
braindecode.models.EEGDINO#
- class braindecode.models.EEGDINO(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, patch_size=200, n_layer=12, nhead=8, dim_feedforward=512, channels_kernel_stride_padding_norm=((25, 49, 25, 24, (5, 25)), (25, 3, 1, 1, (5, 25)), (25, 3, 1, 1, (5, 25))), n_channel_embeddings=19, n_global_tokens=1, global_token_layer=1, activation=<class 'torch.nn.modules.activation.GELU'>, patch_activation=<class 'torch.nn.modules.activation.GELU'>, drop_prob=0.1, return_features=False, return_encoder_output=False)[source]#
EEG-DINO from Wang et al. (2025) [eegdino].
Foundation Model Attention/Transformer
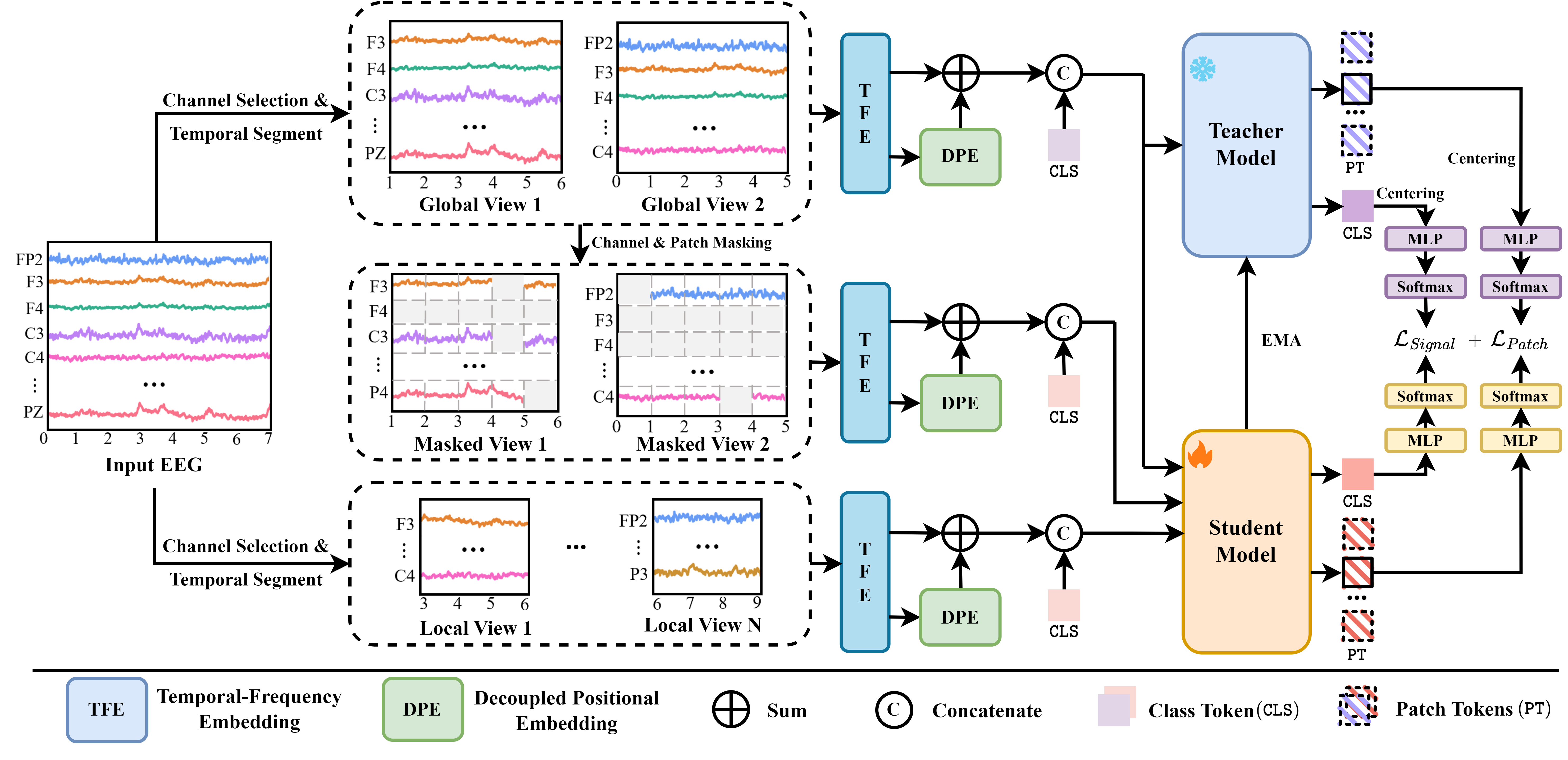
EEG-DINO is a ViT-style EEG foundation model pre-trained with DINO-v2 hierarchical self-distillation. Only the encoder (plus a classification head) is integrated here; the self-distillation pre-training is out of scope and it was not released by the authors.
