
Note
Go to the end to download the full example code.
Convolutional neural network regression model on fake data.#
This example shows how to create a CNN regressor from a CNN classifier by removing softmax function from the classifier’s output layer and how to train it on a fake regression dataset.
# Authors: Lukas Gemein <l.gemein@gmail.com>
# Sara Sedlar <sara.sedlar@gmail.com>
# License: BSD-3
Fake regression data#
Function for generation of the fake regression dataset generates n_fake_recs recordings,
each containing sinusoidal signals with Gaussian noise. Each fake recording signal has
n_fake_chs channels, it lasts fake_duration [s] and it is sampled with fake_sfreq [Hz].
The recordings are split into train, validation and testing sessions.
import numpy as np
import pandas as pd
from braindecode.datasets import BaseConcatDataset, RawDataset
from braindecode.util import create_mne_dummy_raw
Function for generating fake regression data
def fake_regression_dataset(
n_fake_recs,
n_fake_chs,
fake_sfreq,
fake_duration,
n_fake_targets,
fake_data_split=[0.6, 0.2, 0.2],
):
"""Generate a fake regression dataset.
Parameters
----------
n_fake_recs : int
Number of fake recordings.
n_fake_chs : int
Number of fake EEG channels.
fake_sfreq : float
Fake sampling frequency in Hz.
fake_duration : float
Fake recording duration in seconds.
n_fake_targets : int
Number of targets.
fake_data_split : list
List of train/valid/test subset fractions.
Returns
-------
dataset : BaseConcatDataset object
The generated dataset object.
"""
datasets = []
for i in range(n_fake_recs):
if i < int(fake_data_split[0] * n_fake_recs):
target_subset = "train"
elif i < int((1 - fake_data_split[2]) * n_fake_recs):
target_subset = "valid"
else:
target_subset = "test"
raw, _ = create_mne_dummy_raw(
n_channels=n_fake_chs, n_times=fake_duration * fake_sfreq, sfreq=fake_sfreq
)
target = np.random.randint(0, 10, n_fake_targets)
for j in range(n_fake_targets):
x = np.sin(2 * np.pi * target[j] * raw.times)
raw._data += np.expand_dims(x, axis=0)
if n_fake_targets == 1:
target = target[0]
fake_description = pd.Series(
data=[target, target_subset], index=["target", "session"]
)
datasets.append(RawDataset(raw, fake_description, target_name="target"))
return BaseConcatDataset(datasets)
Generating fake regression dataset#
n_fake_rec = 20
n_fake_chans = 21
fake_sfreq = 100
fake_duration = 30
n_fake_targets = 1
dataset = fake_regression_dataset(
n_fake_recs=n_fake_rec,
n_fake_chs=n_fake_chans,
fake_sfreq=fake_sfreq,
fake_duration=fake_duration,
n_fake_targets=n_fake_targets,
)
Defining a CNN regression model#
Choosing and defining a CNN classifier, ShallowFBCSPNet
or Deep4Net, introduced in [1].
To convert a classifier to a regressor, softmax function is removed from its output layer.
import torch
from braindecode.models import Deep4Net, ShallowFBCSPNet
from braindecode.util import set_random_seeds
# Choosing a CNN model
model_name = "shallow" # 'shallow' or 'deep'
# Defining a CNN model
if model_name in ["shallow", "Shallow", "ShallowConvNet"]:
model = ShallowFBCSPNet(
n_chans=n_fake_chans,
n_outputs=n_fake_targets,
n_times=fake_sfreq * fake_duration,
n_filters_time=40,
n_filters_spat=40,
final_conv_length=35,
)
elif model_name in ["deep", "Deep", "DeepConvNet"]:
model = Deep4Net(
n_chans=n_fake_chans,
n_outputs=n_fake_targets,
n_times=fake_sfreq * fake_duration,
n_filters_time=25,
n_filters_spat=25,
stride_before_pool=True,
n_filters_2=n_fake_chans * 2,
n_filters_3=n_fake_chans * 4,
n_filters_4=n_fake_chans * 8,
final_conv_length=1,
)
else:
raise ValueError(f"{model_name} unknown")
Choosing between GPU and CPU processors#
By default, model’s training and evaluation take place at GPU if it exists, otherwise on CPU.
cuda = torch.cuda.is_available()
device = "cuda" if cuda else "cpu"
if cuda:
torch.backends.cudnn.benchmark = True
# Setting a random seed
seed = 20200220
set_random_seeds(seed=seed, cuda=cuda)
if cuda:
model.cuda()
Data windowing#
Windowing data with a sliding window into the epochs of the size window_size_samples.
from braindecode.preprocessing import create_fixed_length_windows
window_size_samples = fake_sfreq * fake_duration // 3
model.to_dense_prediction_model()
n_preds_per_input = model.get_output_shape()[2]
windows_dataset = create_fixed_length_windows(
dataset,
start_offset_samples=0,
stop_offset_samples=0,
window_size_samples=window_size_samples,
window_stride_samples=n_preds_per_input,
drop_last_window=False,
preload=True,
)
# Splitting windowed data into train, valid and test subsets.
splits = windows_dataset.split("session")
train_set = splits["train"]
valid_set = splits["valid"]
test_set = splits["test"]
Model training#
Model is trained by minimizing MSE loss between ground truth and estimated value averaged over a period of time using AdamW optimizer [2], [3]. Learning rate is managed by CosineAnnealingLR learning rate scheduler.
