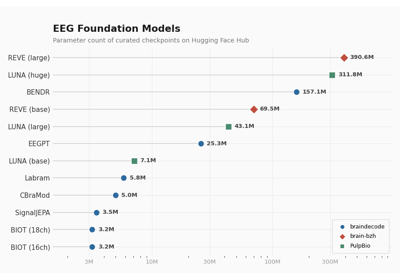
braindecode.models.STEEGFormer#
- class braindecode.models.STEEGFormer(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, patch_size=16, embed_dim=512, depth=8, num_heads=8, mlp_ratio=4, drop_prob=0.0, drop_path=0.0, activation=<class 'torch.nn.modules.activation.GELU'>, global_pool='avg', n_chans_pos=145, chan_pos_idx=None)[source]#
STEEGFormer from Yang et al. (2026) [Yang2026].
Attention/Transformer Foundation Model
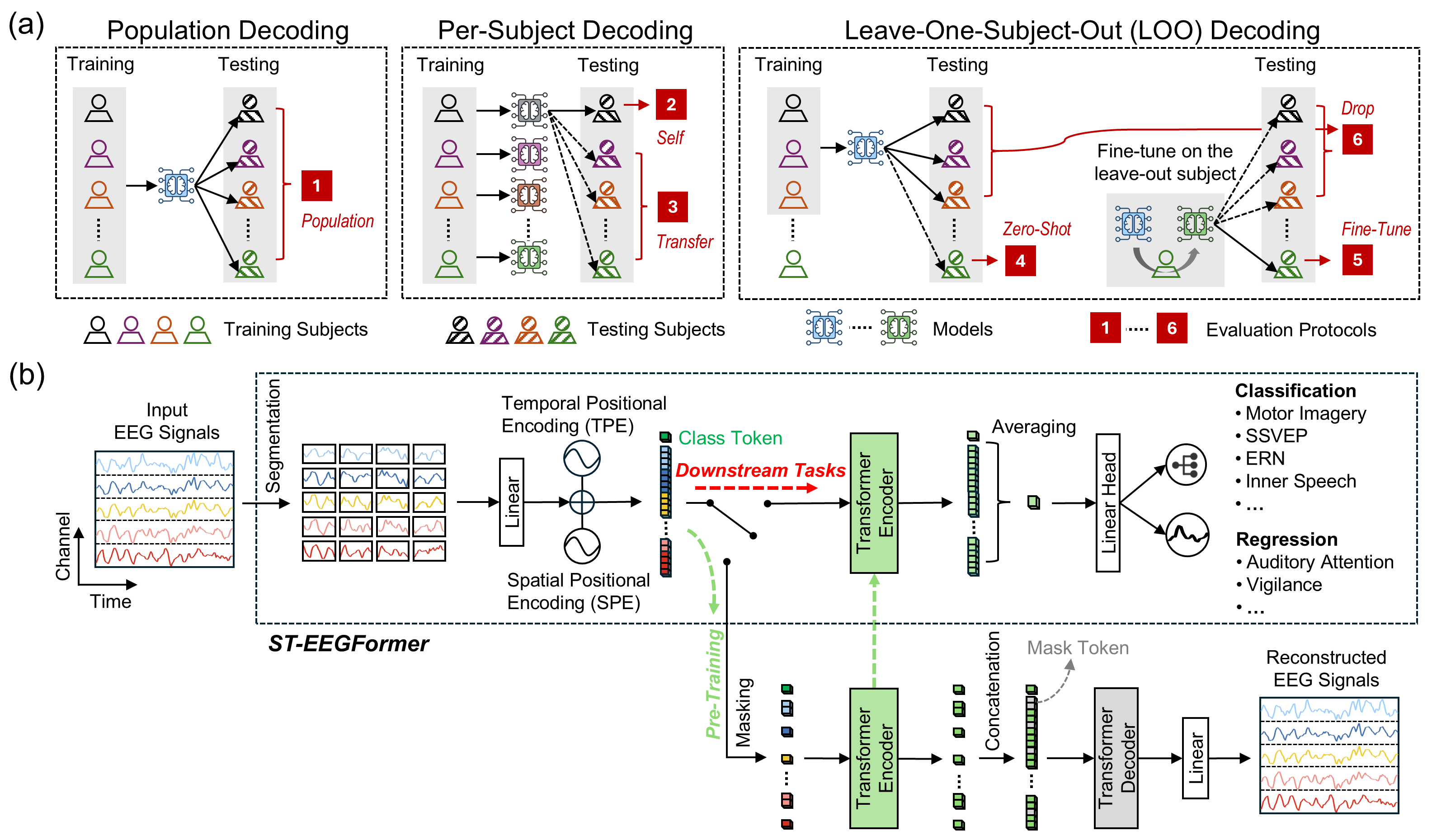
ST-EEGFormer architecture, reproduced from the official repository (
LiuyinYang1101/STEEGFormer).#Added in version 1.6.1.
