braindecode.datasets.bids.HubDatasetMixin#
- class braindecode.datasets.bids.HubDatasetMixin[source]#
Mixin class for Hugging Face Hub integration with EEG datasets.
This class adds push_to_hub() and pull_from_hub() methods to BaseConcatDataset, enabling easy upload and download of datasets to/from the Hugging Face Hub.
Examples
>>> # Push dataset to Hub >>> dataset = NMT(path=path, preload=True) >>> dataset.push_to_hub( ... repo_id="username/nmt-dataset", ... ) >>> >>> # Load dataset from Hub >>> dataset = BaseConcatDataset.pull_from_hub("username/nmt-dataset")
Methods
- classmethod pull_from_hub(repo_id, preload=True, token=None, cache_dir=None, force_download=False, **kwargs)[source]#
Load a dataset from the Hugging Face Hub.
- Parameters:
repo_id (
str) – Repository ID on the Hugging Face Hub (e.g., “username/dataset-name”).preload (
bool) – Whether to preload the data into memory. If False, uses lazy loading (when supported by the format).token (
Optional[str]) – Hugging Face API token. If None, uses cached token.cache_dir (
Union[str,Path,None]) – Directory to cache the downloaded dataset. If None, uses default cache directory (~/.cache/huggingface/datasets).force_download (
bool) – Whether to force re-download even if cached.**kwargs – Additional arguments (currently unused).
- Returns:
The loaded dataset.
- Return type:
- Raises:
ImportError – If huggingface-hub is not installed.
FileNotFoundError – If the repository or dataset files are not found.
Examples
>>> from braindecode.datasets import BaseConcatDataset >>> dataset = BaseConcatDataset.pull_from_hub("username/nmt-dataset") >>> print(f"Loaded {len(dataset)} windows") >>> >>> # Use with PyTorch >>> from torch.utils.data import DataLoader >>> loader = DataLoader(dataset, batch_size=32, shuffle=True)
- push_to_hub(repo_id, private=False, token=None, compression='blosc', compression_level=5, pipeline_name='braindecode', chunk_size=5000000, local_cache_dir=None, **kwargs)[source]#
Upload the dataset to the Hugging Face Hub in BIDS-like Zarr format.
The dataset is converted to Zarr format with blosc compression, which provides optimal random access performance for PyTorch training. The data is stored in a BIDS sourcedata-like structure with events.tsv, channels.tsv, and participants.tsv sidecar files.
- Parameters:
repo_id (
str) – Repository ID on the Hugging Face Hub (e.g., “username/dataset-name”).private (
bool) – Whether to create a private repository.token (
Optional[str]) – Hugging Face API token. If None, uses cached token.compression (
str) – Compression algorithm for Zarr. Options: “blosc”, “zstd”, “gzip”, None.compression_level (
int) – Compression level (0-9). Level 5 provides optimal balance.pipeline_name (
str) – Name of the processing pipeline for BIDS sourcedata.chunk_size (
int) – Number of samples per chunk in Zarr along the time/window dimension. Larger chunk sizes create fewer but larger chunks/files. This parameter is used for both continuous data (e.g., RawDataset, EEGWindowsDataset) and pre-cut windows (WindowsDataset). For WindowsDataset, multiple windows may be stored in a single chunk depending on their duration and the chosenchunk_size.local_cache_dir (
str|Path|None) –Local directory to use for temporary files during upload. If None, uses the system temp directory and cleans it up after upload. If provided, the directory is used as a persistent cache:
If the directory is empty (or does not exist), the cache is built there and a lock file (
format_info.json) is written once the cache is complete, before the upload starts. The file contains the zarr conversion parameters as JSON.If the lock file is present and its JSON parameters match the current call, cache creation is skipped and the upload resumes directly (useful for retrying interrupted uploads).
If the lock file is present but its JSON parameters differ from the current call, a
ValueErroris raised.If the directory is non-empty but the lock file is absent, a
ValueErroris raised listing the files found.
**kwargs – Additional arguments passed to huggingface_hub.upload_large_folder().
- Returns:
URL of the uploaded dataset on the Hub.
- Return type:
- Raises:
ImportError – If huggingface-hub is not installed.
ValueError – If the dataset is empty or format is invalid.
Examples
>>> dataset = NMT(path=path, preload=True) >>> # Upload with BIDS-like structure >>> url = dataset.push_to_hub( ... repo_id="myusername/nmt-dataset", ... )
Examples using braindecode.datasets.bids.HubDatasetMixin#
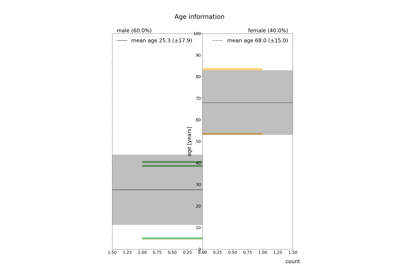
Cleaning EEG Data with EEGPrep for Trialwise Decoding
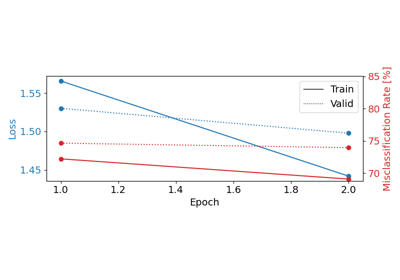
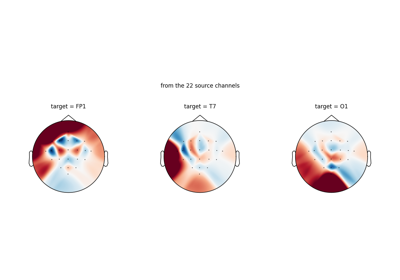
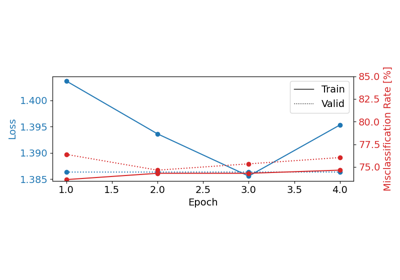
Loading Pretrained Foundation Models on Arbitrary Channel Sets
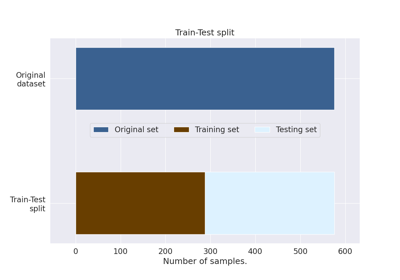
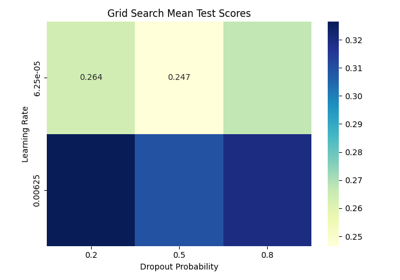