from skorch.callbacks import LRScheduler
from skorch.helper import predefined_split
from braindecode import EEGRegressor
from braindecode.training.losses import CroppedLoss
batch_size = 4
n_epochs = 3
optimizer_lr = 0.001
optimizer_weight_decay = 0.0
regressor = EEGRegressor(
model,
cropped=True,
criterion=CroppedLoss,
criterion__loss_function=torch.nn.functional.mse_loss,
optimizer=torch.optim.AdamW,
optimizer__lr=optimizer_lr,
optimizer__weight_decay=optimizer_weight_decay,
train_split=predefined_split(valid_set),
iterator_train__shuffle=True,
batch_size=batch_size,
callbacks=[
"neg_root_mean_squared_error",
("lr_scheduler", LRScheduler("CosineAnnealingLR", T_max=n_epochs - 1)),
],
device=device,
)
regressor.fit(train_set, y=None, epochs=n_epochs)
epoch train_loss train_neg_root_mean_squared_error valid_loss valid_neg_root_mean_squared_error lr dur
------- ------------ ----------------------------------- ------------ ----------------------------------- ------ ------
1 23.4097 -1.7297 1.3971 -1.1818 0.0010 0.3869
2 9.9692 -1.4295 0.5755 -0.7583 0.0005 0.3613
3 4.7106 -1.3090 0.5425 -0.7363 0.0000 0.3598
Model evaluation#
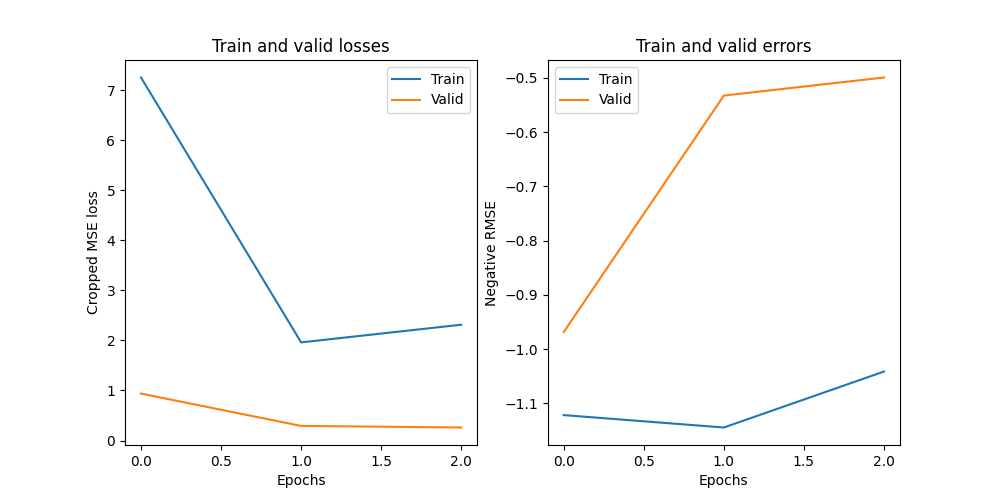
Plotting training and validation losses and negative root mean square error
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].set_title("Train and valid losses")
axes[0].plot(regressor.history[:, "train_loss"])
axes[0].plot(regressor.history[:, "valid_loss"])
axes[0].set_xlabel("Epochs")
axes[0].set_ylabel("Cropped MSE loss")
axes[0].legend(["Train", "Valid"])
axes[1].set_title("Train and valid errors")
axes[1].plot(regressor.history[:, "train_neg_root_mean_squared_error"])
axes[1].plot(regressor.history[:, "valid_neg_root_mean_squared_error"])
axes[1].set_xlabel("Epochs")
axes[1].set_ylabel("Negative RMSE")
axes[1].legend(["Train", "Valid"])
<matplotlib.legend.Legend object at 0x7f607c298e90>
Model testing#
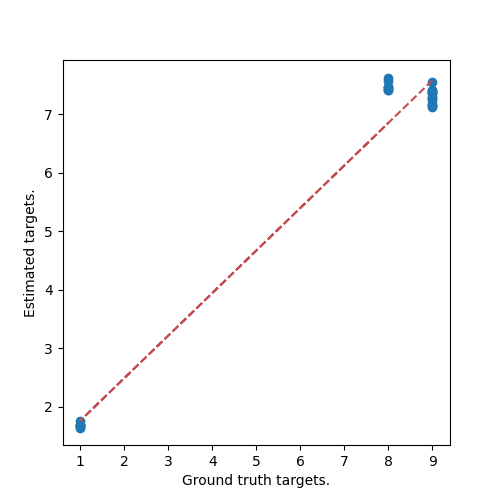
Plotting a scatter plot of estimated versus target values and corresponding trend line.
fig, axes = plt.subplots(1, 1, figsize=(5, 5))
y_estim = np.ravel(regressor.predict(test_set))
y_gt = test_set.get_metadata()["target"].to_numpy()
_ = axes.scatter(y_gt, y_estim)
_ = axes.set_ylabel("Estimated targets.")
_ = axes.set_xlabel("Ground truth targets.")
z = np.polyfit(y_gt, y_estim, 1)
p = np.poly1d(z)
plt.plot(y_gt, p(y_gt), "r--")
plt.show()
References#
Total running time of the script: (0 minutes 6.893 seconds)
Estimated memory usage: 861 MB
Run this example