Note
Go to the end to download the full example code
Sleep staging on the Sleep Physionet dataset using U-Sleep network#
Note
Please take a look at the simpler sleep staging example here before going through this example. The current example uses a more complex architecture and a sequence-to-sequence (seq2seq) approach.
This tutorial shows how to train and test a sleep staging neural network with Braindecode. We adapt the U-Sleep approach of [1] to learn on sequences of EEG windows using the openly accessible Sleep Physionet dataset [2] [3].
Warning
The example is written to have a very short execution time. This number of epochs is here too small and very few recordings are used. To obtain competitive results you need to use more data and more epochs.
# Authors: Theo Gnassounou <theo.gnassounou@inria.fr>
# Omar Chehab <l-emir-omar.chehab@inria.fr>
#
# License: BSD (3-clause)
Loading and preprocessing the dataset#
Loading#
First, we load the data using the
braindecode.datasets.sleep_physionet.SleepPhysionet class. We load
two recordings from two different individuals: we will use the first one to
train our network and the second one to evaluate performance (as in the MNE
sleep staging example).
from braindecode.datasets import SleepPhysionet
subject_ids = [0, 1]
crop = (0, 30 * 400) # we only keep 400 windows of 30s to speed example
dataset = SleepPhysionet(
subject_ids=subject_ids, recording_ids=[2], crop_wake_mins=30,
crop=crop)
Preprocessing#
Next, we preprocess the raw data. We scale each channel recording-wise to have zero median and unit interquartile range. We don’t upsample to 128 Hz as done in [1] so that we keep the example as light as possible. No filtering is described in [1].
from braindecode.preprocessing import preprocess, Preprocessor
from sklearn.preprocessing import robust_scale
preprocessors = [Preprocessor(robust_scale, channel_wise=True)]
# Transform the data
preprocess(dataset, preprocessors)
<braindecode.datasets.sleep_physionet.SleepPhysionet object at 0x7f4542b6bbb0>
Extract windows#
We extract 30-s windows to be used in the classification task.
from braindecode.preprocessing import create_windows_from_events
mapping = { # We merge stages 3 and 4 following AASM standards.
'Sleep stage W': 0,
'Sleep stage 1': 1,
'Sleep stage 2': 2,
'Sleep stage 3': 3,
'Sleep stage 4': 3,
'Sleep stage R': 4,
}
window_size_s = 30
sfreq = 100
window_size_samples = window_size_s * sfreq
windows_dataset = create_windows_from_events(
dataset,
trial_start_offset_samples=0,
trial_stop_offset_samples=0,
window_size_samples=window_size_samples,
window_stride_samples=window_size_samples,
preload=True,
mapping=mapping,
)
Split dataset into train and valid#
We split the dataset into training and validation set taking every other subject as train or valid.
split_ids = dict(train=subject_ids[::2], valid=subject_ids[1::2])
splits = windows_dataset.split(split_ids)
train_set, valid_set = splits["train"], splits["valid"]
Create sequence samplers#
Following the sequence-to-sequence approach of [1], we need to provide our neural network with sequences of windows. We can achieve this by defining Sampler objects that return sequences of windows. Non-overlapping sequences of 35 windows are used in [1], however to limit the memory requirements for this example we use shorter sequences of 3 windows.
from braindecode.samplers import SequenceSampler
n_windows = 3 # Sequences of 3 consecutive windows; originally 35 in paper
n_windows_stride = 3 # Non-overlapping sequences
train_sampler = SequenceSampler(
train_set.get_metadata(), n_windows, n_windows_stride, randomize=True
)
valid_sampler = SequenceSampler(valid_set.get_metadata(), n_windows, n_windows_stride)
# Print number of examples per class
print(len(train_sampler))
print(len(valid_sampler))
133
133
Finally, since some sleep stages appear a lot more often than others (e.g. most of the night is spent in the N2 stage), the classes are imbalanced. To avoid overfitting to the more frequent classes, we compute weights that we will provide to the loss function when training.
import numpy as np
from sklearn.utils import compute_class_weight
y_train = [train_set[idx][1][1] for idx in train_sampler]
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
Create model#
We can now create the deep learning model. In this tutorial, we use the U-Sleep architecture introduced in [1], which is fully convolutional neural network.
