braindecode.models package#
Some predefined network architectures for EEG decoding.
Submodules#
braindecode.models.atcnet module#
- class braindecode.models.atcnet.ATCNet(n_chans=None, n_outputs=None, input_window_seconds=None, sfreq=250.0, conv_block_n_filters=16, conv_block_kernel_length_1=64, conv_block_kernel_length_2=16, conv_block_pool_size_1=8, conv_block_pool_size_2=7, conv_block_depth_mult=2, conv_block_dropout=0.3, n_windows=5, att_head_dim=8, att_num_heads=2, att_drop_prob=0.5, tcn_depth=2, tcn_kernel_size=4, tcn_n_filters=32, tcn_drop_prob=0.3, tcn_activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, concat=False, max_norm_const=0.25, chs_info=None, n_times=None)[source]#
Bases:
EEGModuleMixin,ModuleATCNet model from Altaheri et al. (2022) [1]
Pytorch implementation based on official tensorflow code [2].

- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
input_window_seconds (float, optional) – Time length of inputs, in seconds. Defaults to 4.5 s, as in BCI-IV 2a dataset.
sfreq (int, optional) – Sampling frequency of the inputs, in Hz. Default to 250 Hz, as in BCI-IV 2a dataset.
conv_block_n_filters (int) – Number temporal filters in the first convolutional layer of the convolutional block, denoted F1 in figure 2 of the paper [1]. Defaults to 16 as in [1].
conv_block_kernel_length_1 (int) – Length of temporal filters in the first convolutional layer of the convolutional block, denoted Kc in table 1 of the paper [1]. Defaults to 64 as in [1].
conv_block_kernel_length_2 (int) – Length of temporal filters in the last convolutional layer of the convolutional block. Defaults to 16 as in [1].
conv_block_pool_size_1 (int) – Length of first average pooling kernel in the convolutional block. Defaults to 8 as in [1].
conv_block_pool_size_2 (int) – Length of first average pooling kernel in the convolutional block, denoted P2 in table 1 of the paper [1]. Defaults to 7 as in [1].
conv_block_depth_mult (int) – Depth multiplier of depthwise convolution in the convolutional block, denoted D in table 1 of the paper [1]. Defaults to 2 as in [1].
conv_block_dropout (float) – Dropout probability used in the convolution block, denoted pc in table 1 of the paper [1]. Defaults to 0.3 as in [1].
n_windows (int) – Number of sliding windows, denoted n in [1]. Defaults to 5 as in [1].
att_head_dim (int) – Embedding dimension used in each self-attention head, denoted dh in table 1 of the paper [1]. Defaults to 8 as in [1].
att_num_heads (int) – Number of attention heads, denoted H in table 1 of the paper [1]. Defaults to 2 as in [1].
att_drop_prob – The description is missing.
tcn_depth (int) – Depth of Temporal Convolutional Network block (i.e. number of TCN Residual blocks), denoted L in table 1 of the paper [1]. Defaults to 2 as in [1].
tcn_kernel_size (int) – Temporal kernel size used in TCN block, denoted Kt in table 1 of the paper [1]. Defaults to 4 as in [1].
tcn_n_filters (int) – Number of filters used in TCN convolutional layers (Ft). Defaults to 32 as in [1].
tcn_drop_prob – The description is missing.
tcn_activation (torch.nn.Module) – Nonlinear activation to use. Defaults to nn.ELU().
concat (bool) – When
True, concatenates each slidding window embedding before feeding it to a fully-connected layer, as done in [1]. WhenFalse, maps each slidding window to n_outputs logits and average them. Defaults toFalsecontrary to what is reported in [1], but matching what the official code does [2].max_norm_const (float) – Maximum L2-norm constraint imposed on weights of the last fully-connected layer. Defaults to 0.25.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[1] (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26)H. Altaheri, G. Muhammad and M. Alsulaiman, Physics-informed attention temporal convolutional network for EEG-based motor imagery classification in IEEE Transactions on Industrial Informatics, 2022, doi: 10.1109/TII.2022.3197419.
- forward(X)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
X – The description is missing.
braindecode.models.attentionbasenet module#
- class braindecode.models.attentionbasenet.AttentionBaseNet(n_times=None, n_chans=None, n_outputs=None, chs_info=None, sfreq=None, input_window_seconds=None, n_temporal_filters: int = 40, temp_filter_length_inp: int = 25, spatial_expansion: int = 1, pool_length_inp: int = 75, pool_stride_inp: int = 15, drop_prob_inp: float = 0.5, ch_dim: int = 16, temp_filter_length: int = 15, pool_length: int = 8, pool_stride: int = 8, drop_prob_attn: float = 0.5, attention_mode: str | None = None, reduction_rate: int = 4, use_mlp: bool = False, freq_idx: int = 0, n_codewords: int = 4, kernel_size: int = 9, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, extra_params: bool = False)[source]#
Bases:
EEGModuleMixin,ModuleAttentionBaseNet from Wimpff M et al. (2023) [Martin2023].

Neural Network from the paper: EEG motor imagery decoding: A framework for comparative analysis with channel attention mechanisms
The paper and original code with more details about the methodological choices are available at the [Martin2023] and [MartinCode].
The AttentionBaseNet architecture is composed of four modules: - Input Block that performs a temporal convolution and a spatial convolution. - Channel Expansion that modifies the number of channels. - An attention block that performs channel attention with several options - ClassificationHead
Added in version 0.9.
- Parameters:
n_times (int) – Number of time samples of the input window.
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.sfreq (float) – Sampling frequency of the EEG recordings.
input_window_seconds (float) – Length of the input window in seconds.
n_temporal_filters (int, optional) – Number of temporal convolutional filters in the first layer. This defines the number of output channels after the temporal convolution. Default is 40.
temp_filter_length_inp – The description is missing.
spatial_expansion (int, optional) – Multiplicative factor to expand the spatial dimensions. Used to increase the capacity of the model by expanding spatial features. Default is 1.
pool_length_inp (int, optional) – Length of the pooling window in the input layer. Determines how much temporal information is aggregated during pooling. Default is 75.
pool_stride_inp (int, optional) – Stride of the pooling operation in the input layer. Controls the downsampling factor in the temporal dimension. Default is 15.
drop_prob_inp (float, optional) – Dropout rate applied after the input layer. This is the probability of zeroing out elements during training to prevent overfitting. Default is 0.5.
ch_dim (int, optional) – Number of channels in the subsequent convolutional layers. This controls the depth of the network after the initial layer. Default is 16.
temp_filter_length (int, default=15) – The length of the temporal filters in the convolutional layers.
pool_length (int, default=8) – The length of the window for the average pooling operation.
pool_stride (int, default=8) – The stride of the average pooling operation.
drop_prob_attn (float, default=0.5) – The dropout rate for regularization for the attention layer. Values should be between 0 and 1.
attention_mode (str, optional) – The type of attention mechanism to apply. If None, no attention is applied. - “se” for Squeeze-and-excitation network - “gsop” for Global Second-Order Pooling - “fca” for Frequency Channel Attention Network - “encnet” for context encoding module - “eca” for Efficient channel attention for deep convolutional neural networks - “ge” for Gather-Excite - “gct” for Gated Channel Transformation - “srm” for Style-based Recalibration Module - “cbam” for Convolutional Block Attention Module - “cat” for Learning to collaborate channel and temporal attention from multi-information fusion - “catlite” for Learning to collaborate channel attention from multi-information fusion (lite version, cat w/o temporal attention)
reduction_rate (int, default=4) – The reduction rate used in the attention mechanism to reduce dimensionality and computational complexity.
use_mlp (bool, default=False) – Flag to indicate whether an MLP (Multi-Layer Perceptron) should be used within the attention mechanism for further processing.
freq_idx (int, default=0) – DCT index used in fca attention mechanism.
n_codewords (int, default=4) – The number of codewords (clusters) used in attention mechanisms that employ quantization or clustering strategies.
kernel_size (int, default=9) – The kernel size used in certain types of attention mechanisms for convolution operations.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.extra_params (bool, default=False) – Flag to indicate whether additional, custom parameters should be passed to the attention mechanism.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Martin2023] (1,2)Wimpff, M., Gizzi, L., Zerfowski, J. and Yang, B., 2023. EEG motor imagery decoding: A framework for comparative analysis with channel attention mechanisms. arXiv preprint arXiv:2310.11198.
[MartinCode]Wimpff, M., Gizzi, L., Zerfowski, J. and Yang, B. GitHub martinwimpff/channel-attention (accessed 2024-03-28)
- forward(x)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
x – The description is missing.
- braindecode.models.attentionbasenet.get_attention_block(attention_mode: str, ch_dim: int = 16, reduction_rate: int = 4, use_mlp: bool = False, seq_len: int | None = None, freq_idx: int = 0, n_codewords: int = 4, kernel_size: int = 9, extra_params: bool = False)[source]#
Util function to the attention block based on the attention mode.
- Parameters:
attention_mode (str) – The type of attention mechanism to apply.
ch_dim (int) – The number of input channels to the block.
reduction_rate (int) – The reduction rate used in the attention mechanism to reduce dimensionality and computational complexity. Used in all the methods, except for the encnet and eca.
use_mlp (bool) – Flag to indicate whether an MLP (Multi-Layer Perceptron) should be used within the attention mechanism for further processing. Used in the ge and srm attention mechanism.
seq_len (int) – The sequence length, used in certain types of attention mechanisms to process temporal dimensions. Used in the ge or fca attention mechanism.
freq_idx (int) – DCT index used in fca attention mechanism.
n_codewords (int) – The number of codewords (clusters) used in attention mechanisms that employ quantization or clustering strategies, encnet.
kernel_size (int) – The kernel size used in certain types of attention mechanisms for convolution operations, used in the cbam, eca, and cat attention mechanisms.
extra_params (bool) – Parameter to pass additional parameters to the GatherExcite mechanism.
- Returns:
The attention block based on the attention mode.
- Return type:
nn.Module
braindecode.models.base module#
- class braindecode.models.base.EEGModuleMixin(n_outputs: int | None = None, n_chans: int | None = None, chs_info=None, n_times: int | None = None, input_window_seconds: float | None = None, sfreq: float | None = None)[source]#
Bases:
objectMixin class for all EEG models in braindecode.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
- get_output_shape() tuple[int, ...][source]#
Returns shape of neural network output for batch size equal 1.
- get_torchinfo_statistics(col_names: Iterable[str] | None = ('input_size', 'output_size', 'num_params', 'kernel_size'), row_settings: Iterable[str] | None = ('var_names', 'depth')) ModelStatistics[source]#
Generate table describing the model using torchinfo.summary.
- Parameters:
col_names (tuple, optional) – Specify which columns to show in the output, see torchinfo for details, by default (“input_size”, “output_size”, “num_params”, “kernel_size”)
row_settings (tuple, optional) – Specify which features to show in a row, see torchinfo for details, by default (“var_names”, “depth”)
- Returns:
ModelStatistics generated by torchinfo.summary.
- Return type:
torchinfo.ModelStatistics
- to_dense_prediction_model(axis: tuple[int, ...] | int = (2, 3)) None[source]#
Transform a sequential model with strides to a model that outputs dense predictions by removing the strides and instead inserting dilations. Modifies model in-place.
- Parameters:
axis (int or (int,int)) – Axis to transform (in terms of intermediate output axes) can either be 2, 3, or (2,3).
Notes
Does not yet work correctly for average pooling. Prior to version 0.1.7, there had been a bug that could move strides backwards one layer.
braindecode.models.biot module#
- class braindecode.models.biot.BIOT(emb_size=256, att_num_heads=8, n_layers=4, sfreq=200, hop_length=100, return_feature=False, n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, drop_prob: float = 0.5)[source]#
Bases:
EEGModuleMixin,ModuleBIOT from Yang et al. (2023) [Yang2023]
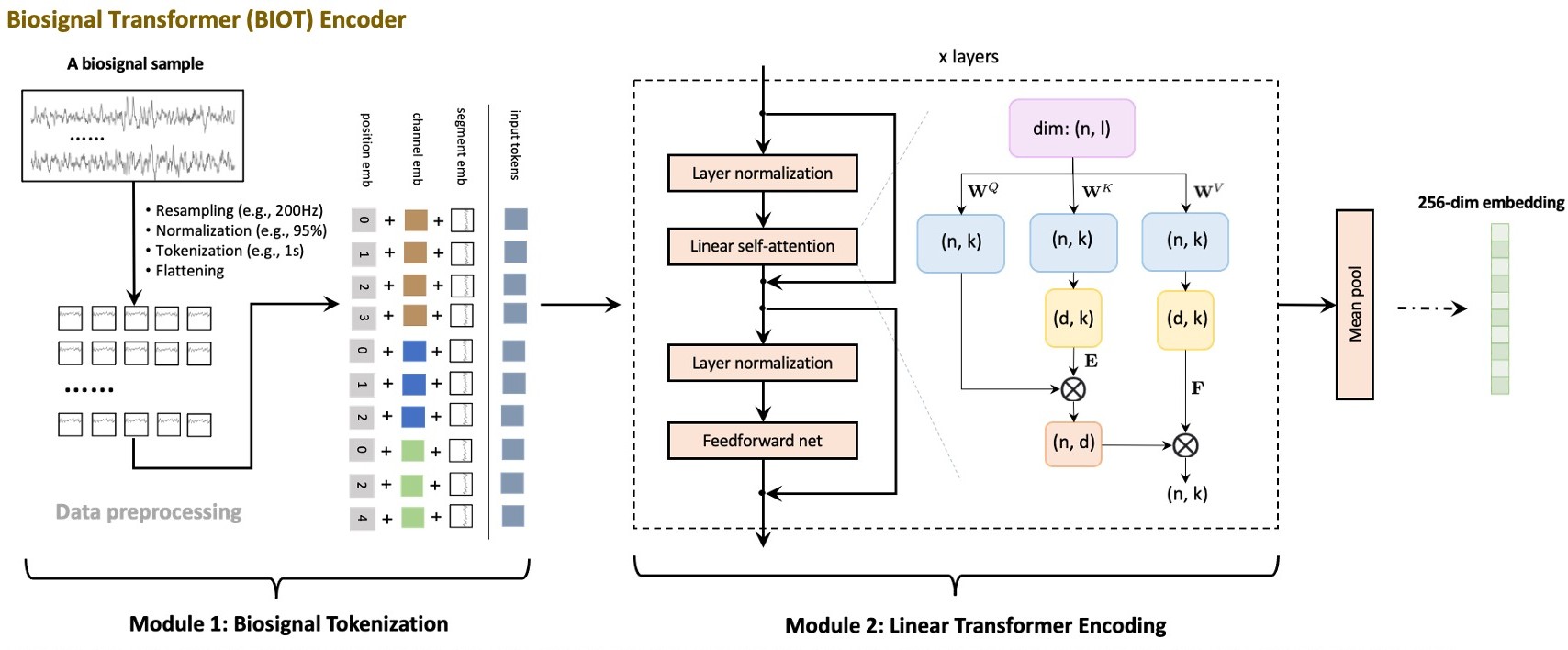
BIOT: Cross-data Biosignal Learning in the Wild.
