Note
Click here to download the full example code
Benchmarking preprocessing with parallelization and serialization#
In this example, we compare the execution time and memory requirements of
preprocessing data with the parallelization and serialization functionalities
available in braindecode.preprocessing.preprocess().
We compare 4 cases:
Sequential, no serialization
Sequential, with serialization
Parallel, no serialization
Parallel, with serialization
Case 1 is the simplest approach, in which all recordings in a
braindecode.datasets.BaseConcatDataset are preprocessed one after the
other. In this scenario, braindecode.preprocessing.preprocess() acts
inplace, which means memory usage will likely stay stable (depending on the
preprocessing operations) if recordings have been preloaded. However, two
potential issues arise when working with large datasets: (1) if recordings have
not been preloaded before preprocessing, preprocess() will need to load them
and keep them in memory, in which case memory can become a bottleneck, and (2)
sequential preprocessing can take a considerable amount of time to run when
working with many recordings.
A solution to the first issue (memory usage) is to save the preprocessed data
to a file so it can be cleared from memory before moving on to the next
recording (case 2). The recordings can then be reloaded with preload=False
once they have all been saved to disk. This enables using the lazy loading
capabilities of braindecode.datasets.BaseConcatDataset and avoids
potential memory bottlenecks. The downside is that the writing to disk can take
some time and of course requires disk space.
A solution to the second issue (slow preprocessing) is to parallelize the preprocessing over multiple cores whenever possible (case 3). This can speed up preprocessing significantly. However, this approach will increase memory usage because of the way parallelization is implemented internally (with joblib, copies of (part of) the data must be made when sending arguments to parallel processes).
Finally, case 4 (combining parallelization and serialization) is likely to be both fast and memory efficient. As shown in this example, this remains a tradeoff though, and the selected configuration should depend on the size of the dataset and the specific operations applied to the recordings.
# Authors: Hubert Banville <hubert.jbanville@gmail.com>
#
# License: BSD (3-clause)
import time
import tempfile
from itertools import product
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import scale
from memory_profiler import memory_usage
from braindecode.datasets import SleepPhysionet
from braindecode.preprocessing import (
preprocess, Preprocessor, create_fixed_length_windows)
We create a function that goes through the usual three steps of data
preparation: (1) data loading, (2) continuous data preprocessing,
(3) windowing and (4) windowed data preprocessing. We use the
braindecode.datasets.SleepPhysionet dataset for testing purposes.
def prepare_data(n_recs, save, preload, n_jobs):
if save:
tmp_dir = tempfile.TemporaryDirectory()
save_dir = tmp_dir.name
else:
save_dir = None
# (1) Load the data
concat_ds = SleepPhysionet(
subject_ids=range(n_recs), recording_ids=[1], crop_wake_mins=30,
preload=preload)
sfreq = concat_ds.datasets[0].raw.info['sfreq']
# (2) Preprocess the continuous data
preprocessors = [
Preprocessor('crop', tmin=10),
Preprocessor('filter', l_freq=None, h_freq=30)
]
preprocess(concat_ds, preprocessors, save_dir=save_dir, overwrite=True,
n_jobs=n_jobs)
# (3) Window the data
windows_ds = create_fixed_length_windows(
concat_ds, 0, None, int(30 * sfreq), int(30 * sfreq), True,
preload=preload, n_jobs=n_jobs)
# Preprocess the windowed data
preprocessors = [Preprocessor(scale, channel_wise=True)]
preprocess(windows_ds, preprocessors, save_dir=save_dir, overwrite=True,
n_jobs=n_jobs)
Next, we can run our function and measure its run time and peak memory usage for each one of our 4 cases above. We call the function multiple times with each configuration to get better estimates.