import torch
from braindecode.util import set_random_seeds
from braindecode.models import USleep
cuda = torch.cuda.is_available() # check if GPU is available
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if cuda:
torch.backends.cudnn.benchmark = True
# Set random seed to be able to roughly reproduce results
# Note that with cudnn benchmark set to True, GPU indeterminism
# may still make results substantially different between runs.
# To obtain more consistent results at the cost of increased computation time,
# you can set `cudnn_benchmark=False` in `set_random_seeds`
# or remove `torch.backends.cudnn.benchmark = True`
set_random_seeds(seed=31, cuda=cuda)
n_classes = 5
classes = list(range(n_classes))
# Extract number of channels and time steps from dataset
in_chans, input_size_samples = train_set[0][0].shape
model = USleep(
n_chans=in_chans,
sfreq=sfreq,
depth=12,
with_skip_connection=True,
n_outputs=n_classes,
n_times=input_size_samples
)
# Send model to GPU
if cuda:
model.cuda()
Training#
We can now train our network. braindecode.EEGClassifier is a
braindecode object that is responsible for managing the training of neural
networks. It inherits from skorch.NeuralNetClassifier, so the
training logic is the same as in
Skorch.
Note
We use different hyperparameters from [1], as these hyperparameters were optimized on different datasets and with a different number of recordings. Generally speaking, it is recommended to perform hyperparameter optimization if reusing this code on a different dataset or with more recordings.
from skorch.helper import predefined_split
from skorch.callbacks import EpochScoring
from braindecode import EEGClassifier
lr = 1e-3
batch_size = 32
n_epochs = 3 # we use few epochs for speed and but more than one for plotting
from sklearn.metrics import balanced_accuracy_score
def balanced_accuracy_multi(model, X, y):
y_pred = model.predict(X)
return balanced_accuracy_score(y.flatten(), y_pred.flatten())
train_bal_acc = EpochScoring(
scoring=balanced_accuracy_multi,
on_train=True,
name='train_bal_acc',
lower_is_better=False,
)
valid_bal_acc = EpochScoring(
scoring=balanced_accuracy_multi,
on_train=False,
name='valid_bal_acc',
lower_is_better=False,
)
callbacks = [
('train_bal_acc', train_bal_acc),
('valid_bal_acc', valid_bal_acc)
]
clf = EEGClassifier(
model,
criterion=torch.nn.CrossEntropyLoss,
criterion__weight=torch.Tensor(class_weights).to(device),
optimizer=torch.optim.Adam,
iterator_train__shuffle=False,
iterator_train__sampler=train_sampler,
iterator_valid__sampler=valid_sampler,
train_split=predefined_split(valid_set), # using valid_set for validation
optimizer__lr=lr,
batch_size=batch_size,
callbacks=callbacks,
device=device,
classes=classes,
)
# Deactivate the default valid_acc callback:
clf.set_params(callbacks__valid_acc=None)
# Model training for a specified number of epochs. `y` is None as it is already
# supplied in the dataset.
clf.fit(train_set, y=None, epochs=n_epochs)
/home/runner/.local/lib/python3.10/site-packages/torch/nn/modules/conv.py:306: UserWarning: Using padding='same' with even kernel lengths and odd dilation may require a zero-padded copy of the input be created (Triggered internally at ../aten/src/ATen/native/Convolution.cpp:1008.)