BIOT is a large language model for biosignal classification. It is a wrapper around the BIOTEncoder and ClassificationHead modules.
It is designed for N-dimensional biosignal data such as EEG, ECG, etc. The method was proposed by Yang et al. [Yang2023] and the code is available at [Code2023]
The model is trained with a contrastive loss on large EEG datasets TUH Abnormal EEG Corpus with 400K samples and Sleep Heart Health Study 5M. Here, we only provide the model architecture, not the pre-trained weights or contrastive loss training.
The architecture is based on the LinearAttentionTransformer and PatchFrequencyEmbedding modules. The BIOTEncoder is a transformer that takes the input data and outputs a fixed-size representation of the input data. More details are present in the BIOTEncoder class.
The ClassificationHead is an ELU activation layer, followed by a simple linear layer that takes the output of the BIOTEncoder and outputs the classification probabilities.
Added in version 0.9.
- Parameters:
emb_size (int, optional) – The size of the embedding layer, by default 256
att_num_heads (int, optional) – The number of attention heads, by default 8
n_layers (int, optional) – The number of transformer layers, by default 4
sfreq (int, optional) – The sfreq parameter for the encoder. The default is 200
hop_length (int, optional) – The hop length for the torch.stft transformation in the encoder. The default is 100.
return_feature (bool, optional) – Changing the output for the neural network. Default is single tensor when return_feature is True, return embedding space too. Default is False.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.drop_prob – The description is missing.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Yang2023] (1,2)Yang, C., Westover, M.B. and Sun, J., 2023, November. BIOT: Biosignal Transformer for Cross-data Learning in the Wild. In Thirty-seventh Conference on Neural Information Processing Systems, NeurIPS.
[Code2023]Yang, C., Westover, M.B. and Sun, J., 2023. BIOT Biosignal Transformer for Cross-data Learning in the Wild. GitHub ycq091044/BIOT (accessed 2024-02-13)
braindecode.models.contrawr module#
- class braindecode.models.contrawr.ContraWR(n_chans=None, n_outputs=None, sfreq=None, emb_size: int = 256, res_channels: list[int] = [32, 64, 128], steps=20, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, drop_prob: float = 0.5, chs_info=None, n_times=None, input_window_seconds=None)[source]#
Bases:
EEGModuleMixin,ModuleContrast with the World Representation ContraWR from Yang et al (2021) [Yang2021].
This model is a convolutional neural network that uses a spectral representation with a series of convolutional layers and residual blocks. The model is designed to learn a representation of the EEG signal that can be used for sleep staging.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
sfreq (float) – Sampling frequency of the EEG recordings.
emb_size (int, optional) – Embedding size for the final layer, by default 256.
res_channels (list[int], optional) – Number of channels for each residual block, by default [32, 64, 128].
steps (int, optional) – Number of steps to take the frequency decomposition hop_length parameters by default 20.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.drop_prob (float, default=0.5) – The dropout rate for regularization. Values should be between 0 and 1.
versionadded: (..) – 0.9:
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors. The modifications are minimal and the model is expected to work as intended. the original code from [Code2023].
References
[Yang2021]Yang, C., Xiao, C., Westover, M. B., & Sun, J. (2023). Self-supervised electroencephalogram representation learning for automatic sleep staging: model development and evaluation study. JMIR AI, 2(1), e46769.
[Code2023]Yang, C., Westover, M.B. and Sun, J., 2023. BIOT Biosignal Transformer for Cross-data Learning in the Wild. GitHub ycq091044/BIOT (accessed 2024-02-13)
braindecode.models.ctnet module#
CTNet: a convolutional transformer network for EEG-based motor imagery classification from Wei Zhao et al. (2024).
- class braindecode.models.ctnet.CTNet(n_outputs=None, n_chans=None, sfreq=None, chs_info=None, n_times=None, input_window_seconds=None, activation_patch: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, activation_transformer: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.GELU'>, drop_prob_cnn: float = 0.3, drop_prob_posi: float = 0.1, drop_prob_final: float = 0.5, heads: int = 4, emb_size: int = 40, depth: int = 6, n_filters_time: int = 20, kernel_size: int = 64, depth_multiplier: int = 2, pool_size_1: int = 8, pool_size_2: int = 8)[source]#
Bases:
EEGModuleMixin,ModuleCTNet from Zhao, W et al (2024) [ctnet].
A Convolutional Transformer Network for EEG-Based Motor Imagery Classification
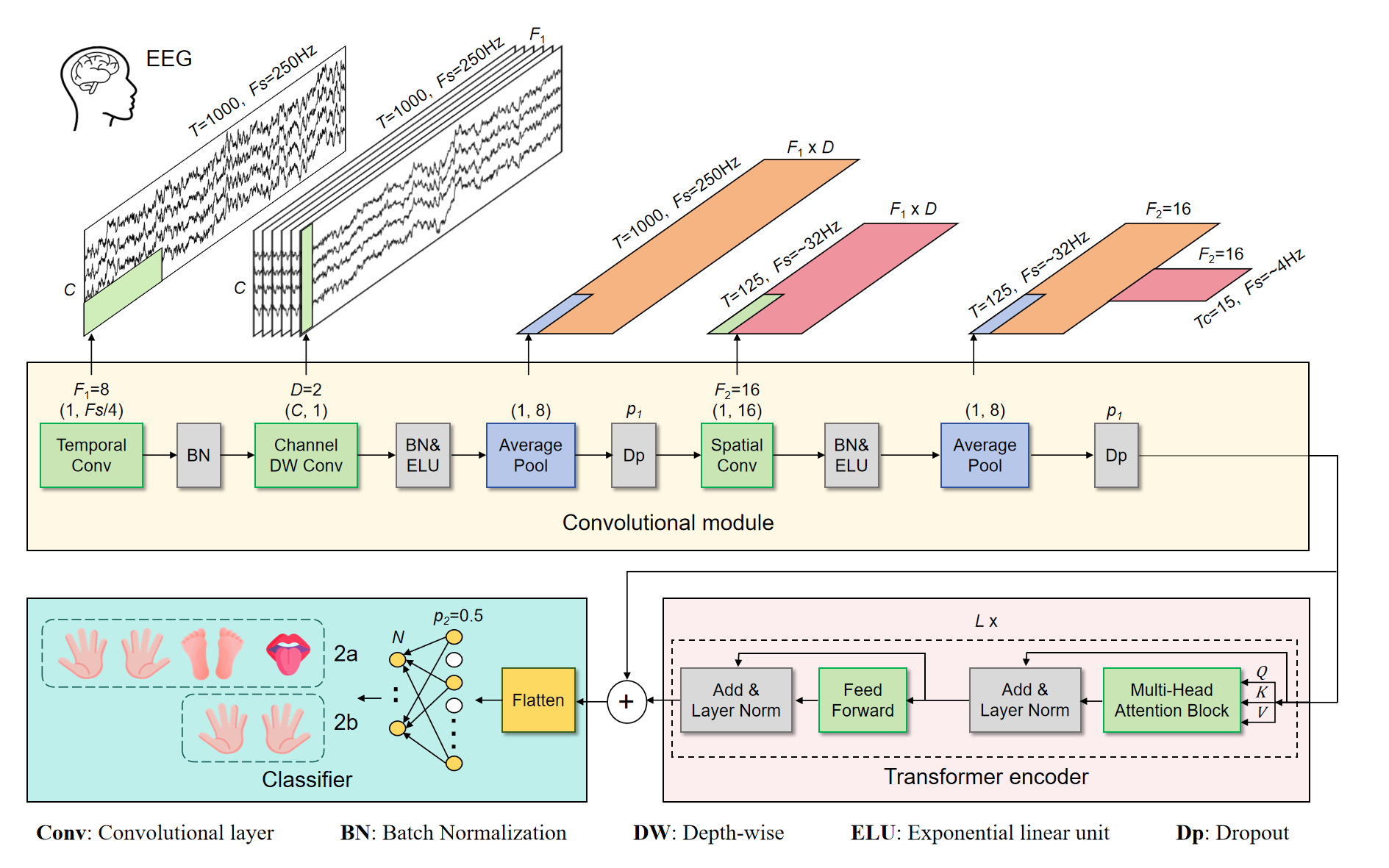
CTNet is an end-to-end neural network architecture designed for classifying motor imagery (MI) tasks from EEG signals. The model combines convolutional neural networks (CNNs) with a Transformer encoder to capture both local and global temporal dependencies in the EEG data.
The architecture consists of three main components:
- Convolutional Module:
Apply EEGNetV4 to perform some feature extraction, denoted here as
_PatchEmbeddingEEGNet module.
- Transformer Encoder Module:
Utilizes multi-head self-attention mechanisms as EEGConformer but
with residual blocks.
- Classifier Module:
Combines features from both the convolutional module
and the Transformer encoder. - Flattens the combined features and applies dropout for regularization. - Uses a fully connected layer to produce the final classification output.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
sfreq (float) – Sampling frequency of the EEG recordings.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
activation_patch – The description is missing.
activation_transformer – The description is missing.
drop_prob_cnn (float, default=0.3) – Dropout probability after convolutional layers.
drop_prob_posi (float, default=0.1) – Dropout probability for the positional encoding in the Transformer.
drop_prob_final (float, default=0.5) – Dropout probability before the final classification layer.
heads (int, default=4) – Number of attention heads in the Transformer encoder.
emb_size (int, default=40) – Embedding size (dimensionality) for the Transformer encoder.
depth (int, default=6) – Number of encoder layers in the Transformer.
n_filters_time (int, default=20) – Number of temporal filters in the first convolutional layer.
kernel_size (int, default=64) – Kernel size for the temporal convolutional layer.
depth_multiplier (int, default=2) – Multiplier for the number of depth-wise convolutional filters.
pool_size_1 (int, default=8) – Pooling size for the first average pooling layer.
pool_size_2 (int, default=8) – Pooling size for the second average pooling layer.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is adapted from the original CTNet source code [ctnetcode] to comply with Braindecode’s model standards.
References
[ctnet]Zhao, W., Jiang, X., Zhang, B., Xiao, S., & Weng, S. (2024). CTNet: a convolutional transformer network for EEG-based motor imagery classification. Scientific Reports, 14(1), 20237.
[ctnetcode]Zhao, W., Jiang, X., Zhang, B., Xiao, S., & Weng, S. (2024). CTNet source code: snailpt/CTNet
braindecode.models.deep4 module#
- class braindecode.models.deep4.Deep4Net(n_chans=None, n_outputs=None, n_times=None, final_conv_length='auto', n_filters_time=25, n_filters_spat=25, filter_time_length=10, pool_time_length=3, pool_time_stride=3, n_filters_2=50, filter_length_2=10, n_filters_3=100, filter_length_3=10, n_filters_4=200, filter_length_4=10, activation_first_conv_nonlin: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, first_pool_mode='max', first_pool_nonlin: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.linear.Identity'>, activation_later_conv_nonlin: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, later_pool_mode='max', later_pool_nonlin: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.linear.Identity'>, drop_prob=0.5, split_first_layer=True, batch_norm=True, batch_norm_alpha=0.1, stride_before_pool=False, chs_info=None, input_window_seconds=None, sfreq=None)[source]#
Bases:
EEGModuleMixin,SequentialDeep ConvNet model from Schirrmeister et al (2017) [Schirrmeister2017].

Model described in [Schirrmeister2017].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
final_conv_length (int | str) – Length of the final convolution layer. If set to “auto”, n_times must not be None. Default: “auto”.
n_filters_time (int) – Number of temporal filters.
n_filters_spat (int) – Number of spatial filters.
filter_time_length (int) – Length of the temporal filter in layer 1.
pool_time_length (int) – Length of temporal pooling filter.
pool_time_stride (int) – Length of stride between temporal pooling filters.
n_filters_2 (int) – Number of temporal filters in layer 2.
filter_length_2 (int) – Length of the temporal filter in layer 2.
n_filters_3 (int) – Number of temporal filters in layer 3.
filter_length_3 (int) – Length of the temporal filter in layer 3.
n_filters_4 (int) – Number of temporal filters in layer 4.
filter_length_4 (int) – Length of the temporal filter in layer 4.
activation_first_conv_nonlin (nn.Module, default is nn.ELU) – Non-linear activation function to be used after convolution in layer 1.
first_pool_mode (str) – Pooling mode in layer 1. “max” or “mean”.
first_pool_nonlin (callable) – Non-linear activation function to be used after pooling in layer 1.
activation_later_conv_nonlin (nn.Module, default is nn.ELU) – Non-linear activation function to be used after convolution in later layers.
later_pool_mode (str) – Pooling mode in later layers. “max” or “mean”.
later_pool_nonlin (callable) – Non-linear activation function to be used after pooling in later layers.
drop_prob (float) – Dropout probability.
split_first_layer (bool) – Split first layer into temporal and spatial layers (True) or just use temporal (False). There would be no non-linearity between the split layers.
batch_norm (bool) – Whether to use batch normalisation.
batch_norm_alpha (float) – Momentum for BatchNorm2d.
stride_before_pool (bool) – Stride before pooling.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Schirrmeister2017] (1,2)Schirrmeister, R. T., Springenberg, J. T., Fiederer, L. D. J., Glasstetter, M., Eggensperger, K., Tangermann, M., Hutter, F. & Ball, T. (2017). Deep learning with convolutional neural networks for EEG decoding and visualization. Human Brain Mapping , Aug. 2017. Online: http://dx.doi.org/10.1002/hbm.23730
braindecode.models.deepsleepnet module#
- class braindecode.models.deepsleepnet.DeepSleepNet(n_outputs=5, return_feats=False, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, activation_large: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, activation_small: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, drop_prob: float = 0.5)[source]#
Bases:
EEGModuleMixin,ModuleSleep staging architecture from Supratak et al. (2017) [Supratak2017].