Comprehensive Preprocessing with MNE-based Classes
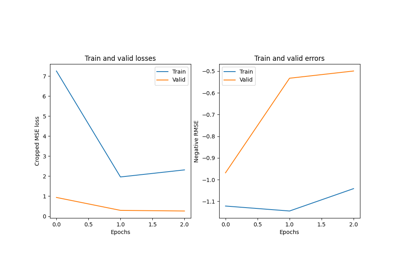
Convolutional neural network regression model on fake data.

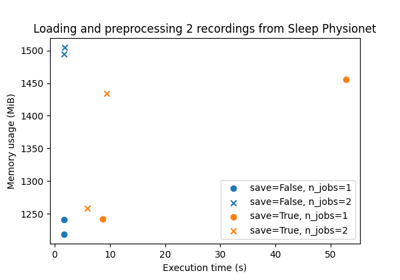
Benchmarking preprocessing with parallelization and serialization

Uploading and downloading datasets to Hugging Face Hub




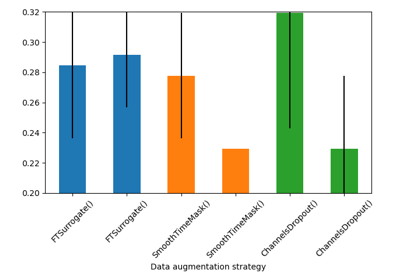
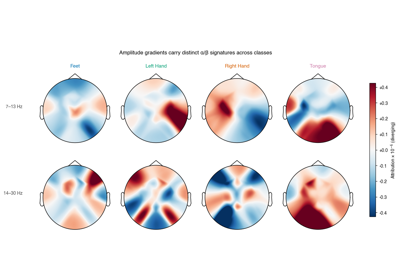
Searching the best data augmentation on BCIC IV 2a Dataset


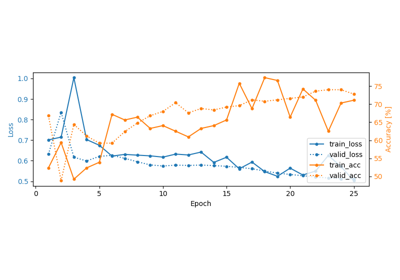
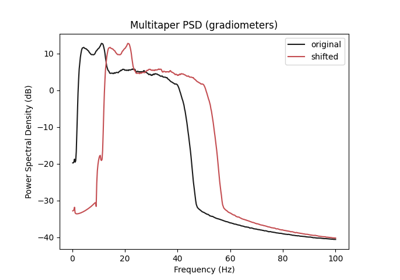
Self-supervised learning on EEG with relative positioning
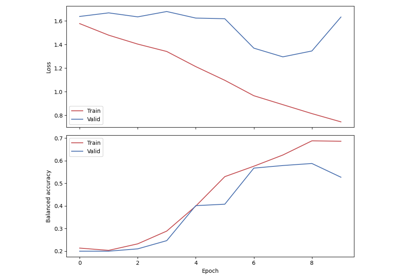
Sleep staging on the Sleep Physionet dataset using Chambon2018 network
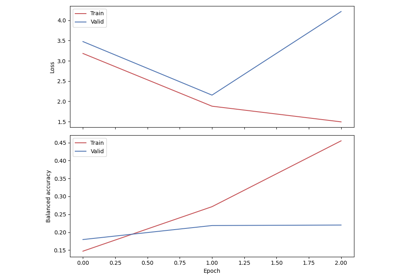
Sleep staging on the Sleep Physionet dataset using Eldele2021
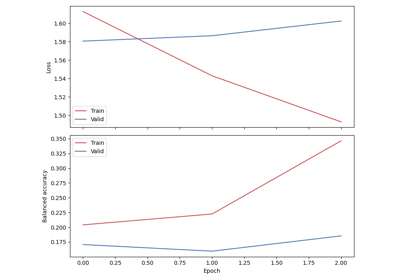
Sleep staging on the Sleep Physionet dataset using U-Sleep network