fixed positional embeddings, CBraMod employs Asymmetric Conditional Positional Encoding that dynamically generates positional embeddings using a convolutional network. This enables the model to:
Capture relative positional information adaptively
Handle diverse EEG channel formats (different channel counts and reference schemes)
Generalize to arbitrary downstream EEG formats without retraining
Support various reference schemes (earlobe, average, REST, bipolar)
Pretraining Highlights
Pretraining Dataset: Temple University Hospital EEG Corpus (TUEG), the largest public EEG corpus
Pretraining Task: Self-supervised masked EEG patch reconstruction from both time-domain and frequency-domain EEG signals
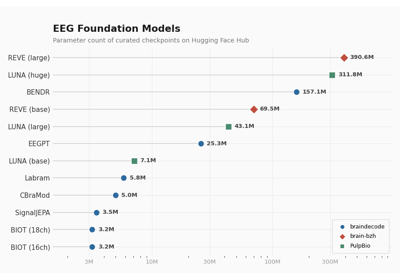
Model Parameters: ~4.0M parameters (very compact compared to other foundation models)
Fast Convergence: Achieves decent results in first epoch on downstream tasks, full convergence within ~10 epochs (vs. ~30 for supervised models like EEGConformer)
Macro Components
Patch Encoding Network: Converts raw EEG patches into embeddings
Asymmetric Conditional Positional Encoding (ACPE): Generates spatial-temporal positional embeddings adaptively from input EEG format
Criss-Cross Transformer Blocks (12 layers): Alternates spatial and temporal attention to learn EEG representations
Reconstruction Head: Reconstructs masked EEG patches during pretraining
- Task head (
final_layer): flatten summary tokens across patches and map to n_outputs; ifreturn_encoder_output=True, return the encoder features instead.
- Task head (
The model is highly efficient, requiring only ~318.9M FLOPs on a typical 16-channel, 10-second EEG recording (significantly lower than full attention baselines).
Known Limitations
Data Quality: TUEG corpus contains “dirty data”; pretraining used crude filtering, reducing available pre-training data
Channel Dependency: Performance degrades with very sparse electrode setups (e.g., <4 channels)
Computational Resources: While efficient, foundation models have higher deployment requirements than lightweight models
Limited Scaling Exploration: Future work should explore scaling laws at billion-parameter levels and integration with large pre-trained vision/language models
Important
Pre-trained Weights Available
This model has pre-trained weights available on the Hugging Face Hub. You can load them using:
from braindecode.models import CBraMod # Load pre-trained model from Hugging Face Hub model = CBraMod.from_pretrained( "braindecode/cbramod-pretrained", return_encoder_output=True )
To push your own trained model to the Hub:
# After training your model model.push_to_hub( repo_id="username/my-cbramod-model", commit_message="Upload trained CBraMod model" )
Requires installing
braindecode[hug]for Hub integration.- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
patch_size (
int) – Temporal patch size in samples (200 samples = 1 second at 200 Hz).dim_feedforward (
int) – Dimension of the feedforward network in Transformer layers.n_layer (
int) – Number of Transformer layers.nhead (
int) – Number of attention heads.activation (
type[Module]) – Activation function used in Transformer feedforward layers.emb_dim (
int) – Output embedding dimension.channels_kernel_stride_padding_norm (
Sequence[tuple[int,int,int,int,tuple[int,int]]]) – The description is missing.drop_prob (
float) – Dropout probability.return_encoder_output (
bool) – If false (default), the features are flattened and passed through a final linear layer to produce class logits of sizen_outputs. If True, the model returns the encoder output features.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[cbramod]Wang, J., Zhao, S., Luo, Z., Zhou, Y., Jiang, H., Li, S., Li, T., & Pan, G. (2025). CBraMod: A Criss-Cross Brain Foundation Model for EEG Decoding. In The Thirteenth International Conference on Learning Representations (ICLR 2025). https://arxiv.org/abs/2412.07236
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import CBraMod # Train your model model = CBraMod(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-cbramod-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import CBraMod # Load pretrained model model = CBraMod.from_pretrained("username/my-cbramod-model") # Load with a different number of outputs (head is rebuilt automatically) model = CBraMod.from_pretrained("username/my-cbramod-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = CBraMod.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(x, mask=None, return_features=False)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
x – The description is missing.
mask – The description is missing.
return_features – The description is missing.
- reset_head(n_outputs)[source]#
Replace the classification head for a new number of outputs.
This is called automatically by
from_pretrained()when the user passes ann_outputsthat differs from the saved config. Override in subclasses that need a model-specific head structure.- Parameters:
n_outputs (int) – New number of output classes.
Examples
>>> from braindecode.models import BENDR >>> model = BENDR(n_chans=22, n_times=1000, n_outputs=4) >>> model.reset_head(10) >>> model.n_outputs 10
Added in version 1.4.