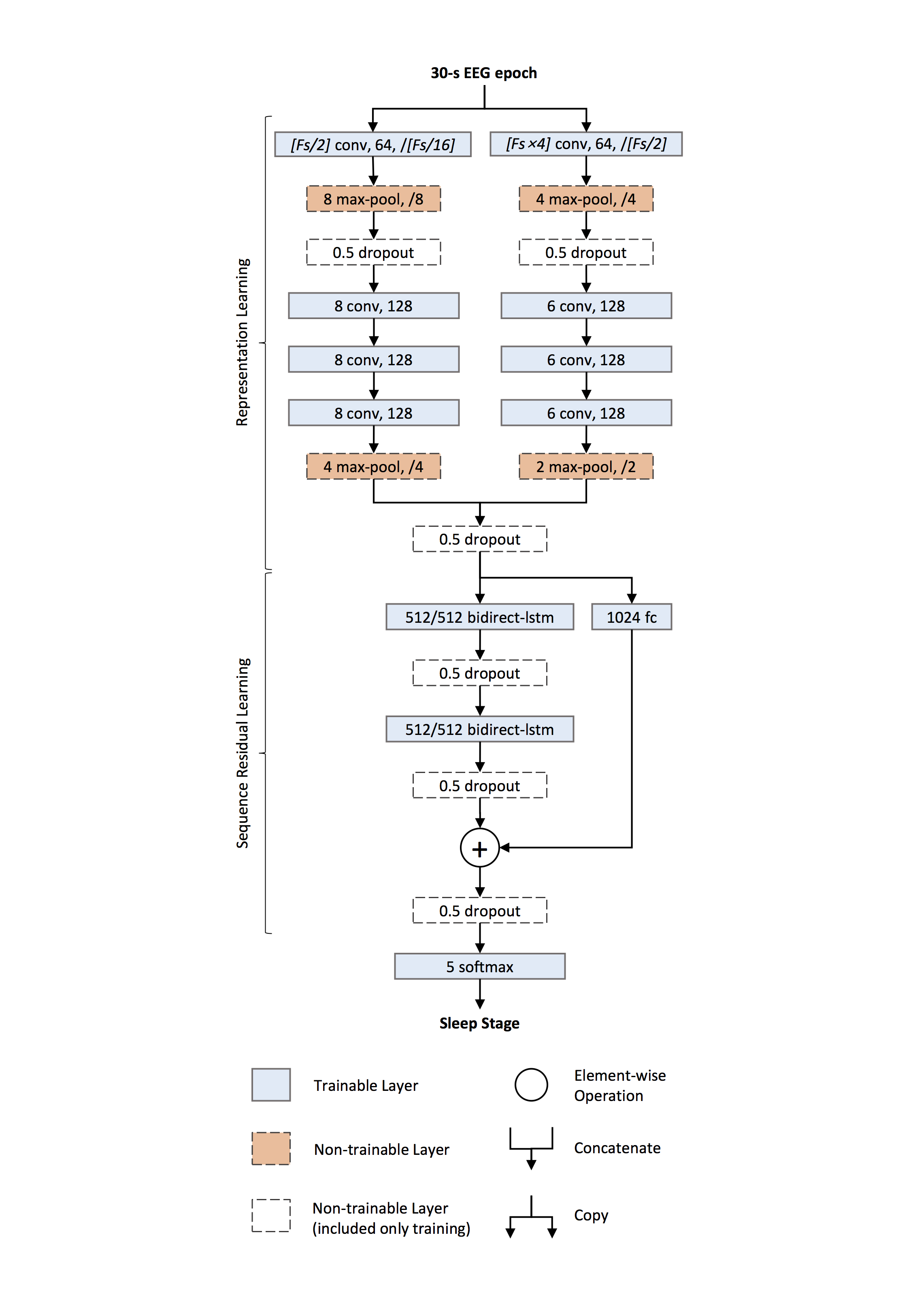
Convolutional neural network and bidirectional-Long Short-Term for single channels sleep staging described in [Supratak2017].
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
return_feats (bool) – If True, return the features, i.e. the output of the feature extractor (before the final linear layer). If False, pass the features through the final linear layer.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
activation_large (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.activation_small (nn.Module, default=nn.ReLU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ReLU.drop_prob (float, default=0.5) – The dropout rate for regularization. Values should be between 0 and 1.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
- forward(x)[source]#
Forward pass.
- Parameters:
x (torch.Tensor) – Batch of EEG windows of shape (batch_size, n_channels, n_times).
braindecode.models.eegconformer module#
- class braindecode.models.eegconformer.EEGConformer(n_outputs=None, n_chans=None, n_filters_time=40, filter_time_length=25, pool_time_length=75, pool_time_stride=15, drop_prob=0.5, att_depth=6, att_heads=10, att_drop_prob=0.5, final_fc_length='auto', return_features=False, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, activation_transfor: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.GELU'>, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None)[source]#
Bases:
EEGModuleMixin,ModuleEEG Conformer from Song et al. (2022) from [song2022].
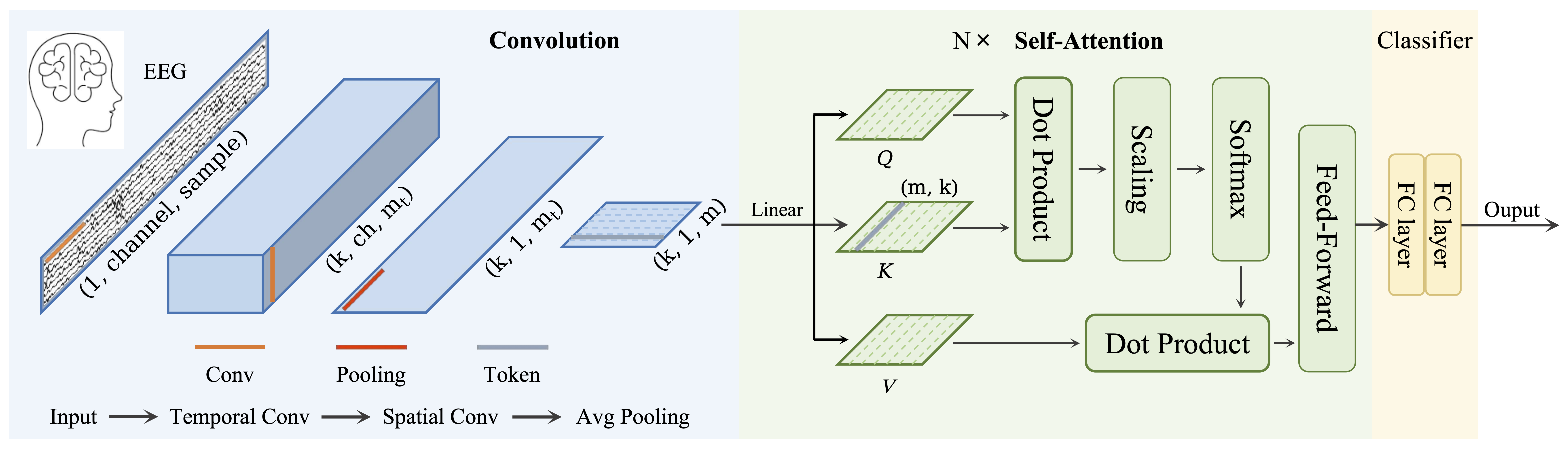
Convolutional Transformer for EEG decoding.
The paper and original code with more details about the methodological choices are available at the [song2022] and [ConformerCode].
This neural network architecture receives a traditional braindecode input. The input shape should be three-dimensional matrix representing the EEG signals.
(batch_size, n_channels, n_timesteps).
- The EEG Conformer architecture is composed of three modules:
PatchEmbedding
TransformerEncoder
ClassificationHead
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
n_filters_time (int) – Number of temporal filters, defines also embedding size.
filter_time_length (int) – Length of the temporal filter.
pool_time_length (int) – Length of temporal pooling filter.
pool_time_stride (int) – Length of stride between temporal pooling filters.
drop_prob (float) – Dropout rate of the convolutional layer.
att_depth (int) – Number of self-attention layers.
att_heads (int) – Number of attention heads.
att_drop_prob (float) – Dropout rate of the self-attention layer.
final_fc_length (int | str) – The dimension of the fully connected layer.
return_features (bool) – If True, the forward method returns the features before the last classification layer. Defaults to False.
activation (nn.Module) – Activation function as parameter. Default is nn.ELU
activation_transfor (nn.Module) – Activation function as parameter, applied at the FeedForwardBlock module inside the transformer. Default is nn.GeLU
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
The authors recommend using data augmentation before using Conformer, e.g. segmentation and recombination, Please refer to the original paper and code for more details.
The model was initially tuned on 4 seconds of 250 Hz data. Please adjust the scale of the temporal convolutional layer, and the pooling layer for better performance.
Added in version 0.8.
We aggregate the parameters based on the parts of the models, or when the parameters were used first, e.g. n_filters_time.
References
[song2022] (1,2)Song, Y., Zheng, Q., Liu, B. and Gao, X., 2022. EEG conformer: Convolutional transformer for EEG decoding and visualization. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31, pp.710-719. https://ieeexplore.ieee.org/document/9991178
[ConformerCode]Song, Y., Zheng, Q., Liu, B. and Gao, X., 2022. EEG conformer: Convolutional transformer for EEG decoding and visualization. eeyhsong/EEG-Conformer.
- forward(x: Tensor) Tensor[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
x – The description is missing.
braindecode.models.eeginception_erp module#
- class braindecode.models.eeginception_erp.EEGInceptionERP(n_chans=None, n_outputs=None, n_times=1000, sfreq=128, drop_prob=0.5, scales_samples_s=(0.5, 0.25, 0.125), n_filters=8, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, batch_norm_alpha=0.01, depth_multiplier=2, pooling_sizes=(4, 2, 2, 2), chs_info=None, input_window_seconds=None)[source]#
Bases:
EEGModuleMixin,SequentialEEG Inception for ERP-based from Santamaria-Vazquez et al (2020) [santamaria2020].
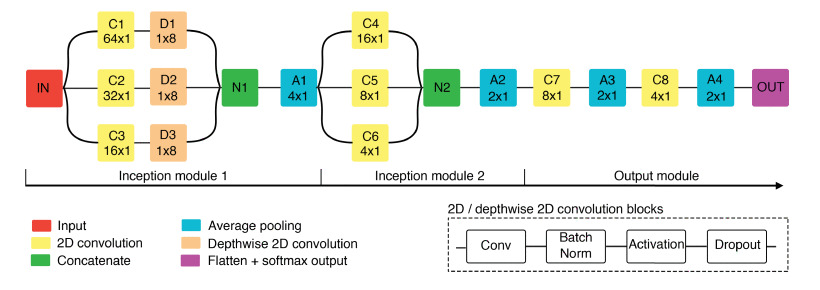
The code for the paper and this model is also available at [santamaria2020] and an adaptation for PyTorch [2].
The model is strongly based on the original InceptionNet for an image. The main goal is to extract features in parallel with different scales. The authors extracted three scales proportional to the window sample size. The network had three parts: 1-larger inception block largest, 2-smaller inception block followed by 3-bottleneck for classification.
One advantage of the EEG-Inception block is that it allows a network to learn simultaneous components of low and high frequency associated with the signal. The winners of BEETL Competition/NeurIps 2021 used parts of the model [beetl].
The model is fully described in [santamaria2020].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int, optional) – Size of the input, in number of samples. Set to 128 (1s) as in [santamaria2020].
sfreq (float, optional) – EEG sampling frequency. Defaults to 128 as in [santamaria2020].
drop_prob (float, optional) – Dropout rate inside all the network. Defaults to 0.5 as in [santamaria2020].
scales_samples_s (list(float), optional) – Windows for inception block. Temporal scale (s) of the convolutions on each Inception module. This parameter determines the kernel sizes of the filters. Defaults to 0.5, 0.25, 0.125 seconds, as in [santamaria2020].
n_filters (int, optional) – Initial number of convolutional filters. Defaults to 8 as in [santamaria2020].
activation (nn.Module, optional) – Activation function. Defaults to ELU activation as in [santamaria2020].
batch_norm_alpha (float, optional) – Momentum for BatchNorm2d. Defaults to 0.01.
depth_multiplier (int, optional) – Depth multiplier for the depthwise convolution. Defaults to 2 as in [santamaria2020].
pooling_sizes (list(int), optional) – Pooling sizes for the inception blocks. Defaults to 4, 2, 2 and 2, as in [santamaria2020].
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented from the paper based on [2].
References
[santamaria2020] (1,2,3,4,5,6,7,8,9,10,11)Santamaria-Vazquez, E., Martinez-Cagigal, V., Vaquerizo-Villar, F., & Hornero, R. (2020). EEG-inception: A novel deep convolutional neural network for assistive ERP-based brain-computer interfaces. IEEE Transactions on Neural Systems and Rehabilitation Engineering , v. 28. Online: http://dx.doi.org/10.1109/TNSRE.2020.3048106
[beetl]Wei, X., Faisal, A.A., Grosse-Wentrup, M., Gramfort, A., Chevallier, S., Jayaram, V., Jeunet, C., Bakas, S., Ludwig, S., Barmpas, K., Bahri, M., Panagakis, Y., Laskaris, N., Adamos, D.A., Zafeiriou, S., Duong, W.C., Gordon, S.M., Lawhern, V.J., Śliwowski, M., Rouanne, V. & Tempczyk, P. (2022). 2021 BEETL Competition: Advancing Transfer Learning for Subject Independence & Heterogeneous EEG Data Sets. Proceedings of the NeurIPS 2021 Competitions and Demonstrations Track, in Proceedings of Machine Learning Research 176:205-219 Available from https://proceedings.mlr.press/v176/wei22a.html.
braindecode.models.eeginception_mi module#
- class braindecode.models.eeginception_mi.EEGInceptionMI(n_chans=None, n_outputs=None, input_window_seconds=None, sfreq=250, n_convs=5, n_filters=48, kernel_unit_s=0.1, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, chs_info=None, n_times=None)[source]#
Bases:
EEGModuleMixin,ModuleEEG Inception for Motor Imagery, as proposed in Zhang et al. (2021) [1]

The model is strongly based on the original InceptionNet for computer vision. The main goal is to extract features in parallel with different scales. The network has two blocks made of 3 inception modules with a skip connection.
