Note
Click here to download the full example code
MOABB Dataset Example#
In this example, we show how to fetch and prepare a MOABB dataset for usage with Braindecode.
# Authors: Lukas Gemein <l.gemein@gmail.com>
# Hubert Banville <hubert.jbanville@gmail.com>
# Simon Brandt <simonbrandt@protonmail.com>
#
# License: BSD (3-clause)
import matplotlib.pyplot as plt
from braindecode.datasets import MOABBDataset
from braindecode.preprocessing import \
create_windows_from_events, create_fixed_length_windows
from braindecode.preprocessing import preprocess, Preprocessor
First, we create a dataset based on BCIC IV 2a fetched with MOABB,
dataset = MOABBDataset(dataset_name="BNCI2014001", subject_ids=[1])
ds has a pandas DataFrame with additional description of its internal datasets
dataset.description
We can iterate through ds which yields one time point of a continuous signal x, and a target y (which can be None if targets are not defined for the entire continuous signal).
(26, 1) None
We can apply preprocessing transforms that are defined in mne and work in-place, such as resampling, bandpass filtering, or electrode selection.
preprocessors = [
Preprocessor('pick_types', eeg=True, meg=False, stim=True),
Preprocessor('resample', sfreq=100)
]
print(dataset.datasets[0].raw.info["sfreq"])
preprocess(dataset, preprocessors)
print(dataset.datasets[0].raw.info["sfreq"])
250.0
100.0
We can easily split ds based on a criteria applied to the description DataFrame:
subsets = dataset.split("session")
print({subset_name: len(subset) for subset_name, subset in subsets.items()})
{'session_E': 232164, 'session_T': 232164}
Next, we use a windower to extract events from the dataset based on events:
windows_dataset = create_windows_from_events(
dataset, trial_start_offset_samples=0, trial_stop_offset_samples=100,
window_size_samples=400, window_stride_samples=100,
drop_last_window=False)
We can iterate through the windows_ds which yields a window x,
a target y, and window_ind (which itself contains i_window_in_trial,
i_start_in_trial, and i_stop_in_trial, which are required for
combining window predictions in the scorer).
for x, y, window_ind in windows_dataset:
print(x.shape, y, window_ind)
break
(23, 400) 3 [0, 300, 700]
We visually inspect the windows:
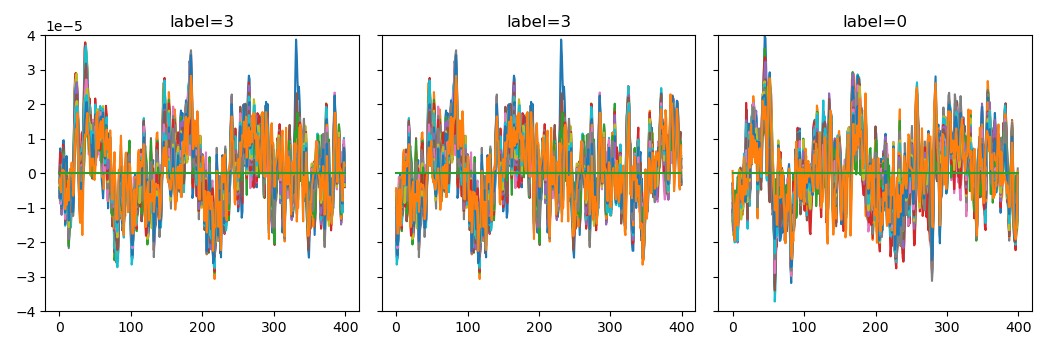
Alternatively, we can create evenly spaced (“sliding”) windows using a different windower.
sliding_windows_dataset = create_fixed_length_windows(
dataset, start_offset_samples=0, stop_offset_samples=0,
window_size_samples=1200, window_stride_samples=1000,
drop_last_window=False)
print(len(sliding_windows_dataset))
for x, y, window_ind in sliding_windows_dataset:
print(x.shape, y, window_ind)
break
sliding_windows_dataset.description
/home/runner/work/braindecode/braindecode/braindecode/preprocessing/windowers.py:603: UserWarning: Meaning of `trial_stop_offset_samples`=0 has changed, use `None` to indicate end of trial/recording. Using `None`.