The forward path is, end to end:
(batch, n_chans, n_times)→ patchify → time-frequency embedding → decoupled positional embedding → transformer encoder (+ global token) → pooling head →(batch, n_outputs).Step 1 – Patchify
The signal is split along time into non-overlapping patches of
patch_sizesamples (200 samples = 1 second at 200 Hz), giving one token per (channel, patch). Inputs whose length is not a multiple ofpatch_sizeare zero-padded with a warning. This is analogous to the patchification in ViT, BEiT (LaBraM), and CBraMod.Step 2 – Time-Frequency Embedding (TFE)
Each patch is embedded by summing two branches, exactly as in
CBraMod(the EEG-DINO paper reuses CBraMod’s TFE): a time-domain branch of stacked grouped convolutions (proj_in), and a frequency-domain branch projecting the magnitude of the patch’s real FFT (spectral_proj). The embedding dimensionemb_dimis therefore derived from the convolution configuration, not set independently.Step 3 – Decoupled Positional Embedding (DPE)
Where CBraMod uses a single convolutional positional encoding (ACPE), EEG-DINO decouples space and time and adds both to every token: a learnable one-hot channel embedding over a fixed vocabulary of
n_channel_embeddingsslots (input channelimaps to sloti, so a 19-slot embedding serves anyn_chans <= 19) and a depthwise temporal convolution over the patch axis (time_encoding).Step 4 – Transformer Encoder & Global Token
Tokens are flattened to a single sequence and processed by
n_layerpre-norm transformer blocks (BEiT-style attention with separate query/value biases). A learnableglobal_tokenssummary token is prepended after theglobal_token_layer-th block and attends jointly with the patch tokens.Step 5 – Classification Head (
final_layer)Following EEG-DINO’s finetuning head, the patch tokens (global token excluded) pass through a per-token projection, are mean-pooled over channels then over patches (with an intermediate projection), and a three-layer MLP (
final_layer) maps them ton_outputs(EEGClassifierapplies the softmax). Withreturn_encoder_output=Truethe mean-pooled encoder representation is returned instead (linear probing).Warning
EEG-DINO was pre-trained on EEG in microvolts scaled by
1 / 100. The model does not rescale its input, so for the released weights to behave as intended provide data on the same scale (e.g. microvolts divided by 100) or normalize your signals consistently.Important
Pre-trained Weights Available
Small and Medium encoders converted from the released checkpoints are hosted on the Hugging Face Hub, one repository per size. Only the encoder is pretrained; the classification head is randomly initialized, so fine-tune or linear-probe before use:
from braindecode.models import EEGDINO model = EEGDINO.from_pretrained( "braindecode/eegdino-small-pretrained", # or -medium-pretrained n_outputs=6, n_chans=19, sfreq=200, )
The Small/Medium/Large architectures are also available in
EEGDINO_CONFIGS. Requiresbraindecode[hub].Added in version 1.6.1.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
patch_size (
int) – Temporal patch size in samples (200 = 1 second at 200 Hz). Fixed at 200 for the released weights (the FFT branch usespatch_size // 2 + 1bins).n_layer (
int) – Number of transformer encoder layers.nhead (
int) – Number of attention heads.dim_feedforward (
int) – Hidden size of the transformer feed-forward block.channels_kernel_stride_padding_norm (
Sequence[tuple[int,int,int,int,tuple[int,int]]]) – Configuration of the time-domain convolutions in the patch embedding, as(out_channels, kernel, stride, padding, (groups, group_channels))per layer. The embedding dimension is derived from this (seeCBraMod). Default is the EEG-DINO-Small / CBraMod configuration.n_channel_embeddings (
int) – Size of the one-hot channel-embedding vocabulary.n_chansmust not exceed it; the firstn_chansslots are used. Default 19 (the released montage), so the pretrained weights load for anyn_chans <= 19.n_global_tokens (
int) – Number of learnable global summary tokens.global_token_layer (
int) – 1-based index of the encoder layer after which the global tokens are inserted.activation (
type[Module]) – Activation function used in the transformer feed-forward blocks and the classification head.patch_activation (
type[Module]) – Activation function used in the patch-embedding convolutions. Defaults tonn.GELUto match the released pretrained weights.drop_prob (
float) – Dropout / stochastic-depth probability in the encoder.return_features (
bool) – If True,forwardreturns{"features", "cls_token"}.return_encoder_output (
bool) – If True,final_layerisIdentityandforwardreturns the pooled encoder representation (linear probing).
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[eegdino]Wang, X., Liu, X., Liu, X., Si, Q., Xu, Z., Li, Y., & Zhen, X. (2025). EEG-DINO: Learning EEG Foundation Models via Hierarchical Self-Distillation. In Medical Image Computing and Computer Assisted Intervention (MICCAI 2025).
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import EEGDINO # Train your model model = EEGDINO(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-eegdino-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import EEGDINO # Load pretrained model model = EEGDINO.from_pretrained("username/my-eegdino-model") # Load with a different number of outputs (head is rebuilt automatically) model = EEGDINO.from_pretrained("username/my-eegdino-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = EEGDINO.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(x, return_features=None)[source]#
Forward pass.
- Parameters:
x (torch.Tensor) – Input of shape
(batch, n_chans, n_times). The model does not rescalex(see the amplitude-scale warning in the class docstring).return_features (
bool|None) – Overridesself.return_featuresfor this call.
- Returns:
Logits
(batch, n_outputs); or, with features,{"features": (batch, n_chans * n_patches, emb_dim), "cls_token": (batch, emb_dim)}.- Return type:
torch.Tensor or dict
- reset_head(n_outputs)[source]#
Replace
final_layerwith a fresh classification head forn_outputs.Asking for a head implies a classification model, so this also clears
return_encoder_output(a linear-probe model thereby gains a real head), mirroringbraindecode.models.CBraMod.reset_head().- Parameters:
n_outputs (int) – New number of output classes.
Examples
>>> from braindecode.models import BENDR >>> model = BENDR(n_chans=22, n_times=1000, n_outputs=4) >>> model.reset_head(10) >>> model.n_outputs 10
Added in version 1.4.