The model is fully described in [1].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
input_window_seconds (float, optional) – Size of the input, in seconds. Set to 4.5 s as in [1] for dataset BCI IV 2a.
sfreq (float, optional) – EEG sampling frequency in Hz. Defaults to 250 Hz as in [1] for dataset BCI IV 2a.
n_convs (int, optional) – Number of convolution per inception wide branching. Defaults to 5 as in [1] for dataset BCI IV 2a.
n_filters (int, optional) – Number of convolutional filters for all layers of this type. Set to 48 as in [1] for dataset BCI IV 2a.
kernel_unit_s (float, optional) – Size in seconds of the basic 1D convolutional kernel used in inception modules. Each convolutional layer in such modules have kernels of increasing size, odd multiples of this value (e.g. 0.1, 0.3, 0.5, 0.7, 0.9 here for
n_convs=5). Defaults to 0.1 s.activation (nn.Module) – Activation function. Defaults to ReLU activation.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented bosed on the paper [1].
References
- forward(X: Tensor) Tensor[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
X – The description is missing.
braindecode.models.eegitnet module#
- class braindecode.models.eegitnet.EEGITNet(n_outputs=None, n_chans=None, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None, n_filters_time: int = 2, kernel_length: int = 16, pool_kernel: int = 4, tcn_in_channel: int = 14, tcn_kernel_size: int = 4, tcn_padding: int = 3, drop_prob: float = 0.4, tcn_dilatation: int = 1, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>)[source]#
Bases:
EEGModuleMixin,SequentialEEG-ITNet from Salami, et al (2022) [Salami2022]
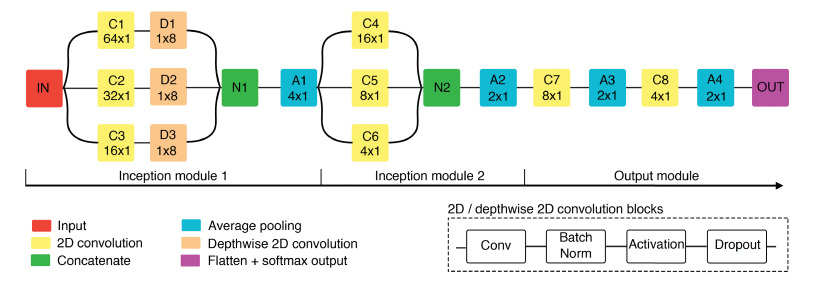
EEG-ITNet: An Explainable Inception Temporal Convolutional Network for motor imagery classification from Salami et al. 2022.
See [Salami2022] for details.
Code adapted from abbassalami/eeg-itnet
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_filters_time – The description is missing.
kernel_length (int, optional) – Kernel length for inception branches. Determines the temporal receptive field. Default is 16.
pool_kernel (int, optional) – Pooling kernel size for the average pooling layer. Default is 4.
tcn_in_channel (int, optional) – Number of input channels for Temporal Convolutional (TC) blocks. Default is 14.
tcn_kernel_size (int, optional) – Kernel size for the TC blocks. Determines the temporal receptive field. Default is 4.
tcn_padding (int, optional) – Padding size for the TC blocks to maintain the input dimensions. Default is 3.
drop_prob (float, optional) – Dropout probability applied after certain layers to prevent overfitting. Default is 0.4.
tcn_dilatation (int, optional) – Dilation rate for the first TC block. Subsequent blocks will have dilation rates multiplied by powers of 2. Default is 1.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented from the paper based on author implementation.
References
braindecode.models.eegminer module#
Copyright (C) Cogitat, Ltd.
Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0)
Patent GB2609265 - Learnable filters for eeg classification
https://www.ipo.gov.uk/p-ipsum/Case/ApplicationNumber/GB2113420.0
- class braindecode.models.eegminer.EEGMiner(method: str = 'plv', n_chans=None, n_outputs=None, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None, filter_f_mean=(23.0, 23.0), filter_bandwidth=(44.0, 44.0), filter_shape=(2.0, 2.0), group_delay=(20.0, 20.0), clamp_f_mean=(1.0, 45.0))[source]#
Bases:
EEGModuleMixin,ModuleEEGMiner from Ludwig et al (2024) [eegminer].

EEGMiner is a neural network model for EEG signal classification using learnable generalized Gaussian filters. The model leverages frequency domain filtering and connectivity metrics or feature extraction, such as Phase Locking Value (PLV) to extract meaningful features from EEG data, enabling effective classification tasks.
The model has the following steps:
Generalized Gaussian filters in the frequency domain to the input EEG signals.
- Connectivity estimators (corr, plv) or Electrode-Wise Band Power (mag), by default (plv).
‘corr’: Computes the correlation of the filtered signals.
‘plv’: Computes the phase locking value of the filtered signals.
‘mag’: Computes the magnitude of the filtered signals.
- Feature Normalization
Apply batch normalization.
- Final Layer
Feeds the batch-normalized features into a final linear layer for classification.
Depending on the selected method (mag, corr, or plv), it computes the filtered signals’ magnitude, correlation, or phase locking value. These features are then normalized and passed through a batch normalization layer before being fed into a final linear layer for classification.
The input to EEGMiner should be a three-dimensional tensor representing EEG signals:
(batch_size, n_channels, n_timesteps).- Parameters:
method (str, default="plv") – The method used for feature extraction. Options are: - “mag”: Electrode-Wise band power of the filtered signals. - “corr”: Correlation between filtered channels. - “plv”: Phase Locking Value connectivity metric.
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
filter_f_mean (list of float, default=[23.0, 23.0]) – Mean frequencies for the generalized Gaussian filters.
filter_bandwidth (list of float, default=[44.0, 44.0]) – Bandwidths for the generalized Gaussian filters.
filter_shape (list of float, default=[2.0, 2.0]) – Shape parameters for the generalized Gaussian filters.
group_delay (tuple of float, default=(20.0, 20.0)) – Group delay values for the filters in milliseconds.
clamp_f_mean (tuple of float, default=(1.0, 45.0)) – Clamping range for the mean frequency parameters.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
EEGMiner incorporates learnable parameters for filter characteristics, allowing the model to adaptively learn optimal frequency bands and phase delays for the classification task. By default, using the PLV as a connectivity metric makes EEGMiner suitable for tasks requiring the analysis of phase relationships between different EEG channels.
The model and the module have patent [eegminercode], and the code is CC BY-NC 4.0.
Added in version 0.9.
References
[eegminer]Ludwig, S., Bakas, S., Adamos, D. A., Laskaris, N., Panagakis, Y., & Zafeiriou, S. (2024). EEGMiner: discovering interpretable features of brain activity with learnable filters. Journal of Neural Engineering, 21(3), 036010.
[eegminercode]Ludwig, S., Bakas, S., Adamos, D. A., Laskaris, N., Panagakis, Y., & Zafeiriou, S. (2024). EEGMiner: discovering interpretable features of brain activity with learnable filters. SMLudwig/EEGminer. Cogitat, Ltd. “Learnable filters for EEG classification.” Patent GB2609265. https://www.ipo.gov.uk/p-ipsum/Case/ApplicationNumber/GB2113420.0
braindecode.models.eegnet module#
- class braindecode.models.eegnet.EEGNetv1(n_chans=None, n_outputs=None, n_times=None, final_conv_length='auto', pool_mode='max', second_kernel_size=(2, 32), third_kernel_size=(8, 4), drop_prob=0.25, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, chs_info=None, input_window_seconds=None, sfreq=None)[source]#
Bases:
EEGModuleMixin,SequentialEEGNet model from Lawhern et al. 2016 from [EEGNet].
See details in [EEGNet].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
final_conv_length – The description is missing.
pool_mode – The description is missing.
second_kernel_size – The description is missing.
third_kernel_size – The description is missing.
drop_prob – The description is missing.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented from the paper description.
References
- class braindecode.models.eegnet.EEGNetv4(n_chans: int | None = None, n_outputs: int | None = None, n_times: int | None = None, final_conv_length: str | int = 'auto', pool_mode: str = 'mean', F1: int = 8, D: int = 2, F2: int | None = None, kernel_length: int = 64, *, depthwise_kernel_length: int = 16, pool1_kernel_size: int = 4, pool2_kernel_size: int = 8, conv_spatial_max_norm: int = 1, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, batch_norm_momentum: float = 0.01, batch_norm_affine: bool = True, batch_norm_eps: float = 0.001, drop_prob: float = 0.25, final_layer_with_constraint: bool = False, norm_rate: float = 0.25, chs_info: list[~typing.Dict] | None = None, input_window_seconds=None, sfreq=None, **kwargs)[source]#
Bases:
EEGModuleMixin,SequentialEEGNet v4 model from Lawhern et al. (2018) [EEGNet4].

See details in [EEGNet4].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
final_conv_length (int or "auto", default="auto") – Length of the final convolution layer. If “auto”, it is set based on n_times.
pool_mode ({"mean", "max"}, default="mean") – Pooling method to use in pooling layers.
F1 (int, default=8) – Number of temporal filters in the first convolutional layer.
D (int, default=2) – Depth multiplier for the depthwise convolution.
F2 (int or None, default=None) – Number of pointwise filters in the separable convolution. Usually set to
F1 * D.kernel_length (int, default=64) – Length of the temporal convolution kernel.
depthwise_kernel_length (int, default=16) – Length of the depthwise convolution kernel in the separable convolution.
pool1_kernel_size (int, default=4) – Kernel size of the first pooling layer.
pool2_kernel_size (int, default=8) – Kernel size of the second pooling layer.
conv_spatial_max_norm (float, default=1) – Maximum norm constraint for the spatial (depthwise) convolution.
activation (nn.Module, default=nn.ELU) – Non-linear activation function to be used in the layers.
batch_norm_momentum (float, default=0.01) – Momentum for instance normalization in batch norm layers.
batch_norm_affine (bool, default=True) – If True, batch norm has learnable affine parameters.
batch_norm_eps (float, default=1e-3) – Epsilon for numeric stability in batch norm layers.
drop_prob (float, default=0.25) – Dropout probability.
final_layer_with_constraint (bool, default=False) – If
False, uses a convolution-based classification layer. IfTrue, apply a flattened linear layer with constraint on the weights norm as the final classification step.norm_rate (float, default=0.25) – Max-norm constraint value for the linear layer (used if
final_layer_conv=False).chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
**kwargs – The description is missing.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
braindecode.models.eegnex module#
- class braindecode.models.eegnex.EEGNeX(n_chans=None, n_outputs=None, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, depth_multiplier: int = 2, filter_1: int = 8, filter_2: int = 32, drop_prob: float = 0.5, kernel_block_1_2: int = 64, kernel_block_4: int = 16, dilation_block_4: int = 2, avg_pool_block4: int = 4, kernel_block_5: int = 16, dilation_block_5: int = 4, avg_pool_block5: int = 8, max_norm_conv: float = 1.0, max_norm_linear: float = 0.25)[source]#
Bases:
EEGModuleMixin,ModuleEEGNeX model from Chen et al. (2024) [eegnex].
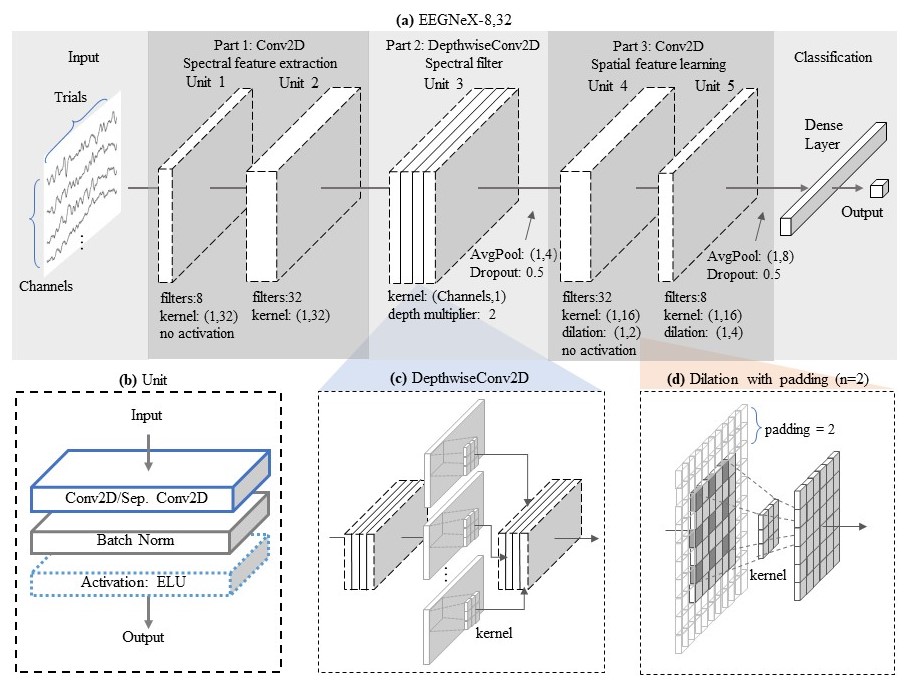
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
activation (nn.Module, optional) – Activation function to use. Default is nn.ELU.
depth_multiplier (int, optional) – Depth multiplier for the depthwise convolution. Default is 2.
filter_1 (int, optional) – Number of filters in the first convolutional layer. Default is 8.
filter_2 (int, optional) – Number of filters in the second convolutional layer. Default is 32.
drop_prob (float, optional) – Dropout rate. Default is 0.5.
kernel_block_1_2 – The description is missing.
kernel_block_4 (tuple[int, int], optional) – Kernel size for block 4. Default is (1, 16).
dilation_block_4 (tuple[int, int], optional) – Dilation rate for block 4. Default is (1, 2).
avg_pool_block4 (tuple[int, int], optional) – Pooling size for block 4. Default is (1, 4).
kernel_block_5 (tuple[int, int], optional) – Kernel size for block 5. Default is (1, 16).
dilation_block_5 (tuple[int, int], optional) – Dilation rate for block 5. Default is (1, 4).
avg_pool_block5 (tuple[int, int], optional) – Pooling size for block 5. Default is (1, 8).
max_norm_conv – The description is missing.
max_norm_linear – The description is missing.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented from the paper description and source code in tensorflow [EEGNexCode].
References
[eegnex]Chen, X., Teng, X., Chen, H., Pan, Y., & Geyer, P. (2024). Toward reliable signals decoding for electroencephalogram: A benchmark study to EEGNeX. Biomedical Signal Processing and Control, 87, 105475.