'Meaning of `trial_stop_offset_samples`=0 has changed, use `None` '
468
(23, 1200) -1 [0, 0, 1200]
Transforms can also be applied on windows in the same way as shown above on continuous data:
def crop_windows(windows, start_offset_samples, stop_offset_samples):
fs = windows.info["sfreq"]
windows.crop(tmin=start_offset_samples / fs, tmax=stop_offset_samples / fs,
include_tmax=False)
epochs_preprocessors = [
Preprocessor('pick_types', eeg=True, meg=False, stim=False),
Preprocessor(crop_windows, apply_on_array=False, start_offset_samples=100,
stop_offset_samples=900)
]
print(windows_dataset.datasets[0].windows.info["ch_names"],
len(windows_dataset.datasets[0].windows.times))
preprocess(windows_dataset, epochs_preprocessors)
print(windows_dataset.datasets[0].windows.info["ch_names"],
len(windows_dataset.datasets[0].windows.times))
max_i = 2
fig, ax_arr = plt.subplots(1, max_i + 1, figsize=(3.5 * (max_i + 1), 3.5),
sharex=True, sharey=True)
for i, (x, y, window_ind) in enumerate(windows_dataset):
ax_arr[i].plot(x.T)
ax_arr[i].set_ylim(-4e-5, 4e-5)
ax_arr[i].set_title(f"label={y}")
if i == max_i:
break
fig.tight_layout()
plt.show()
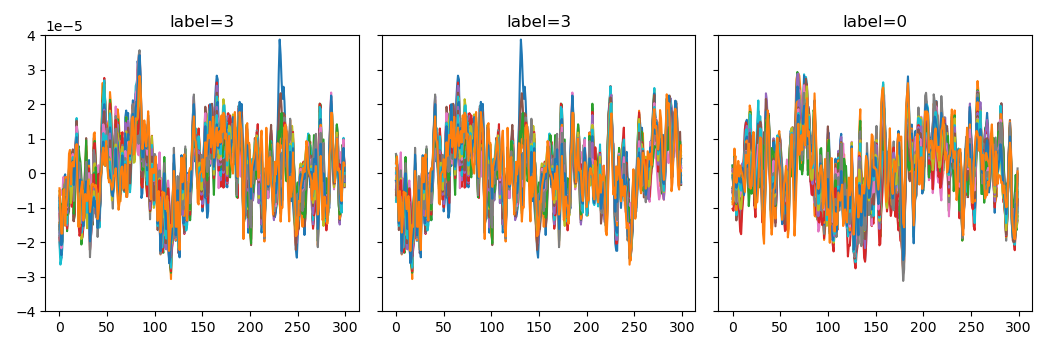
['Fz', 'FC3', 'FC1', 'FCz', 'FC2', 'FC4', 'C5', 'C3', 'C1', 'Cz', 'C2', 'C4', 'C6', 'CP3', 'CP1', 'CPz', 'CP2', 'CP4', 'P1', 'Pz', 'P2', 'POz', 'stim'] 400
['Fz', 'FC3', 'FC1', 'FCz', 'FC2', 'FC4', 'C5', 'C3', 'C1', 'Cz', 'C2', 'C4', 'C6', 'CP3', 'CP1', 'CPz', 'CP2', 'CP4', 'P1', 'Pz', 'P2', 'POz'] 300
Again, we can easily split windows_ds based on some criteria in the description DataFrame:
subsets = windows_dataset.split("session")
print({subset_name: len(subset) for subset_name, subset in subsets.items()})
{'session_E': 576, 'session_T': 576}
Total running time of the script: ( 0 minutes 8.020 seconds)
Estimated memory usage: 371 MB