Architecture Overview
ViT-based EEG foundation model, pre-trained with a Masked Autoencoder (MAE) objective on raw EEG. Each channel is cut into non-overlapping temporal patches that are linearly embedded into tokens, augmented with temporal and channel positional information, prepended with a learned CLS token, encoded by a stack of pre-norm Transformer blocks, and read out by a linear head.
Macro Components
Patch + token embedding (
STEEGFormer.patch_embed). Operations: cut each channel intoseq = n_times // patch_sizenon-overlapping patches ofpatch_sizesamples and linearly project each to anembed_dimtoken. Role: turn aC-channel segment intoC * seqtokens (one per (channel, time-patch) pair).Positional embeddings (
STEEGFormer.temporal_pos,STEEGFormer.channel_pos). Operations: add a fixed sinusoidal temporal encoding over theseqpatches and a learned channel embedding drawn from a shared montage vocabulary. Role: mark when (in time) and on which electrode each token sits, so the same electrode shares its embedding across datasets with different channel sets.Transformer encoder (
STEEGFormer.encoder). Operations:depthpre-norm ViT blocks (multi-head self-attention + MLP), reusing braindecode’sMultiHeadAttentionandFeedForwardBlock. Role: mix information across all (channel, time-patch) tokens.Read-out + head (
STEEGFormer.norm,STEEGFormer.final_layer). Operations:"avg"mean-pools the patch tokens (CLS excluded);"cls"layer-normalises the sequence and takes the CLS token; a linear layer maps ton_outputs. Role: produce the class logits.
Temporal, Spatial, and Spectral Encoding
Temporal: non-overlapping temporal patches with a fixed sinusoidal position encoding over the
seqpatches.Spatial (channels): a learned channel embedding indexed through a shared montage vocabulary of standard electrode positions.
Spectral: none explicit; frequency content is learned implicitly by the patch projection and self-attention.
Additional Mechanisms
A learned CLS token (sequence position 0) summarises the sequence for the
"cls"read-out. Optional stochastic depth (drop_path) and dropout (drop_prob) regularise training; both default to0to match the released checkpoints.Variants
The released variants differ in width/depth and, for
largeV2, the channel-vocabulary size (patch_size=16,mlp_ratio=4throughout):Variant
embed_dimdepthnum_headsn_chans_possmall
512
8
8
145
base
768
12
12
145
large
1024
24
16
145
largeV2
1024
24
16
256
Pre-trained weights
Ready-to-use checkpoints are re-hosted on the Hugging Face Hub under the braindecode organization. These repos convert the official MAE encoder checkpoints to braindecode’s key names and include
config.jsonplusmodel.safetensors/pytorch_model.bin:Variant
Hub repo
Notes
small
braindecode/STEEGFormer-small145-slot channel vocabulary
base
braindecode/STEEGFormer-base145-slot channel vocabulary
large
braindecode/STEEGFormer-large145-slot channel vocabulary
largeV2
braindecode/STEEGFormer-largeV2256-slot HBN channel vocabulary
Use the regular Hub API to load a re-hosted checkpoint:
model = STEEGFormer.from_pretrained( "braindecode/STEEGFormer-small", n_outputs=4, n_chans=22 )
The re-hosted repos save complete braindecode model files, so they include a classification head tensor for serialization. Only the encoder weights are from the official MAE pretraining; pass
n_outputsfor the downstream task so the head is rebuilt as needed.To regenerate the re-hosted files from the official GitHub checkpoints, run the standalone
convert_steegformer_checkpoints.pyarchived in each Hub repo; the model itself loads braindecode-format state dicts, sofrom_pretrainedneeds no conversion.Note
Numerical equivalence of the encoder features with the reference implementation has been verified on the released checkpoints. The channel-to-vocabulary mapping is resolved from the electrode names in
chs_info(looked up inSTEEGFORMER_CHANNEL_ORDER, the BENDR/LaBraM convention); whenchs_infois absent or a name is unknown, it falls back to the identity mapping (channeli-> sloti) with a warning. Passchan_pos_idxto override explicitly.- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