[EEGNexCode]Chen, X., Teng, X., Chen, H., Pan, Y., & Geyer, P. (2024). Toward reliable signals decoding for electroencephalogram: A benchmark study to EEGNeX. chenxiachan/EEGNeX
- forward(x: Tensor) Tensor[source]#
Forward pass of the EEGNeX model.
- Parameters:
x (torch.Tensor) – Input tensor of shape (batch_size, n_chans, n_times).
- Returns:
Output tensor of shape (batch_size, n_outputs).
- Return type:
braindecode.models.eegresnet module#
- class braindecode.models.eegresnet.EEGResNet(n_chans=None, n_outputs=None, n_times=None, final_pool_length='auto', n_first_filters=20, n_layers_per_block=2, first_filter_length=3, activation=<class 'torch.nn.modules.activation.ELU'>, split_first_layer=True, batch_norm_alpha=0.1, batch_norm_epsilon=0.0001, conv_weight_init_fn=<function EEGResNet.<lambda>>, chs_info=None, input_window_seconds=None, sfreq=250)[source]#
Bases:
EEGModuleMixin,SequentialEEGResNet from Schirrmeister et al. 2017 [Schirrmeister2017].

Model described in [Schirrmeister2017].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
final_pool_length – The description is missing.
n_first_filters – The description is missing.
n_layers_per_block – The description is missing.
first_filter_length – The description is missing.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.split_first_layer – The description is missing.
batch_norm_alpha – The description is missing.
batch_norm_epsilon – The description is missing.
conv_weight_init_fn – The description is missing.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Schirrmeister2017] (1,2)Schirrmeister, R. T., Springenberg, J. T., Fiederer, L. D. J., Glasstetter, M., Eggensperger, K., Tangermann, M., Hutter, F. & Ball, T. (2017). Deep learning with convolutional neural networks for , EEG decoding and visualization. Human Brain Mapping, Aug. 2017. Online: http://dx.doi.org/10.1002/hbm.23730
braindecode.models.eegsimpleconv module#
EEG-SimpleConv is a 1D Convolutional Neural Network from Yassine El Ouahidi et al. (2023).
Originally designed for Motor Imagery decoding, from EEG signals. The model offers competitive performances, with a low latency and is mainly composed of 1D convolutional layers.
- class braindecode.models.eegsimpleconv.EEGSimpleConv(n_outputs=None, n_chans=None, sfreq=None, feature_maps=128, n_convs=2, resampling_freq=80, kernel_size=8, return_feature=False, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, chs_info=None, n_times=None, input_window_seconds=None)[source]#
Bases:
EEGModuleMixin,ModuleEEGSimpleConv from Ouahidi, YE et al. (2023) [Yassine2023].
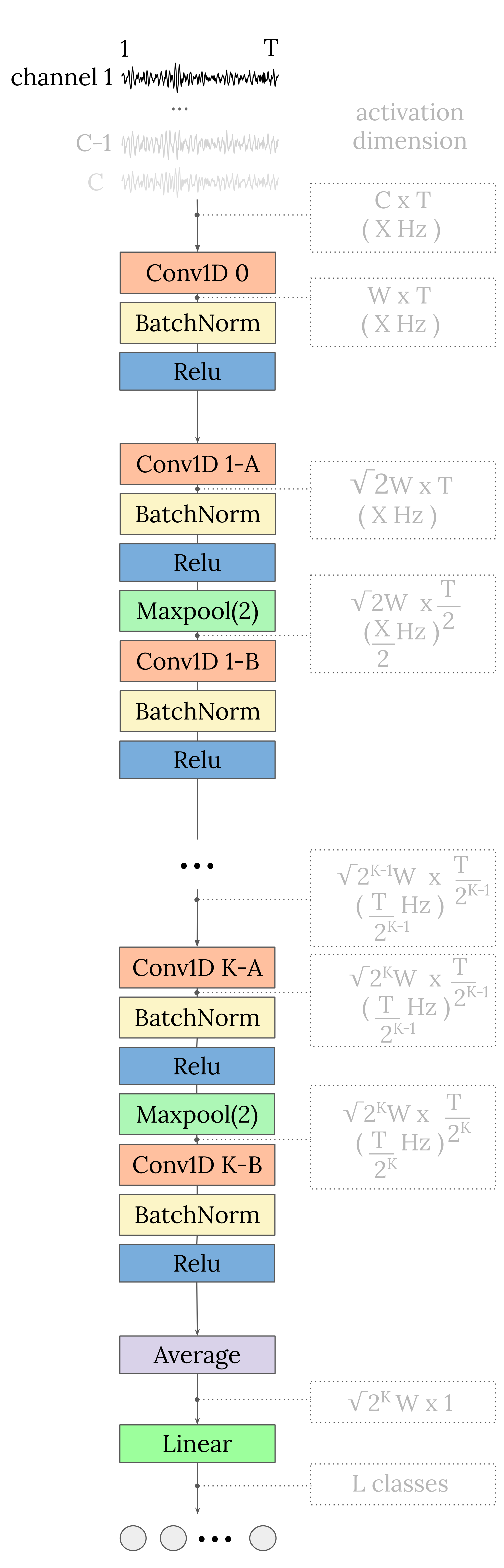
EEGSimpleConv is a 1D Convolutional Neural Network originally designed for decoding motor imagery from EEG signals. The model aims to have a very simple and straightforward architecture that allows a low latency, while still achieving very competitive performance.
EEG-SimpleConv starts with a 1D convolutional layer, where each EEG channel enters a separate 1D convolutional channel. This is followed by a series of blocks of two 1D convolutional layers. Between the two convolutional layers of each block is a max pooling layer, which downsamples the data by a factor of 2. Each convolution is followed by a batch normalisation layer and a ReLU activation function. Finally, a global average pooling (in the time domain) is performed to obtain a single value per feature map, which is then fed into a linear layer to obtain the final classification prediction output.
The paper and original code with more details about the methodological choices are available at the [Yassine2023] and [Yassine2023Code].
The input shape should be three-dimensional matrix representing the EEG signals.
(batch_size, n_channels, n_timesteps).- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
sfreq (float) – Sampling frequency of the EEG recordings.
feature_maps (int) – Number of Feature Maps at the first Convolution, width of the model.
n_convs (int) – Number of blocks of convolutions (2 convolutions per block), depth of the model.
resampling_freq – The description is missing.
kernel_size (int) – Size of the convolutions kernels.
return_feature – The description is missing.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
The authors recommend using the default parameters for MI decoding. Please refer to the original paper and code for more details.
Recommended range for the choice of the hyperparameters, regarding the evaluation paradigm.
Parameter | Within-Subject | Cross-Subject |feature_maps | [64-144] | [64-144] |n_convs | 1 | [2-4] |resampling_freq | [70-100] | [50-80] |kernel_size | [12-17] | [5-8] |An intensive ablation study is included in the paper to understand the of each parameter on the model performance.
Added in version 0.9.
References
[Yassine2023] (1,2)Yassine El Ouahidi, V. Gripon, B. Pasdeloup, G. Bouallegue N. Farrugia, G. Lioi, 2023. A Strong and Simple Deep Learning Baseline for BCI Motor Imagery Decoding. Arxiv preprint. arxiv.org/abs/2309.07159
[Yassine2023Code]Yassine El Ouahidi, V. Gripon, B. Pasdeloup, G. Bouallegue N. Farrugia, G. Lioi, 2023. A Strong and Simple Deep Learning Baseline for BCI Motor Imagery Decoding. GitHub repository. elouayas/EEGSimpleConv.
braindecode.models.eegtcnet module#
- class braindecode.models.eegtcnet.EEGTCNet(n_chans=None, n_outputs=None, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, depth_multiplier: int = 2, filter_1: int = 8, kern_length: int = 64, drop_prob: float = 0.5, depth: int = 2, kernel_size: int = 4, filters: int = 12, max_norm_const: float = 0.25)[source]#
Bases:
EEGModuleMixin,ModuleEEGTCNet model from Ingolfsson et al. (2020) [ingolfsson2020].

Combining EEGNet and TCN blocks.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
activation (nn.Module, optional) – Activation function to use. Default is nn.ELU().
depth_multiplier (int, optional) – Depth multiplier for the depthwise convolution. Default is 2.
filter_1 (int, optional) – Number of temporal filters in the first convolutional layer. Default is 8.
kern_length (int, optional) – Length of the temporal kernel in the first convolutional layer. Default is 64.
drop_prob – The description is missing.
depth (int, optional) – Number of residual blocks in the TCN. Default is 2.
kernel_size (int, optional) – Size of the temporal convolutional kernel in the TCN. Default is 4.
filters (int, optional) – Number of filters in the TCN convolutional layers. Default is 12.
max_norm_const (float) – Maximum L2-norm constraint imposed on weights of the last fully-connected layer. Defaults to 0.25.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[ingolfsson2020]Ingolfsson, T. M., Hersche, M., Wang, X., Kobayashi, N., Cavigelli, L., & Benini, L. (2020). EEG-TCNet: An accurate temporal convolutional network for embedded motor-imagery brain–machine interfaces. https://doi.org/10.48550/arXiv.2006.00622
- forward(x: Tensor) Tensor[source]#
Forward pass of the EEGTCNet model.
- Parameters:
x (torch.Tensor) – Input tensor of shape (batch_size, n_chans, n_times).
- Returns:
Output tensor of shape (batch_size, n_outputs).
- Return type:
braindecode.models.fbcnet module#
- class braindecode.models.fbcnet.FBCNet(n_chans=None, n_outputs=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, n_bands=9, n_filters_spat: int = 32, temporal_layer: str = 'LogVarLayer', n_dim: int = 3, stride_factor: int = 4, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.SiLU'>, linear_max_norm: float = 0.5, cnn_max_norm: float = 2.0, filter_parameters: dict[~typing.Any, ~typing.Any] | None = None)[source]#
Bases:
EEGModuleMixin,ModuleFBCNet from Mane, R et al (2021) [fbcnet2021].
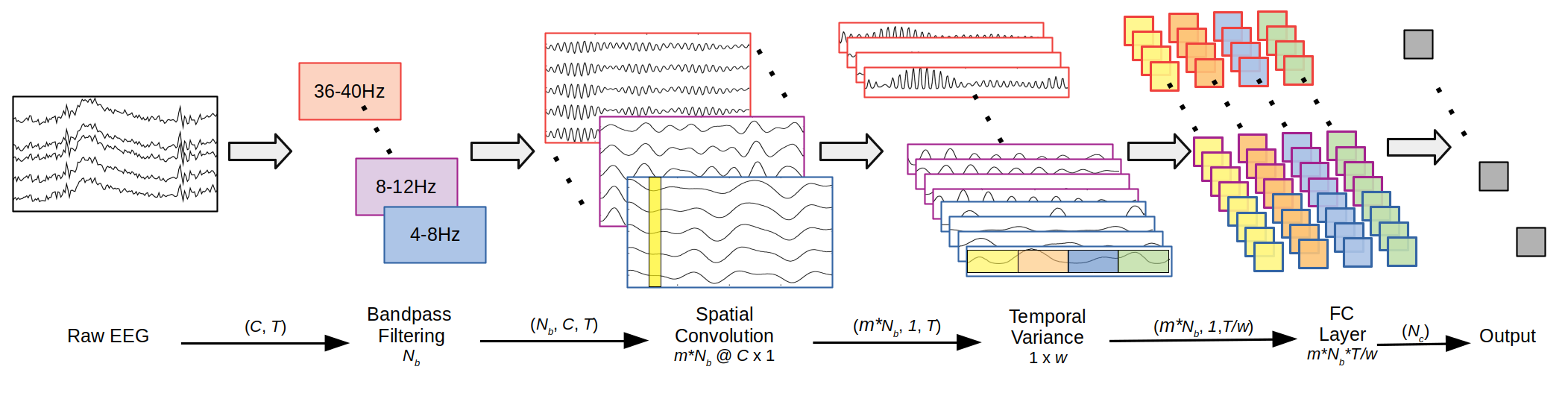
The FBCNet model applies spatial convolution and variance calculation along the time axis, inspired by the Filter Bank Common Spatial Pattern (FBCSP) algorithm.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_bands (int or None or list[tuple[int, int]]], default=9) – Number of frequency bands. Could
n_filters_spat (int, default=32) – Number of spatial filters for the first convolution.
temporal_layer (str, default='LogVarLayer') – Type of temporal aggregator layer. Options: ‘VarLayer’, ‘StdLayer’, ‘LogVarLayer’, ‘MeanLayer’, ‘MaxLayer’.
n_dim (int, default=3) – Number of dimensions for the temporal reductor
stride_factor (int, default=4) – Stride factor for reshaping.
activation (nn.Module, default=nn.SiLU) – Activation function class to apply in Spatial Convolution Block.
linear_max_norm (float, default=0.5) – Maximum norm for the final linear layer.
cnn_max_norm (float, default=2.0) – Maximum norm for the spatial convolution layer.
filter_parameters (dict, default None) – Parameters for the FilterBankLayer
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct and has not been checked by the original authors; it has only been reimplemented from the paper description and source code [fbcnetcode2021]. There is a difference in the activation function; in the paper, the ELU is used as the activation function, but in the original code, SiLU is used. We followed the code.
References
[fbcnet2021]Mane, R., Chew, E., Chua, K., Ang, K. K., Robinson, N., Vinod, A. P., … & Guan, C. (2021). FBCNet: A multi-view convolutional neural network for brain-computer interface. preprint arXiv:2104.01233.
[fbcnetcode2021]Link to source-code: ravikiran-mane/FBCNet
- forward(x: Tensor) Tensor[source]#
Forward pass of the FBCNet model.
- Parameters:
x (torch.Tensor) – Input tensor with shape (batch_size, n_chans, n_times).
- Returns:
Output tensor with shape (batch_size, n_outputs).
- Return type:
braindecode.models.fblightconvnet module#
- class braindecode.models.fblightconvnet.FBLightConvNet(n_chans=None, n_outputs=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, n_bands=9, n_filters_spat: int = 32, n_dim: int = 3, stride_factor: int = 4, win_len: int = 250, heads: int = 8, weight_softmax: bool = True, bias: bool = False, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, verbose: bool = False, filter_parameters: dict | None = None)[source]#
Bases:
EEGModuleMixin,ModuleLightConvNet from Ma, X et al (2023) [lightconvnet].