Note
To better characterize the run time vs. memory usage tradeoff for your specific configuration (as this will differ based on available hardware, data size and preprocessing operations), we recommend adapting this example to your use case and running it on your machine.
n_repets = 3 # Number of repetitions
all_n_recs = 2 # Number of recordings to load and preprocess
all_n_jobs = [1, 2] # Number of parallel processes
results = list()
for _, n_recs, save, n_jobs in product(
range(n_repets), [all_n_recs], [True, False], all_n_jobs):
start = time.time()
mem = max(memory_usage(
proc=(prepare_data, [n_recs, save, False, n_jobs], {})))
time_taken = time.time() - start
results.append({
'n_recs': n_recs,
'max_mem': mem,
'save': save,
'n_jobs': n_jobs,
'time': time_taken
})
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpwtuxpqt6 contains other subdirectories or files ['0'].
warnings.warn(f'Chosen directory {path} contains other '
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:570: UserWarning: The number of saved datasets (1) does not match the number of existing subdirectories (2). You may now encounter a mix of differently preprocessed datasets!
f"datasets!", UserWarning)
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpwtuxpqt6 contains other subdirectories or files ['1'].
warnings.warn(f'Chosen directory {path} contains other '
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpwtuxpqt6 contains other subdirectories or files ['0'].
warnings.warn(f'Chosen directory {path} contains other '
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpn9t88czc contains other subdirectories or files ['0'].
warnings.warn(f'Chosen directory {path} contains other '
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:570: UserWarning: The number of saved datasets (1) does not match the number of existing subdirectories (2). You may now encounter a mix of differently preprocessed datasets!
f"datasets!", UserWarning)
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpn9t88czc contains other subdirectories or files ['1'].
warnings.warn(f'Chosen directory {path} contains other '
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpn9t88czc contains other subdirectories or files ['0'].
warnings.warn(f'Chosen directory {path} contains other '
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpkb3dhgyi contains other subdirectories or files ['0'].
warnings.warn(f'Chosen directory {path} contains other '
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:570: UserWarning: The number of saved datasets (1) does not match the number of existing subdirectories (2). You may now encounter a mix of differently preprocessed datasets!
f"datasets!", UserWarning)
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpkb3dhgyi contains other subdirectories or files ['1'].
warnings.warn(f'Chosen directory {path} contains other '
/home/runner/work/braindecode/braindecode/braindecode/datasets/base.py:574: UserWarning: Chosen directory /tmp/tmpkb3dhgyi contains other subdirectories or files ['0'].
warnings.warn(f'Chosen directory {path} contains other '
Finally, we can plot the results:
df = pd.DataFrame(results)
fig, ax = plt.subplots(figsize=(6, 4))
colors = {True: 'tab:orange', False: 'tab:blue'}
markers = {n: m for n, m in zip(all_n_jobs, ['o', 'x', '.'])}
for (save, n_jobs), sub_df in df.groupby(['save', 'n_jobs']):
ax.scatter(x=sub_df['time'], y=sub_df['max_mem'], color=colors[save],
marker=markers[n_jobs], label=f'save={save}, n_jobs={n_jobs}')
ax.legend()
ax.set_xlabel('Execution time (s)')
ax.set_ylabel('Memory usage (MiB)')
ax.set_title(f'Loading and preprocessing {all_n_recs} recordings from Sleep '
'Physionet')
plt.show()
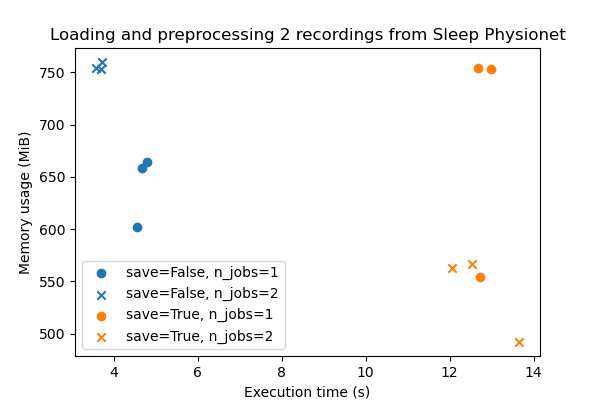
We see that parallel preprocessing without serialization (blue crosses) is faster than simple sequential processing (blue circles), however it uses more memory.
Combining parallel preprocessing and serialization (orange crosses) reduces memory usage significantly, however it increases run time by a few seconds. Depending on available resources (e.g. in limited memory settings), it might therefore be more advantageous to use both parallelization and serialization together.
Total running time of the script: ( 1 minutes 42.156 seconds)
Estimated memory usage: 441 MB