return F.conv1d(input, weight, bias, self.stride,
epoch train_bal_acc train_loss valid_bal_acc valid_loss dur
------- --------------- ------------ --------------- ------------ ------
1 0.2040 1.6129 0.1707 1.5807 2.1639
2 0.2224 1.5430 0.1594 1.5866 1.7210
3 0.3464 1.4928 0.1853 1.6026 1.7986
<class 'braindecode.classifier.EEGClassifier'>[initialized](
module_=======================================================================================================================================================
Layer (type (var_name):depth-idx) Input Shape Output Shape Param # Kernel Shape
======================================================================================================================================================
USleep (USleep) [1, 2, 3000] [1, 5] -- --
├─Sequential (encoder): 1-1 -- -- -- --
│ └─_EncoderBlock (0): 2-1 [1, 2, 3000] [1, 6, 1500] -- 7
│ │ └─Sequential (block_prepool): 3-1 [1, 2, 3000] [1, 6, 3000] 102 --
│ │ └─MaxPool1d (maxpool): 3-2 [1, 6, 3000] [1, 6, 1500] -- 2
│ └─_EncoderBlock (1): 2-2 [1, 6, 1500] [1, 9, 750] -- 7
│ │ └─Sequential (block_prepool): 3-3 [1, 6, 1500] [1, 9, 1500] 405 --
│ │ └─MaxPool1d (maxpool): 3-4 [1, 9, 1500] [1, 9, 750] -- 2
│ └─_EncoderBlock (2): 2-3 [1, 9, 750] [1, 11, 375] -- 7
│ │ └─Sequential (block_prepool): 3-5 [1, 9, 750] [1, 11, 750] 726 --
│ │ └─MaxPool1d (maxpool): 3-6 [1, 11, 750] [1, 11, 375] -- 2
│ └─_EncoderBlock (3): 2-4 [1, 11, 375] [1, 15, 188] -- 7
│ │ └─Sequential (block_prepool): 3-7 [1, 11, 375] [1, 15, 375] 1,200 --
│ │ └─ConstantPad1d (pad): 3-8 [1, 15, 375] [1, 15, 377] -- --
│ │ └─MaxPool1d (maxpool): 3-9 [1, 15, 377] [1, 15, 188] -- 2
│ └─_EncoderBlock (4): 2-5 [1, 15, 188] [1, 20, 94] -- 7
│ │ └─Sequential (block_prepool): 3-10 [1, 15, 188] [1, 20, 188] 2,160 --
│ │ └─MaxPool1d (maxpool): 3-11 [1, 20, 188] [1, 20, 94] -- 2
│ └─_EncoderBlock (5): 2-6 [1, 20, 94] [1, 28, 47] -- 7
│ │ └─Sequential (block_prepool): 3-12 [1, 20, 94] [1, 28, 94] 4,004 --
│ │ └─MaxPool1d (maxpool): 3-13 [1, 28, 94] [1, 28, 47] -- 2
│ └─_EncoderBlock (6): 2-7 [1, 28, 47] [1, 40, 24] -- 7
│ │ └─Sequential (block_prepool): 3-14 [1, 28, 47] [1, 40, 47] 7,960 --
│ │ └─ConstantPad1d (pad): 3-15 [1, 40, 47] [1, 40, 49] -- --
│ │ └─MaxPool1d (maxpool): 3-16 [1, 40, 49] [1, 40, 24] -- 2
│ └─_EncoderBlock (7): 2-8 [1, 40, 24] [1, 55, 12] -- 7
│ │ └─Sequential (block_prepool): 3-17 [1, 40, 24] [1, 55, 24] 15,565 --
│ │ └─MaxPool1d (maxpool): 3-18 [1, 55, 24] [1, 55, 12] -- 2
│ └─_EncoderBlock (8): 2-9 [1, 55, 12] [1, 77, 6] -- 7
│ │ └─Sequential (block_prepool): 3-19 [1, 55, 12] [1, 77, 12] 29,876 --
│ │ └─MaxPool1d (maxpool): 3-20 [1, 77, 12] [1, 77, 6] -- 2
│ └─_EncoderBlock (9): 2-10 [1, 77, 6] [1, 108, 3] -- 7
│ │ └─Sequential (block_prepool): 3-21 [1, 77, 6] [1, 108, 6] 58,536 --
│ │ └─MaxPool1d (maxpool): 3-22 [1, 108, 6] [1, 108, 3] -- 2
│ └─_EncoderBlock (10): 2-11 [1, 108, 3] [1, 152, 2] -- 7
│ │ └─Sequential (block_prepool): 3-23 [1, 108, 3] [1, 152, 3] 115,368 --
│ │ └─ConstantPad1d (pad): 3-24 [1, 152, 3] [1, 152, 5] -- --
│ │ └─MaxPool1d (maxpool): 3-25 [1, 152, 5] [1, 152, 2] -- 2
│ └─_EncoderBlock (11): 2-12 [1, 152, 2] [1, 214, 1] -- 7
│ │ └─Sequential (block_prepool): 3-26 [1, 152, 2] [1, 214, 2] 228,338 --
│ │ └─MaxPool1d (maxpool): 3-27 [1, 214, 2] [1, 214, 1] -- 2
├─Sequential (bottom): 1-2 [1, 214, 1] [1, 302, 1] -- --
│ └─Conv1d (0): 2-13 [1, 214, 1] [1, 302, 1] 452,698 [7]
│ └─ELU (1): 2-14 [1, 302, 1] [1, 302, 1] -- --
│ └─BatchNorm1d (2): 2-15 [1, 302, 1] [1, 302, 1] 604 --
├─Sequential (decoder): 1-3 -- -- -- --
│ └─_DecoderBlock (0): 2-16 [1, 302, 1] [1, 214, 2] -- 7
│ │ └─Sequential (block_preskip): 3-28 [1, 302, 1] [1, 214, 2] 129,898 --