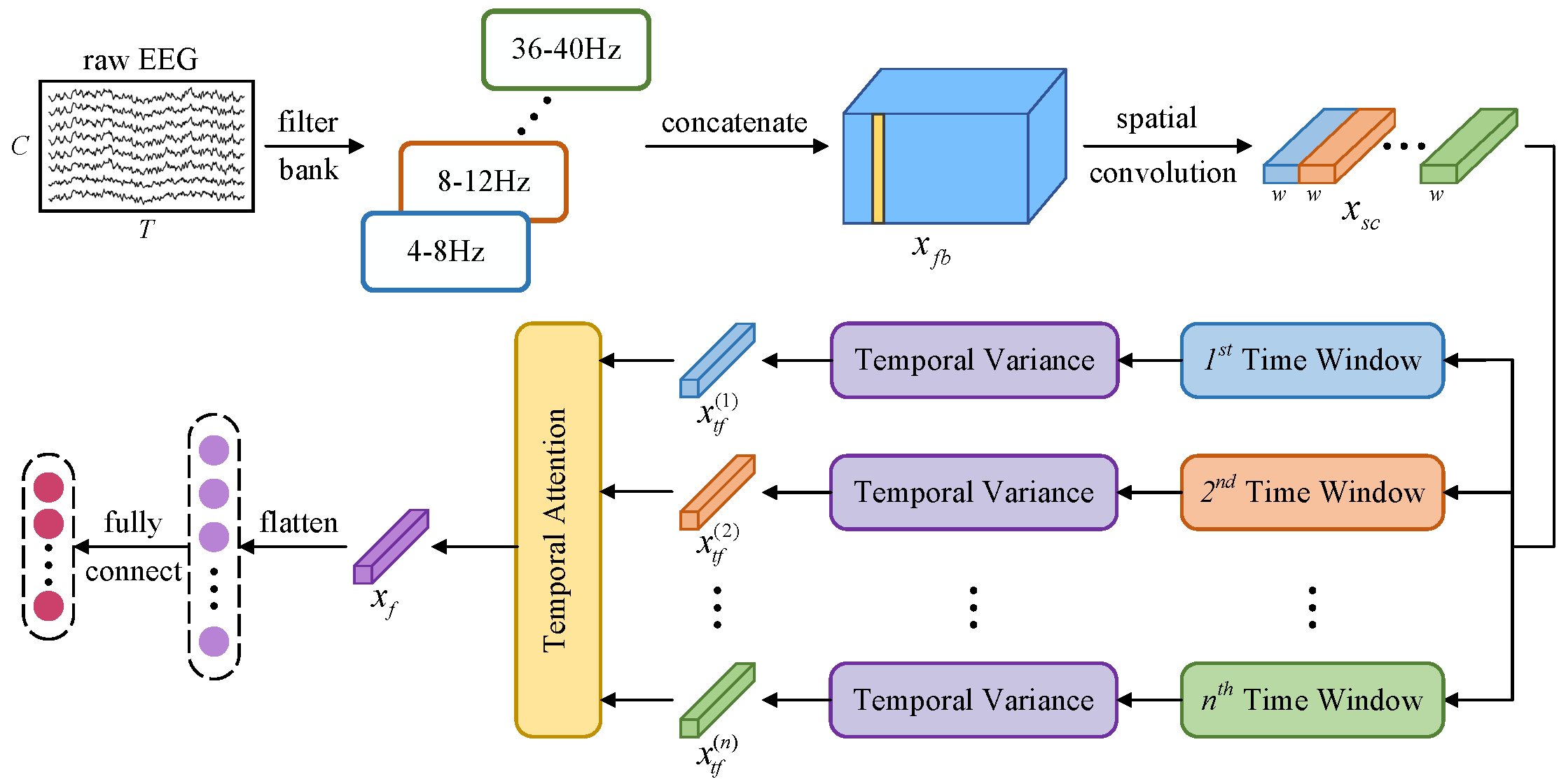
A lightweight convolutional neural network incorporating temporal dependency learning and attention mechanisms. The architecture is designed to efficiently capture spatial and temporal features through specialized convolutional layers and multi-head attention.
The network architecture consists of four main modules:
- Spatial and Spectral Information Learning:
Applies filterbank and spatial convolutions. This module is followed by batch normalization and an activation function to enhance feature representation.
- Temporal Segmentation and Feature Extraction:
Divides the processed data into non-overlapping temporal windows. Within each window, a variance-based layer extracts discriminative features, which are then log-transformed to stabilize variance before being passed to the attention module.
- Temporal Attention Module: Utilizes a multi-head attention
mechanism with depthwise separable convolutions to capture dependencies across different temporal segments. The attention weights are normalized using softmax and aggregated to form a comprehensive temporal representation.
- Final Layer: Flattens the aggregated features and passes them
through a linear layer to with kernel sizes matching the input dimensions to integrate features across different channels generate the final output predictions.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_bands (int or None or list of tuple of int, default=8) – Number of frequency bands or a list of frequency band tuples. If a list of tuples is provided, each tuple defines the lower and upper bounds of a frequency band.
n_filters_spat (int, default=32) – Number of spatial filters in the depthwise convolutional layer.
n_dim (int, default=3) – Number of dimensions for the temporal reduction layer.
stride_factor (int, default=4) – Stride factor used for reshaping the temporal dimension.
win_len – The description is missing.
heads (int, default=8) – Number of attention heads in the multi-head attention mechanism.
weight_softmax (bool, default=True) – If True, applies softmax to the attention weights.
bias (bool, default=False) – If True, includes a bias term in the convolutional layers.
activation (nn.Module, default=nn.ELU) – Activation function class to apply after convolutional layers.
verbose (bool, default=False) – If True, enables verbose output during filter creation using mne.
filter_parameters (dict, default={}) – Additional parameters for the FilterBankLayer.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct and has not been checked by the original authors; it is a braindecode adaptation from the Pytorch source-code [lightconvnetcode].
References
[lightconvnet]Ma, X., Chen, W., Pei, Z., Liu, J., Huang, B., & Chen, J. (2023). A temporal dependency learning CNN with attention mechanism for MI-EEG decoding. IEEE Transactions on Neural Systems and Rehabilitation Engineering.
[lightconvnetcode]Link to source-code: Ma-Xinzhi/LightConvNet
- forward(x: Tensor) Tensor[source]#
Forward pass of the FBLightConvNet model.
- Parameters:
x (torch.Tensor) – Input tensor with shape (batch_size, n_chans, n_times).
- Returns:
Output tensor with shape (batch_size, n_outputs).
- Return type:
braindecode.models.fbmsnet module#
- class braindecode.models.fbmsnet.FBMSNet(n_chans=None, n_outputs=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, n_bands: int = 9, n_filters_spat: int = 36, temporal_layer: str = 'LogVarLayer', n_dim: int = 3, stride_factor: int = 4, dilatability: int = 8, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.SiLU'>, kernels_weights: ~typing.Sequence[int] = (15, 31, 63, 125), cnn_max_norm: float = 2, linear_max_norm: float = 0.5, verbose: bool = False, filter_parameters: dict | None = None)[source]#
Bases:
EEGModuleMixin,ModuleFBMSNet from Liu et al (2022) [fbmsnet].
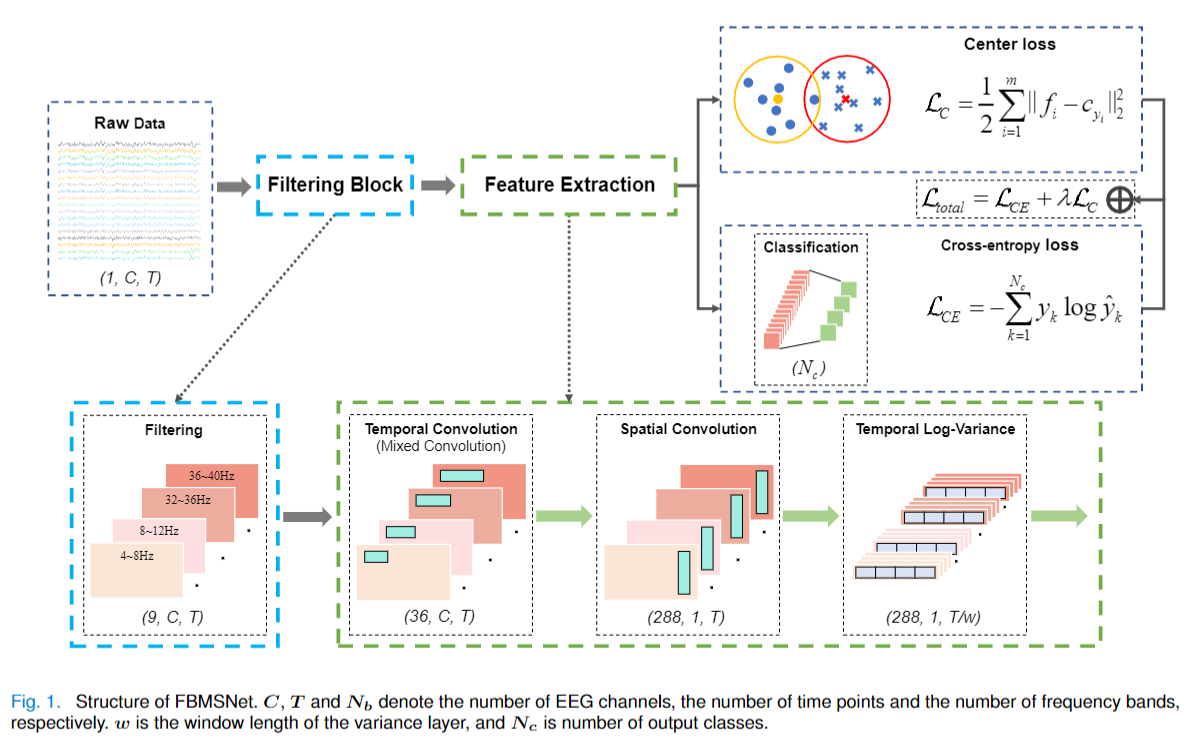
FilterBank Layer: Applying filterbank to transform the input.
Temporal Convolution Block: Utilizes mixed depthwise convolution (MixConv) to extract multiscale temporal features from multiview EEG representations. The input is split into groups corresponding to different views each convolved with kernels of varying sizes. Kernel sizes are set relative to the EEG sampling rate, with ratio coefficients [0.5, 0.25, 0.125, 0.0625], dividing the input into four groups.
Spatial Convolution Block: Applies depthwise convolution with a kernel size of (n_chans, 1) to span all EEG channels, effectively learning spatial filters. This is followed by batch normalization and the Swish activation function. A maximum norm constraint of 2 is imposed on the convolution weights to regularize the model.
Temporal Log-Variance Block: Computes the log-variance.
Classification Layer: A fully connected with weight constraint.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_bands (int, default=9) – Number of input channels (e.g., number of frequency bands).
n_filters_spat (int, default=36) – Number of output channels from the MixedConv2d layer.
temporal_layer (str, default='LogVarLayer') – Temporal aggregation layer to use.
n_dim – The description is missing.
stride_factor (int, default=4) – Stride factor for temporal segmentation.
dilatability (int, default=8) – Expansion factor for the spatial convolution block.
activation (nn.Module, default=nn.SiLU) – Activation function class to apply.
kernels_weights – The description is missing.
cnn_max_norm – The description is missing.
linear_max_norm – The description is missing.
verbose (bool, default False) – Verbose parameter to create the filter using mne.
filter_parameters – The description is missing.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct and has not been checked by the original authors; it has only been reimplemented from the paper description and source code [fbmsnetcode]. There is an extra layer here to compute the filterbank during bash time and not on data time. This avoids data-leak, and allows the model to follow the braindecode convention.
References
[fbmsnet]Liu, K., Yang, M., Yu, Z., Wang, G., & Wu, W. (2022). FBMSNet: A filter-bank multi-scale convolutional neural network for EEG-based motor imagery decoding. IEEE Transactions on Biomedical Engineering, 70(2), 436-445.
[fbmsnetcode]Liu, K., Yang, M., Yu, Z., Wang, G., & Wu, W. (2022). FBMSNet: A filter-bank multi-scale convolutional neural network for EEG-based motor imagery decoding. Want2Vanish/FBMSNet
- forward(x)[source]#
Forward pass of the FBMSNet model.
- Parameters:
x (torch.Tensor) – Input tensor with shape (batch_size, n_chans, n_times).
- Returns:
Output tensor with shape (batch_size, n_outputs).
- Return type:
braindecode.models.hybrid module#
- class braindecode.models.hybrid.HybridNet(n_chans=None, n_outputs=None, n_times=None, input_window_seconds=None, sfreq=None, chs_info=None, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, drop_prob: float = 0.5)[source]#
Bases:
ModuleHybrid ConvNet model from Schirrmeister, R T et al (2017) [Schirrmeister2017].
See [Schirrmeister2017] for details.
References
[Schirrmeister2017] (1,2)Schirrmeister, R. T., Springenberg, J. T., Fiederer, L. D. J., Glasstetter, M., Eggensperger, K., Tangermann, M., Hutter, F. & Ball, T. (2017). Deep learning with convolutional neural networks for EEG decoding and visualization. Human Brain Mapping , Aug. 2017. Online: http://dx.doi.org/10.1002/hbm.23730
- forward(x)[source]#
Forward pass.
- Parameters:
x (torch.Tensor) – Batch of EEG windows of shape (batch_size, n_channels, n_times).
braindecode.models.ifnet module#
IFNet Neural Network.
- Authors: Jiaheng Wang
Bruno Aristimunha <b.aristimunha@gmail.com> (braindecode adaptation)
License: MIT (Jiaheng-Wang/IFNet)
J. Wang, L. Yao and Y. Wang, “IFNet: An Interactive Frequency Convolutional Neural Network for Enhancing Motor Imagery Decoding from EEG,” in IEEE Transactions on Neural Systems and Rehabilitation Engineering, doi: 10.1109/TNSRE.2023.3257319.
- class braindecode.models.ifnet.IFNet(n_chans=None, n_outputs=None, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None, bands: list[tuple[float, float]] | int | None = [(4.0, 16.0), (16, 40)], n_filters_spat: int = 64, kernel_sizes: tuple[int, int] = (63, 31), stride_factor: int = 8, drop_prob: float = 0.5, linear_max_norm: float = 0.5, activation: type[~torch.nn.modules.module.Module] = <class 'torch.nn.modules.activation.GELU'>, verbose: bool = False, filter_parameters: dict | None = None)[source]#
Bases:
EEGModuleMixin,ModuleIFNetV2 from Wang J et al (2023) [ifnet].
