braindecode.preprocessing.preprocess#
- braindecode.preprocessing.preprocess(concat_ds, preprocessors, save_dir=None, overwrite=False, n_jobs=None, offset=0, copy_data=None, parallel_kwargs=None, max_nbytes='1M')[source]#
Apply preprocessors to a concat dataset.
- Parameters:
concat_ds (
BaseConcatDataset) – A concat ofRecordDatasetto be preprocessed.preprocessors (
list[Preprocessor]) – Preprocessor objects to apply to each dataset.save_dir (
str|None) – If provided, save preprocessed data under this directory and reload datasets inconcat_dswithpreload=False.overwrite (
bool) – Whensave_diris provided, controls whether to delete the old subdirectories that will be written to undersave_dir. If False and the corresponding subdirectories already exist, aFileExistsErroris raised.n_jobs (
int|None) – Number of jobs for parallel execution. Seejoblib.Parallelfor details.offset (
int) – Integer added to the dataset id in the concat. Useful when processing and saving very large datasets in chunks to preserve original positions.copy_data (
bool|None) – Whether the data passed to parallel jobs should be copied or passed by reference.parallel_kwargs (
dict|None) – Additional keyword arguments forwarded tojoblib.Parallel. Defaults to None (equivalent to{}). See https://joblib.readthedocs.io/en/stable/generated/joblib.Parallel.html for details.max_nbytes (
int|str|None) – Threshold (in bytes; or e.g."1M") above which joblib memory-maps preloaded arrays as read-only when dispatching to worker processes. Effective only whenn_jobs != 1. PassNoneto disable memory mapping when a preprocessor resizes the underlying data (for examplefilterbank), which would otherwise fail with anmmap can't resize a readonlyerror.parallel_kwargs['max_nbytes']takes precedence if both are provided.
- Returns:
Preprocessed dataset.
- Return type:
Examples using braindecode.preprocessing.preprocess#
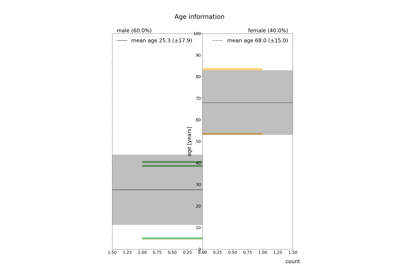
Cleaning EEG Data with EEGPrep for Trialwise Decoding
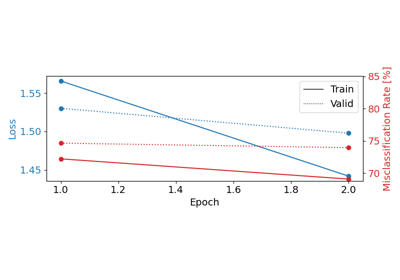
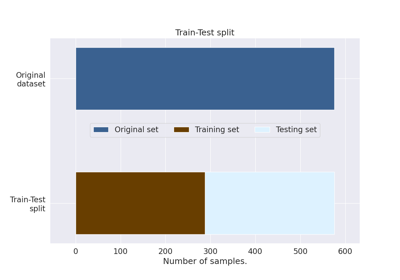
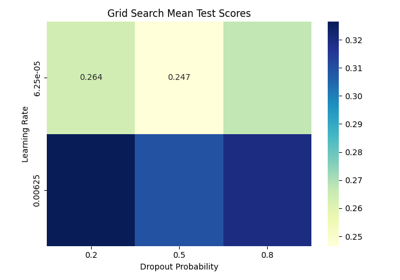

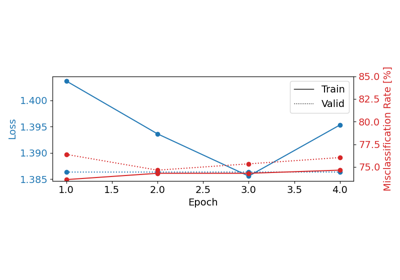
Comprehensive Preprocessing with MNE-based Classes

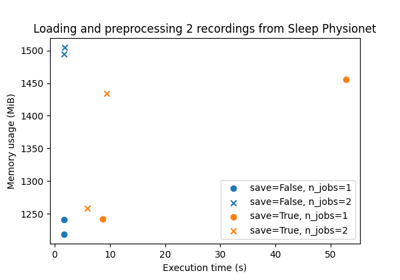
Benchmarking preprocessing with parallelization and serialization



Fingers flexion cropped decoding on BCIC IV 4 ECoG Dataset
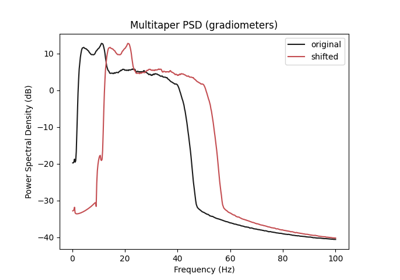
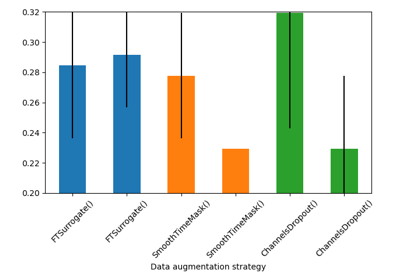
Searching the best data augmentation on BCIC IV 2a Dataset
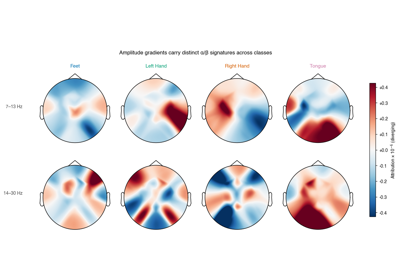
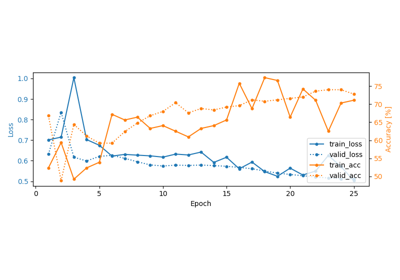
Self-supervised learning on EEG with relative positioning

Fingers flexion decoding on BCIC IV 4 ECoG Dataset
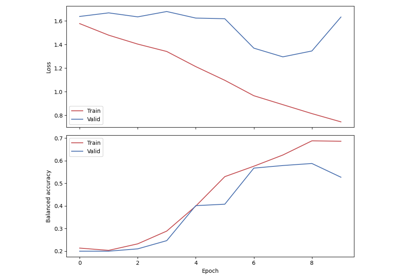
Sleep staging on the Sleep Physionet dataset using Chambon2018 network
Sleep staging on the Sleep Physionet dataset using Eldele2021
Sleep staging on the Sleep Physionet dataset using U-Sleep network