│ │ └─Sequential (block_postskip): 3-29 [1, 428, 2] [1, 214, 2] 641,786 --
│ └─_DecoderBlock (1): 2-17 [1, 214, 2] [1, 152, 3] -- 7
│ │ └─Sequential (block_preskip): 3-30 [1, 214, 2] [1, 152, 4] 65,512 --
│ │ └─Sequential (block_postskip): 3-31 [1, 304, 3] [1, 152, 3] 323,912 --
│ └─_DecoderBlock (2): 2-18 [1, 152, 3] [1, 108, 6] -- 7
│ │ └─Sequential (block_preskip): 3-32 [1, 152, 3] [1, 108, 6] 33,156 --
│ │ └─Sequential (block_postskip): 3-33 [1, 216, 6] [1, 108, 6] 163,620 --
│ └─_DecoderBlock (3): 2-19 [1, 108, 6] [1, 77, 12] -- 7
│ │ └─Sequential (block_preskip): 3-34 [1, 108, 6] [1, 77, 12] 16,863 --
│ │ └─Sequential (block_postskip): 3-35 [1, 154, 12] [1, 77, 12] 83,237 --
│ └─_DecoderBlock (4): 2-20 [1, 77, 12] [1, 55, 24] -- 7
│ │ └─Sequential (block_preskip): 3-36 [1, 77, 12] [1, 55, 24] 8,635 --
│ │ └─Sequential (block_postskip): 3-37 [1, 110, 24] [1, 55, 24] 42,515 --
│ └─_DecoderBlock (5): 2-21 [1, 55, 24] [1, 40, 47] -- 7
│ │ └─Sequential (block_preskip): 3-38 [1, 55, 24] [1, 40, 48] 4,520 --
│ │ └─Sequential (block_postskip): 3-39 [1, 80, 47] [1, 40, 47] 22,520 --
│ └─_DecoderBlock (6): 2-22 [1, 40, 47] [1, 28, 94] -- 7
│ │ └─Sequential (block_preskip): 3-40 [1, 40, 47] [1, 28, 94] 2,324 --
│ │ └─Sequential (block_postskip): 3-41 [1, 56, 94] [1, 28, 94] 11,060 --
│ └─_DecoderBlock (7): 2-23 [1, 28, 94] [1, 20, 188] -- 7
│ │ └─Sequential (block_preskip): 3-42 [1, 28, 94] [1, 20, 188] 1,180 --
│ │ └─Sequential (block_postskip): 3-43 [1, 40, 188] [1, 20, 188] 5,660 --
│ └─_DecoderBlock (8): 2-24 [1, 20, 188] [1, 15, 375] -- 7
│ │ └─Sequential (block_preskip): 3-44 [1, 20, 188] [1, 15, 376] 645 --
│ │ └─Sequential (block_postskip): 3-45 [1, 30, 375] [1, 15, 375] 3,195 --
│ └─_DecoderBlock (9): 2-25 [1, 15, 375] [1, 11, 750] -- 7
│ │ └─Sequential (block_preskip): 3-46 [1, 15, 375] [1, 11, 750] 363 --
│ │ └─Sequential (block_postskip): 3-47 [1, 22, 750] [1, 11, 750] 1,727 --
│ └─_DecoderBlock (10): 2-26 [1, 11, 750] [1, 9, 1500] -- 7
│ │ └─Sequential (block_preskip): 3-48 [1, 11, 750] [1, 9, 1500] 225 --
│ │ └─Sequential (block_postskip): 3-49 [1, 18, 1500] [1, 9, 1500] 1,161 --
│ └─_DecoderBlock (11): 2-27 [1, 9, 1500] [1, 6, 3000] -- 7
│ │ └─Sequential (block_preskip): 3-50 [1, 9, 1500] [1, 6, 3000] 126 --
│ │ └─Sequential (block_postskip): 3-51 [1, 12, 3000] [1, 6, 3000] 522 --
├─Sequential (clf): 1-4 [1, 6, 3000] [1, 6, 1] -- --
│ └─Conv1d (0): 2-28 [1, 6, 3000] [1, 6, 3000] 42 [1]
│ └─Tanh (1): 2-29 [1, 6, 3000] [1, 6, 3000] -- --
│ └─AvgPool1d (2): 2-30 [1, 6, 3000] [1, 6, 1] -- [3000]
├─Sequential (final_layer): 1-5 [1, 6, 1] [1, 5, 1] -- --
│ └─Conv1d (0): 2-31 [1, 6, 1] [1, 5, 1] 35 [1]
│ └─ELU (1): 2-32 [1, 5, 1] [1, 5, 1] -- --
│ └─Conv1d (2): 2-33 [1, 5, 1] [1, 5, 1] 30 [1]
│ └─Identity (3): 2-34 [1, 5, 1] [1, 5, 1] -- --
======================================================================================================================================================
Total params: 2,482,011
Trainable params: 2,482,011
Non-trainable params: 0
Total mult-adds (M): 22.43
======================================================================================================================================================
Input size (MB): 0.02
Forward/backward pass size (MB): 2.91
Params size (MB): 9.93
Estimated Total Size (MB): 12.86
======================================================================================================================================================,
)
Plot results#
We use the history stored by Skorch during training to plot the performance of the model throughout training. Specifically, we plot the loss and the balanced balanced accuracy for the training and validation sets.
