braindecode.datasets.BaseConcatDataset#
- class braindecode.datasets.BaseConcatDataset(list_of_ds, target_transform=None)[source]#
A base class for concatenated datasets. Holds either mne.Raw or mne.Epoch in self.datasets and has a pandas DataFrame with additional description.
- Parameters
list_of_ds (list) – list of BaseDataset, BaseConcatDataset or WindowsDataset
target_transform (callable | None) – Optional function to call on targets before returning them.
Methods
- get_metadata()[source]#
Concatenate the metadata and description of the wrapped Epochs.
- Returns
metadata – DataFrame containing as many rows as there are windows in the BaseConcatDataset, with the metadata and description information for each window.
- Return type
pd.DataFrame
- save(path, overwrite=False, offset=0)[source]#
Save datasets to files by creating one subdirectory for each dataset: path/
- 0/
0-raw.fif | 0-epo.fif description.json raw_preproc_kwargs.json (if raws were preprocessed) window_kwargs.json (if this is a windowed dataset) window_preproc_kwargs.json (if windows were preprocessed) target_name.json (if target_name is not None and dataset is raw)
- 1/
1-raw.fif | 1-epo.fif description.json raw_preproc_kwargs.json (if raws were preprocessed) window_kwargs.json (if this is a windowed dataset) window_preproc_kwargs.json (if windows were preprocessed) target_name.json (if target_name is not None and dataset is raw)
- Parameters
path (str) –
- Directory in which subdirectories are created to store
-raw.fif | -epo.fif and .json files to.
overwrite (bool) – Whether to delete old subdirectories that will be saved to in this call.
offset (int) – If provided, the integer is added to the id of the dataset in the concat. This is useful in the setting of very large datasets, where one dataset has to be processed and saved at a time to account for its original position.
- set_description(description, overwrite=False)[source]#
Update (add or overwrite) the dataset description.
- split(by=None, property=None, split_ids=None)[source]#
Split the dataset based on information listed in its description DataFrame or based on indices.
- Parameters
by (str | list | dict) – If
byis a string, splitting is performed based on the description DataFrame column with this name. Ifbyis a (list of) list of integers, the position in the first list corresponds to the split id and the integers to the datapoints of that split. If a dict then each key will be used in the returned splits dict and each value should be a list of int.property (str) – Some property which is listed in info DataFrame.
split_ids (list | dict) – List of indices to be combined in a subset. It can be a list of int or a list of list of int.
- Returns
splits – A dictionary with the name of the split (a string) as key and the dataset as value.
- Return type
Examples using braindecode.datasets.BaseConcatDataset#





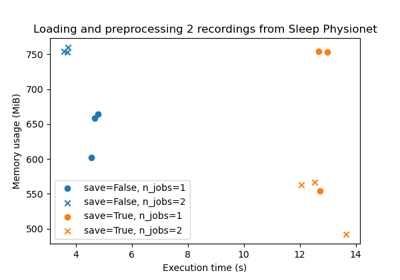
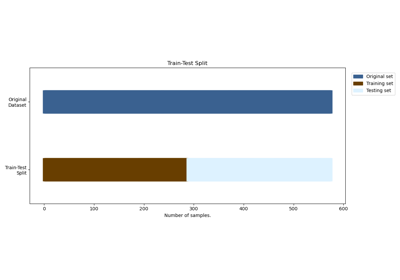
Benchmarking preprocessing with parallelization and serialization



Sleep staging on the Sleep Physionet dataset using U-Sleep network

Sleep staging on the Sleep Physionet dataset using Eldele2021

Sleep staging on the Sleep Physionet dataset using Chambon2018 network

Searching the best data augmentation on BCIC IV 2a Dataset
Fingers flexion decoding on BCIC IV 4 ECoG Dataset
Fingers flexion cropped decoding on BCIC IV 4 ECoG Dataset
Self-supervised learning on EEG with relative positioning