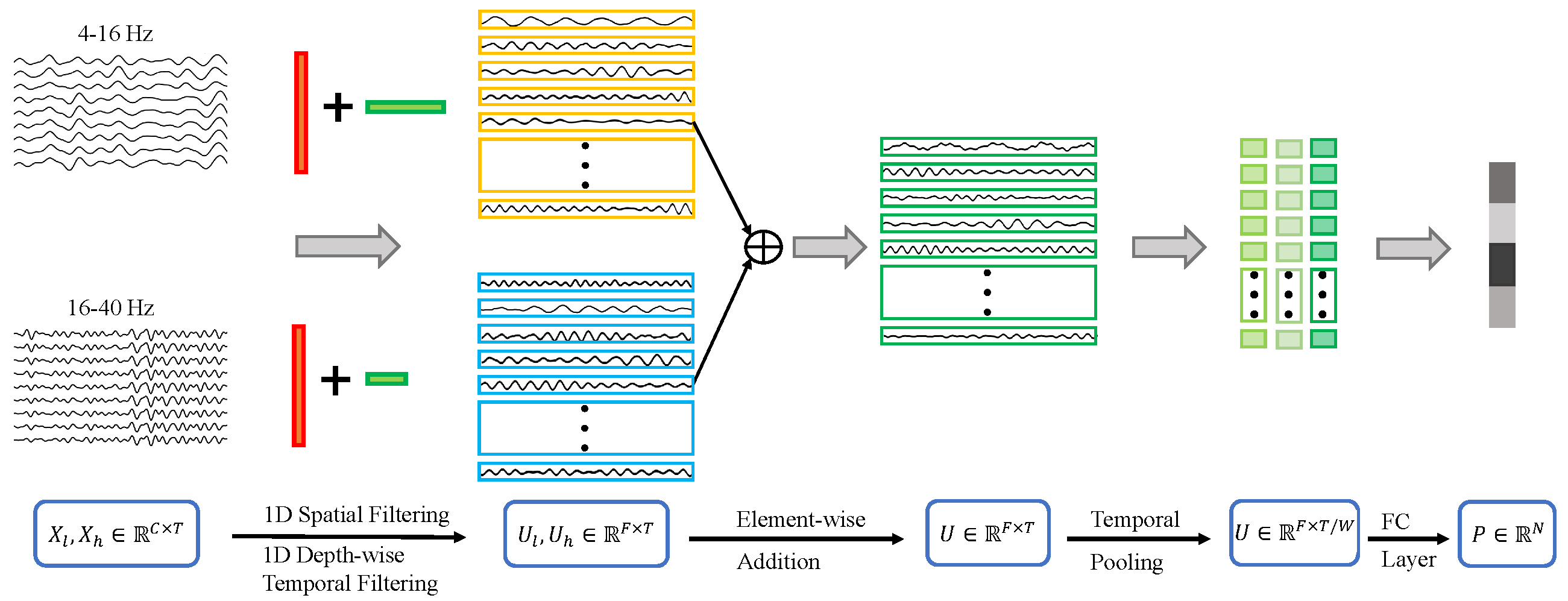
Overview of the Interactive Frequency Convolutional Neural Network architecture.
IFNetV2 is designed to effectively capture spectro-spatial-temporal features for motor imagery decoding from EEG data. The model consists of three stages: Spectro-Spatial Feature Representation, Cross-Frequency Interactions, and Classification.
Spectro-Spatial Feature Representation: The raw EEG signals are filtered into two characteristic frequency bands: low (4-16 Hz) and high (16-40 Hz), covering the most relevant motor imagery bands. Spectro-spatial features are then extracted through 1D point-wise spatial convolution followed by temporal convolution.
Cross-Frequency Interactions: The extracted spectro-spatial features from each frequency band are combined through an element-wise summation operation, which enhances feature representation while preserving distinct characteristics.
Classification: The aggregated spectro-spatial features are further reduced through temporal average pooling and passed through a fully connected layer followed by a softmax operation to generate output probabilities for each class.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
bands (list[tuple[int, int]] or int or None, default=[[4, 16], (16, 40)]) – Frequency bands for filtering.
n_filters_spat – The description is missing.
kernel_sizes (tuple of int, default=(63, 31)) – List of kernel sizes for temporal convolutions.
stride_factor – The description is missing.
drop_prob (float, default=0.5) – Dropout probability.
linear_max_norm – The description is missing.
activation (nn.Module, default=nn.GELU) – Activation function after the InterFrequency Layer.
verbose (bool, default=False) – Verbose to control the filtering layer
filter_parameters (dict, default={}) – Additional parameters for the filter bank layer.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented from the paper description and Torch source code [ifnetv2code]. Version 2 is present only in the repository, and the main difference is one pooling layer, describe at the TABLE VII from the paper: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10070810
References
[ifnet]Wang, J., Yao, L., & Wang, Y. (2023). IFNet: An interactive frequency convolutional neural network for enhancing motor imagery decoding from EEG. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31, 1900-1911.
[ifnetv2code]Wang, J., Yao, L., & Wang, Y. (2023). IFNet: An interactive frequency convolutional neural network for enhancing motor imagery decoding from EEG. Jiaheng-Wang/IFNet
- forward(x: Tensor) Tensor[source]#
Forward pass of IFNet.
- Parameters:
x (torch.Tensor) – Input tensor with shape (batch_size, n_chans, n_times).
- Returns:
Output tensor with shape (batch_size, n_outputs).
- Return type:
braindecode.models.labram module#
Labram module. Authors: Wei-Bang Jiang
Bruno Aristimunha <b.aristimunha@gmail.com>
License: BSD 3 clause
- class braindecode.models.labram.Labram(n_times=None, n_outputs=None, chs_info=None, n_chans=None, sfreq=None, input_window_seconds=None, patch_size=200, emb_size=200, in_channels=1, out_channels=8, n_layers=12, att_num_heads=10, mlp_ratio=4.0, qkv_bias=False, qk_norm=None, qk_scale=None, drop_prob=0.0, attn_drop_prob=0.0, drop_path_prob=0.0, norm_layer=<class 'torch.nn.modules.normalization.LayerNorm'>, init_values=None, use_abs_pos_emb=True, use_mean_pooling=True, init_scale=0.001, neural_tokenizer=True, attn_head_dim=None, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.GELU'>)[source]#
Bases:
EEGModuleMixin,ModuleLabram from Jiang, W B et al (2024) [Jiang2024].
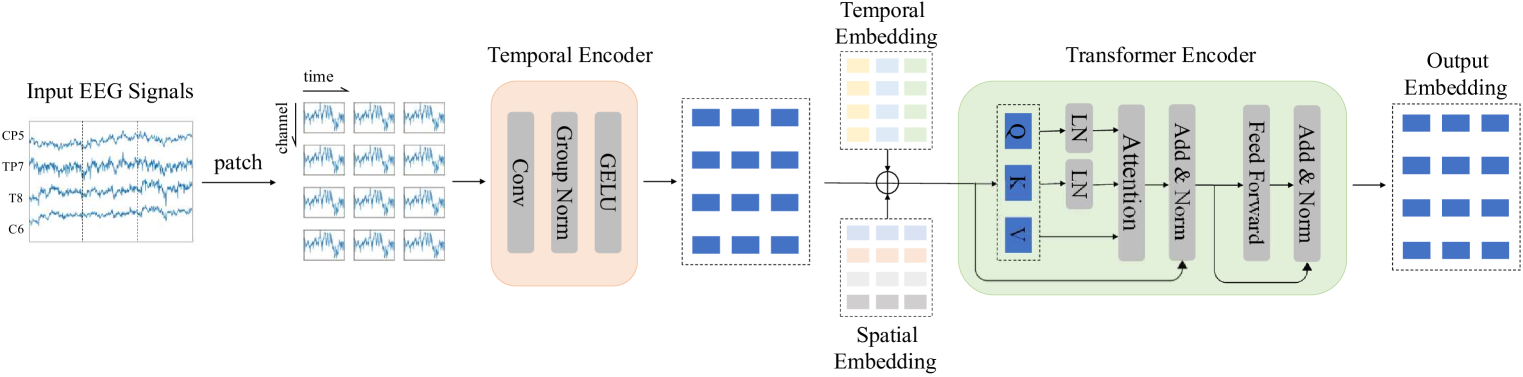
Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI from [Jiang2024]
This is an adaptation of the code [Code2024] from the Labram model.
The model is transformer architecture with strong inspiration from BEiTv2 [BeiTv2].
The models can be used in two modes: - Neural Tokenizor: Design to get an embedding layers (e.g. classification). - Neural Decoder: To extract the ampliture and phase outputs with a VQSNP.
The braindecode’s modification is to allow the model to be used in with an input shape of (batch, n_chans, n_times), if neural tokenizer equals True. The original implementation uses (batch, n_chans, n_patches, patch_size) as input with static segmentation of the input data.
The models have the following sequence of steps: if neural tokenizer:
SegmentPatch: Segment the input data in patches;
TemporalConv: Apply a temporal convolution to the segmented data;
Residual adding cls, temporal and position embeddings (optional);
WindowsAttentionBlock: Apply a windows attention block to the data;
LayerNorm: Apply layer normalization to the data;
Linear: An head linear layer to transformer the data into classes.
- else:
PatchEmbed: Apply a patch embedding to the input data;
Residual adding cls, temporal and position embeddings (optional);
WindowsAttentionBlock: Apply a windows attention block to the data;
LayerNorm: Apply layer normalization to the data;
Linear: An head linear layer to transformer the data into classes.
Added in version 0.9.
- Parameters:
n_times (int) – Number of time samples of the input window.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_chans (int) – Number of EEG channels.
sfreq (float) – Sampling frequency of the EEG recordings.
input_window_seconds (float) – Length of the input window in seconds.
patch_size (int) – The size of the patch to be used in the patch embedding.
emb_size (int) – The dimension of the embedding.
in_channels (int) – The number of convolutional input channels.
out_channels (int) – The number of convolutional output channels.
n_layers (int (default=12)) – The number of attention layers of the model.
att_num_heads (int (default=10)) – The number of attention heads.
mlp_ratio (float (default=4.0)) – The expansion ratio of the mlp layer
qkv_bias (bool (default=False)) – If True, add a learnable bias to the query, key, and value tensors.
qk_norm (Pytorch Normalize layer (default=None)) – If not None, apply LayerNorm to the query and key tensors
qk_scale (float (default=None)) – If not None, use this value as the scale factor. If None, use head_dim**-0.5, where head_dim = dim // num_heads.
drop_prob (float (default=0.0)) – Dropout rate for the attention weights.
attn_drop_prob (float (default=0.0)) – Dropout rate for the attention weights.
drop_path_prob (float (default=0.0)) – Dropout rate for the attention weights used on DropPath.
norm_layer (Pytorch Normalize layer (default=nn.LayerNorm)) – The normalization layer to be used.
init_values (float (default=None)) – If not None, use this value to initialize the gamma_1 and gamma_2 parameters.
use_abs_pos_emb (bool (default=True)) – If True, use absolute position embedding.
use_mean_pooling (bool (default=True)) – If True, use mean pooling.
init_scale (float (default=0.001)) – The initial scale to be used in the parameters of the model.
neural_tokenizer (bool (default=True)) – The model can be used in two modes: Neural Tokenizor or Neural Decoder.
attn_head_dim (bool (default=None)) – The head dimension to be used in the attention layer, to be used only during pre-training.
activation (nn.Module, default=nn.GELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.GELU.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Jiang2024] (1,2)Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu. 2024, May. Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. The Twelfth International Conference on Learning Representations, ICLR.
[Code2024]Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu. 2024. Labram Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. GitHub 935963004/LaBraM (accessed 2024-03-02)
[BeiTv2]Zhiliang Peng, Li Dong, Hangbo Bao, Qixiang Ye, Furu Wei. 2024. BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers. arXiv:2208.06366 [cs.CV]
- fix_init_weight_and_init_embedding()[source]#
Fix the initial weight and the initial embedding. Initializing with truncated normal distribution.
- forward(x, input_chans=None, return_patch_tokens=False, return_all_tokens=False)[source]#
Forward the input EEG data through the model.
- Parameters:
x (torch.Tensor) – The input data with shape (batch, n_chans, n_times) or (batch, n_chans, n_patches, patch size).
input_chans (int) – An input channel to select some dimensions
return_patch_tokens (bool) – Return the patch tokens
return_all_tokens (bool) – Return all the tokens
- Returns:
The output of the model with dimensions (batch, n_outputs)
- Return type:
- forward_features(x, input_chans=None, return_patch_tokens=False, return_all_tokens=False)[source]#
Forward the features of the model.
- Parameters:
x (torch.Tensor) – The input data with shape (batch, n_chans, n_patches, patch size), if neural decoder or (batch, n_chans, n_times), if neural tokenizer.
input_chans (int) – The number of input channels.
return_patch_tokens (bool) – Whether to return the patch tokens.
return_all_tokens (bool) – Whether to return all the tokens.
- Returns:
x – The output of the model.
- Return type:
braindecode.models.msvtnet module#
- class braindecode.models.msvtnet.MSVTNet(n_chans=None, n_outputs=None, n_times=None, input_window_seconds=None, sfreq=None, chs_info=None, n_filters_list: tuple[int, ...] = (9, 9, 9, 9), conv1_kernels_size: tuple[int, ...] = (15, 31, 63, 125), conv2_kernel_size: int = 15, depth_multiplier: int = 2, pool1_size: int = 8, pool2_size: int = 7, drop_prob: float = 0.3, num_heads: int = 8, feedforward_ratio: float = 1, drop_prob_trans: float = 0.5, num_layers: int = 2, activation: ~typing.Type[~torch.nn.modules.module.Module] = <class 'torch.nn.modules.activation.ELU'>, return_features: bool = False)[source]#
Bases:
EEGModuleMixin,ModuleMSVTNet model from Liu K et al (2024) from [msvt2024].
This model implements a multi-scale convolutional transformer network for EEG signal classification, as described in [msvt2024].