import matplotlib.pyplot as plt
import pandas as pd
# Extract loss and balanced accuracy values for plotting from history object
df = pd.DataFrame(clf.history.to_list())
df.index.name = "Epoch"
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(8, 7), sharex=True)
df[['train_loss', 'valid_loss']].plot(color=['r', 'b'], ax=ax1)
df[['train_bal_acc', 'valid_bal_acc']].plot(color=['r', 'b'], ax=ax2)
ax1.set_ylabel('Loss')
ax2.set_ylabel('Balanced accuracy')
ax1.legend(['Train', 'Valid'])
ax2.legend(['Train', 'Valid'])
fig.tight_layout()
plt.show()
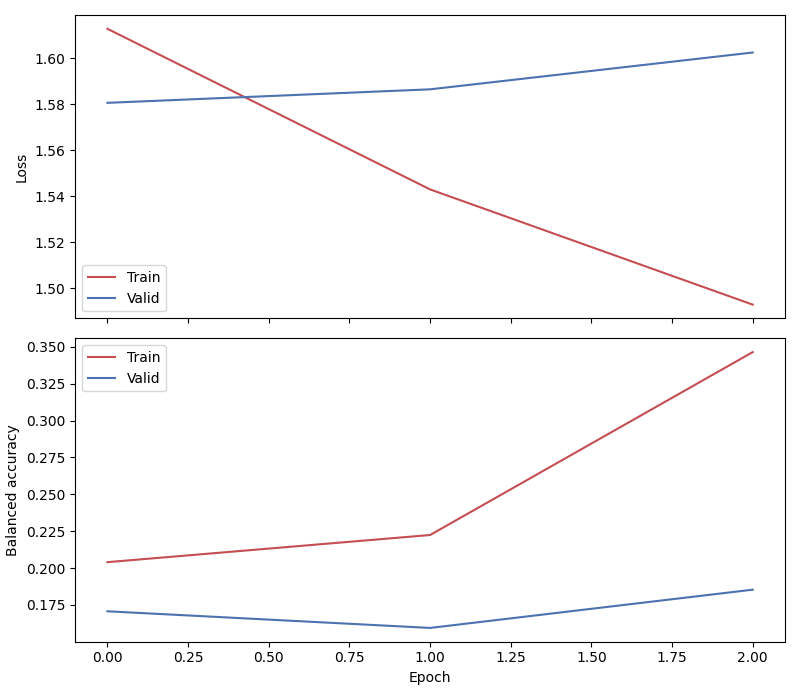
Finally, we also display the confusion matrix and classification report:
from braindecode.visualization import plot_confusion_matrix
from sklearn.metrics import confusion_matrix, classification_report
y_true = np.array([valid_set[i][1] for i in valid_sampler])
y_pred = clf.predict(valid_set)
confusion_mat = confusion_matrix(y_true.flatten(), y_pred.flatten())
plot_confusion_matrix(confusion_mat=confusion_mat,
class_names=['Wake', 'N1', 'N2', 'N3', 'REM'])
print(classification_report(y_true.flatten(), y_pred.flatten()))
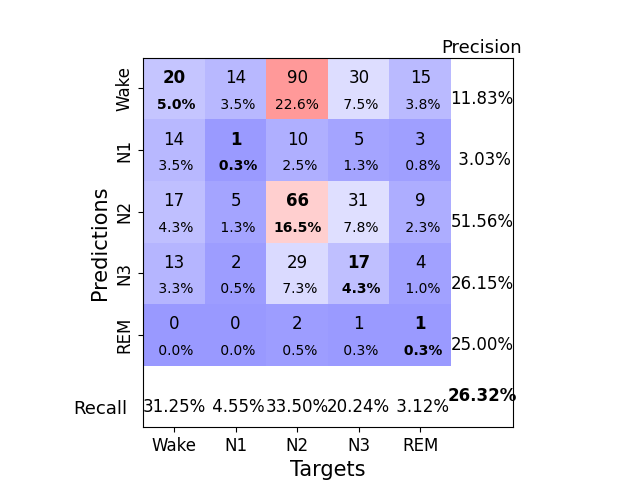
precision recall f1-score support
0 0.12 0.31 0.17 64
1 0.03 0.05 0.04 22