patch_size (
int) – Temporal patch size (unfold), default 16.embed_dim (
int) – Token embedding dimension (512 / 768 / 1024 across variants).depth (
int) – Number of Transformer encoder blocks.num_heads (
int) – Number of attention heads.mlp_ratio (
int) – Hidden-to-embedding ratio of the MLP blocks.drop_prob (
float) – Dropout rate.drop_path (
float) – Stochastic-depth rate (max of a linear schedule overdepth), default0(disabled, matching the released checkpoints).activation (
type[Module]) – Activation layer class used in the feed-forward blocks, defaultGELU.global_pool (
str) – Token aggregation before the head ("avg"or"cls").n_chans_pos (
int) – Size of the shared montage vocabulary the channel embedding is drawn from (145 for small/base/large, 256 forlargeV2), default 145.chan_pos_idx (array-like of int, optional) – Montage-vocabulary slot of each input channel, shape
(n_chans,). If omitted, it is resolved fromchs_infoelectrode names (falling back torange(n_chans)).
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Yang2026]Yang, L., Sun, Q., Li, A. & Van Hulle, M. M. (2026). Are EEG foundation models worth it? Comparative evaluation with traditional decoders in diverse BCI tasks. The Fourteenth International Conference on Learning Representations (ICLR 2026). https://openreview.net/forum?id=5Xwm8e6vbh
Hugging Face Hub integration
When the optional
huggingface_hubpackage is installed, all models automatically gain the ability to be pushed to and loaded from the Hugging Face Hub. Install with:pip install braindecode[hub]
Pushing a model to the Hub:
from braindecode.models import STEEGFormer # Train your model model = STEEGFormer(n_chans=22, n_outputs=4, n_times=1000) # ... training code ... # Push to the Hub model.push_to_hub( repo_id="username/my-steegformer-model", commit_message="Initial model upload", )
Loading a model from the Hub:
from braindecode.models import STEEGFormer # Load pretrained model model = STEEGFormer.from_pretrained("username/my-steegformer-model") # Load with a different number of outputs (head is rebuilt automatically) model = STEEGFormer.from_pretrained("username/my-steegformer-model", n_outputs=4)
Extracting features and replacing the head:
import torch x = torch.randn(1, model.n_chans, model.n_times) # Extract encoder features (consistent dict across all models) out = model(x, return_features=True) features = out["features"] # Replace the classification head model.reset_head(n_outputs=10)
Saving and restoring full configuration:
import json config = model.get_config() # all __init__ params with open("config.json", "w") as f: json.dump(config, f) model2 = STEEGFormer.from_config(config) # reconstruct (no weights)
All model parameters (both EEG-specific and model-specific such as dropout rates, activation functions, number of filters) are automatically saved to the Hub and restored when loading.
See Loading and Adapting Pretrained Foundation Models for a complete tutorial.
Methods
- forward(x, return_features=False)[source]#
Encode an EEG batch into class logits (or encoder features).
- Parameters:
x (
Tensor) – EEG input of shape(batch, n_chans, n_times).return_features (
bool) – IfTrue, return the layer-normalised encoder tokens as{"features": patch_tokens, "cls_token": cls_token}instead of the class logits (the unified braindecode foundation-model API). Thecls_tokenthen matches the feature the"cls"head consumes.
- Returns:
Class logits of shape
(batch, n_outputs), or the feature dict{"features", "cls_token"}whenreturn_featuresis set.- Return type:
- reset_head(n_outputs)[source]#
Replace the linear classification head for a new
n_outputs.Called by
from_pretrained()when the requested number of outputs differs from the pre-trained checkpoint (whose head is discarded).- Parameters:
n_outputs (int) – New number of output classes.
Examples
>>> from braindecode.models import BENDR >>> model = BENDR(n_chans=22, n_times=1000, n_outputs=4) >>> model.reset_head(10) >>> model.n_outputs 10
Added in version 1.4.