2 0.52 0.34 0.41 197
3 0.26 0.20 0.23 84
4 0.25 0.03 0.06 32
accuracy 0.26 399
macro avg 0.24 0.19 0.18 399
weighted avg 0.35 0.26 0.28 399
Finally, we can also visualize the hypnogram of the recording we used for validation, with the predicted sleep stages overlaid on top of the true sleep stages. We can see that the model cannot correctly identify the different sleep stages with this amount of training.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(15, 5))
ax.plot(y_true.flatten(), color='b', label='Expert annotations')
ax.plot(y_pred.flatten(), color='r', label='Predict annotations', alpha=0.5)
ax.set_xlabel('Time (epochs)')
ax.set_ylabel('Sleep stage')
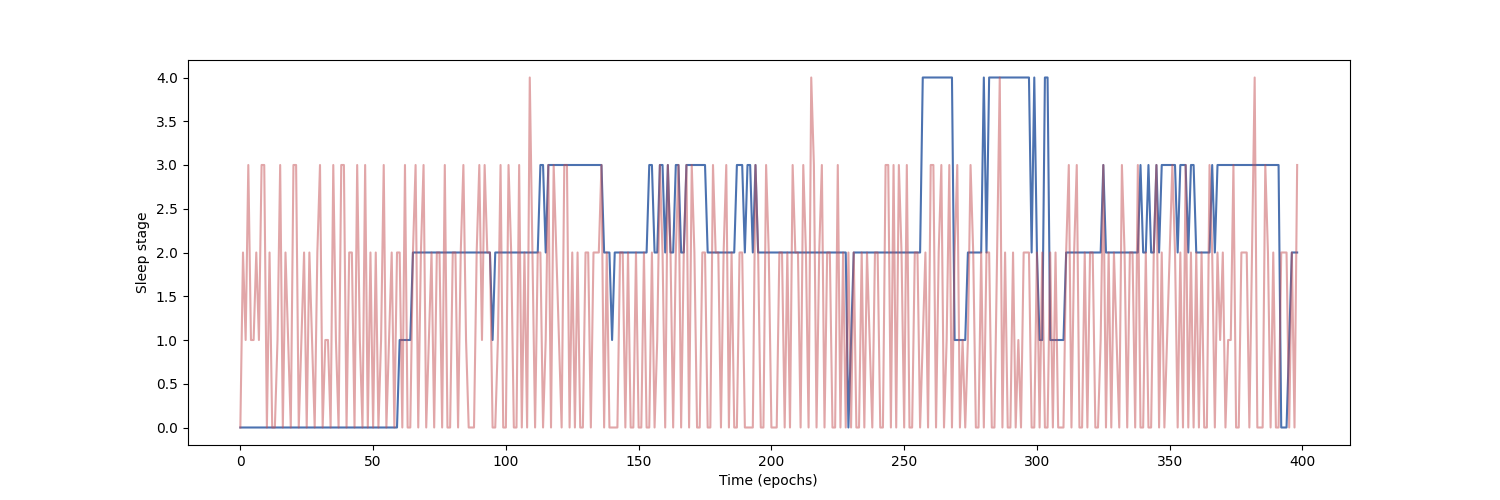
Text(150.22222222222223, 0.5, 'Sleep stage')
Our model was able to learn, as shown by the decreasing training and validation loss values, despite the low amount of data that was available (only two recordings in this example). To further improve performance, more recordings should be included in the training set, the model should be trained for more epochs and hyperparameters should be optimized.
References#
Total running time of the script: (0 minutes 11.250 seconds)
Estimated memory usage: 92 MB