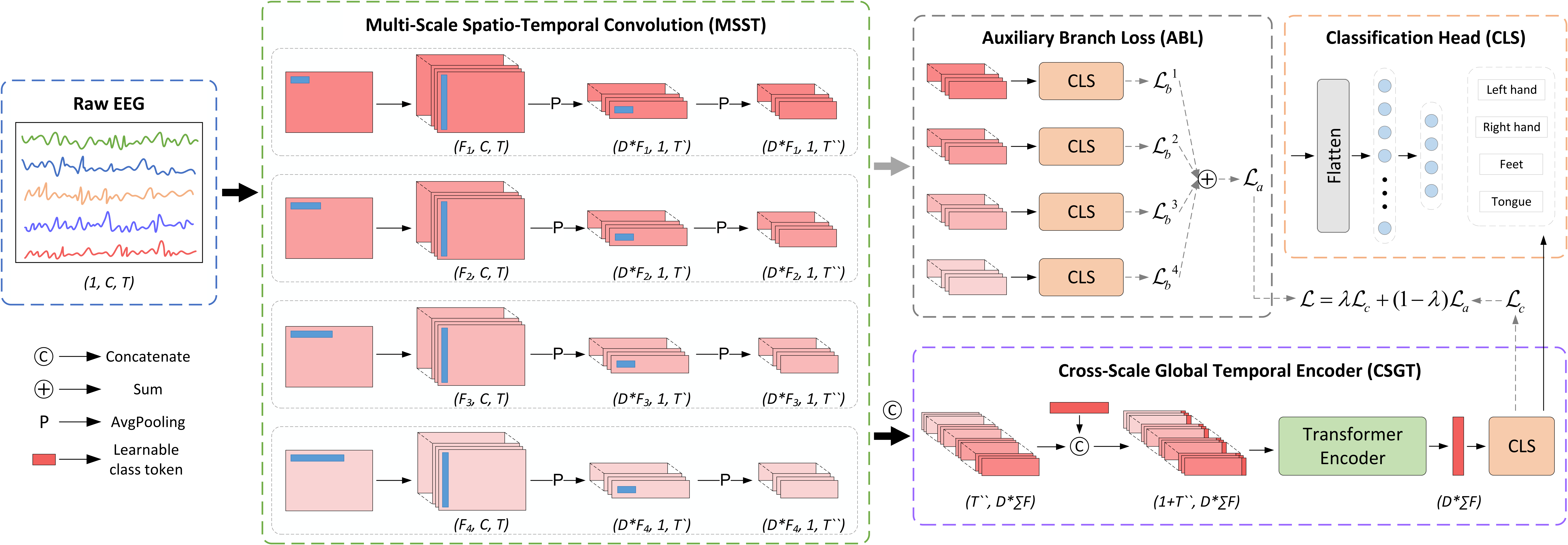
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_filters_list (list[int], optional) – List of filter numbers for each TSConv block, by default (9, 9, 9, 9).
conv1_kernels_size (list[int], optional) – List of kernel sizes for the first convolution in each TSConv block, by default (15, 31, 63, 125).
conv2_kernel_size (int, optional) – Kernel size for the second convolution in TSConv blocks, by default 15.
depth_multiplier (int, optional) – Depth multiplier for depthwise convolution, by default 2.
pool1_size (int, optional) – Pooling size for the first pooling layer in TSConv blocks, by default 8.
pool2_size (int, optional) – Pooling size for the second pooling layer in TSConv blocks, by default 7.
drop_prob (float, optional) – Dropout probability for convolutional layers, by default 0.3.
num_heads (int, optional) – Number of attention heads in the transformer encoder, by default 8.
feedforward_ratio (float, optional) – Ratio to compute feedforward dimension in the transformer, by default 1.
drop_prob_trans (float, optional) – Dropout probability for the transformer, by default 0.5.
num_layers (int, optional) – Number of transformer encoder layers, by default 2.
activation (Type[nn.Module], optional) – Activation function class to use, by default nn.ELU.
return_features (bool, optional) – Whether to return predictions from branch classifiers, by default False.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented based on the original code [msvt2024code].
References
[msvt2024] (1,2)Liu, K., et al. (2024). MSVTNet: Multi-Scale Vision Transformer Neural Network for EEG-Based Motor Imagery Decoding. IEEE Journal of Biomedical an Health Informatics.
[msvt2024code]Liu, K., et al. (2024). MSVTNet: Multi-Scale Vision Transformer Neural Network for EEG-Based Motor Imagery Decoding. Source Code: SheepTAO/MSVTNet
- forward(x: Tensor) Tensor[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
x – The description is missing.
braindecode.models.sccnet module#
- class braindecode.models.sccnet.SCCNet(n_chans=None, n_outputs=None, n_times=None, chs_info=None, input_window_seconds=None, sfreq=None, n_spatial_filters: int = 22, n_spatial_filters_smooth: int = 20, drop_prob: float = 0.5, activation: ~torch.nn.modules.module.Module = <class 'braindecode.modules.activation.LogActivation'>, batch_norm_momentum: float = 0.1)[source]#
Bases:
EEGModuleMixin,ModuleSCCNet from Wei, C S (2019) [sccnet].
Spatial component-wise convolutional network (SCCNet) for motor-imagery EEG classification.

- Spatial Component Analysis: Performs convolution spatial filtering
across all EEG channels to extract spatial components, effectively reducing the channel dimension.
- Spatio-Temporal Filtering: Applies convolution across the spatial
components and temporal domain to capture spatio-temporal patterns.
Temporal Smoothing (Pooling): Uses average pooling over time to smooth the features and reduce the temporal dimension, focusing on longer-term patterns.
Classification: Flattens the features and applies a fully connected layer.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_spatial_filters (int, optional) – Number of spatial filters in the first convolutional layer. Default is 22.
n_spatial_filters_smooth (int, optional) – Number of spatial filters used as filter in the second convolutional layer. Default is 20.
drop_prob (float, optional) – Dropout probability. Default is 0.5.
activation (nn.Module, optional) – Activation function after the second convolutional layer. Default is logarithm activation.
batch_norm_momentum – The description is missing.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors, only reimplemented from the paper description and the source that have not been tested [sccnetcode].
References
[sccnet]Wei, C. S., Koike-Akino, T., & Wang, Y. (2019, March). Spatial component-wise convolutional network (SCCNet) for motor-imagery EEG classification. In 2019 9th International IEEE/EMBS Conference on Neural Engineering (NER) (pp. 328-331). IEEE.
[sccnetcode]Hsieh, C. Y., Chou, J. L., Chang, Y. H., & Wei, C. S. XBrainLab: An Open-Source Software for Explainable Artificial Intelligence-Based EEG Analysis. In NeurIPS 2023 AI for Science Workshop.
- forward(x: Tensor) Tensor[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
x – The description is missing.
braindecode.models.shallow_fbcsp module#
- class braindecode.models.shallow_fbcsp.ShallowFBCSPNet(n_chans=None, n_outputs=None, n_times=None, n_filters_time=40, filter_time_length=25, n_filters_spat=40, pool_time_length=75, pool_time_stride=15, final_conv_length='auto', conv_nonlin=<function square>, pool_mode='mean', activation_pool_nonlin: ~torch.nn.modules.module.Module = <class 'braindecode.modules.activation.SafeLog'>, split_first_layer=True, batch_norm=True, batch_norm_alpha=0.1, drop_prob=0.5, chs_info=None, input_window_seconds=None, sfreq=None)[source]#
Bases:
EEGModuleMixin,SequentialShallow ConvNet model from Schirrmeister et al (2017) [Schirrmeister2017].

Model described in [Schirrmeister2017].
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
n_filters_time (int) – Number of temporal filters.
filter_time_length (int) – Length of the temporal filter.
n_filters_spat (int) – Number of spatial filters.
pool_time_length (int) – Length of temporal pooling filter.
pool_time_stride (int) – Length of stride between temporal pooling filters.
final_conv_length (int | str) – Length of the final convolution layer. If set to “auto”, length of the input signal must be specified.
conv_nonlin (callable) – Non-linear function to be used after convolution layers.
pool_mode (str) – Method to use on pooling layers. “max” or “mean”.
activation_pool_nonlin (callable) – Non-linear function to be used after pooling layers.
split_first_layer (bool) – Split first layer into temporal and spatial layers (True) or just use temporal (False). There would be no non-linearity between the split layers.
batch_norm (bool) – Whether to use batch normalisation.
batch_norm_alpha (float) – Momentum for BatchNorm2d.
drop_prob (float) – Dropout probability.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Schirrmeister2017] (1,2)Schirrmeister, R. T., Springenberg, J. T., Fiederer, L. D. J., Glasstetter, M., Eggensperger, K., Tangermann, M., Hutter, F. & Ball, T. (2017). Deep learning with convolutional neural networks for EEG decoding and visualization. Human Brain Mapping , Aug. 2017. Online: http://dx.doi.org/10.1002/hbm.23730
braindecode.models.signal_jepa module#
- class braindecode.models.signal_jepa.SignalJEPA(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, *, feature_encoder__conv_layers_spec: ~typing.Sequence[tuple[int, int, int]] = ((8, 32, 8), (16, 2, 2), (32, 2, 2), (64, 2, 2), (64, 2, 2)), drop_prob: float = 0.0, feature_encoder__mode: str = 'default', feature_encoder__conv_bias: bool = False, activation: type[~torch.nn.modules.module.Module] = <class 'torch.nn.modules.activation.GELU'>, pos_encoder__spat_dim: int = 30, pos_encoder__time_dim: int = 34, pos_encoder__sfreq_features: float = 1.0, pos_encoder__spat_kwargs: dict | None = None, transformer__d_model: int = 64, transformer__num_encoder_layers: int = 8, transformer__num_decoder_layers: int = 4, transformer__nhead: int = 8)[source]#
Bases:
_BaseSignalJEPAArchitecture introduced in signal-JEPA for self-supervised pre-training, Guetschel, P et al (2024) [1]
This model is not meant for classification but for SSL pre-training. Its output shape depends on the input shape. For classification purposes, three variants of this model are available:
The classification architectures can either be instantiated from scratch (random parameters) or from a pre-trained
SignalJEPAmodel.Added in version 0.9.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
feature_encoder__conv_layers_spec (list of tuple) –
tuples have shape
(dim, k, stride)where:dim: number of output channels of the layer (unrelated to EEG channels);k: temporal length of the layer’s kernel;stride: temporal stride of the layer’s kernel.
drop_prob (float)
feature_encoder__mode (str) – Normalisation mode. Either
defaultorlayer_norm.feature_encoder__conv_bias (bool)
activation (nn.Module) – Activation layer for the feature encoder.
pos_encoder__spat_dim (int) – Number of dimensions to use to encode the spatial position of the patch, i.e. the EEG channel.
pos_encoder__time_dim (int) – Number of dimensions to use to encode the temporal position of the patch.
pos_encoder__sfreq_features (float) – The “downsampled” sampling frequency returned by the feature encoder.
pos_encoder__spat_kwargs (dict) – Additional keyword arguments to pass to the
nn.Embeddinglayer used to embed the channel names.transformer__d_model (int) – The number of expected features in the encoder/decoder inputs.
transformer__num_encoder_layers (int) – The number of encoder layers in the transformer.
transformer__num_decoder_layers (int) – The number of decoder layers in the transformer.
transformer__nhead (int) – The number of heads in the multiheadattention models.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[1]Guetschel, P., Moreau, T., & Tangermann, M. (2024). S-JEPA: towards seamless cross-dataset transfer through dynamic spatial attention. In 9th Graz Brain-Computer Interface Conference, https://www.doi.org/10.3217/978-3-99161-014-4-003
- forward(X, ch_idxs: Tensor | None = None)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
X – The description is missing.
ch_idxs – The description is missing.
- class braindecode.models.signal_jepa.SignalJEPA_Contextual(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, *, n_spat_filters: int = 4, feature_encoder__conv_layers_spec: ~typing.Sequence[tuple[int, int, int]] = ((8, 32, 8), (16, 2, 2), (32, 2, 2), (64, 2, 2), (64, 2, 2)), drop_prob: float = 0.0, feature_encoder__mode: str = 'default', feature_encoder__conv_bias: bool = False, activation: type[~torch.nn.modules.module.Module] = <class 'torch.nn.modules.activation.GELU'>, pos_encoder__spat_dim: int = 30, pos_encoder__time_dim: int = 34, pos_encoder__sfreq_features: float = 1.0, pos_encoder__spat_kwargs: dict | None = None, transformer__d_model: int = 64, transformer__num_encoder_layers: int = 8, transformer__num_decoder_layers: int = 4, transformer__nhead: int = 8, _init_feature_encoder: bool = True, _init_transformer: bool = True)[source]#
Bases:
_BaseSignalJEPAContextual downstream architecture introduced in signal-JEPA Guetschel, P et al (2024) [1].
This architecture is one of the variants of
SignalJEPAthat can be used for classification purposes.
Added in version 0.9.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_spat_filters (int) – Number of spatial filters.
feature_encoder__conv_layers_spec (list of tuple) –
tuples have shape
(dim, k, stride)where:dim: number of output channels of the layer (unrelated to EEG channels);k: temporal length of the layer’s kernel;stride: temporal stride of the layer’s kernel.
drop_prob (float)
feature_encoder__mode (str) – Normalisation mode. Either
defaultorlayer_norm.feature_encoder__conv_bias (bool)
activation (nn.Module) – Activation layer for the feature encoder.
pos_encoder__spat_dim (int) – Number of dimensions to use to encode the spatial position of the patch, i.e. the EEG channel.
pos_encoder__time_dim (int) – Number of dimensions to use to encode the temporal position of the patch.
pos_encoder__sfreq_features (float) – The “downsampled” sampling frequency returned by the feature encoder.
pos_encoder__spat_kwargs (dict) – Additional keyword arguments to pass to the
nn.Embeddinglayer used to embed the channel names.transformer__d_model (int) – The number of expected features in the encoder/decoder inputs.
transformer__num_encoder_layers (int) – The number of encoder layers in the transformer.
transformer__num_decoder_layers (int) – The number of decoder layers in the transformer.
transformer__nhead (int) – The number of heads in the multiheadattention models.
_init_feature_encoder (bool) – Do not change the default value (used for internal purposes).
_init_transformer (bool) – Do not change the default value (used for internal purposes).
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[1]Guetschel, P., Moreau, T., & Tangermann, M. (2024). S-JEPA: towards seamless cross-dataset transfer through dynamic spatial attention. In 9th Graz Brain-Computer Interface Conference, https://www.doi.org/10.3217/978-3-99161-014-4-003
- forward(X, ch_idxs: Tensor | None = None)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
X – The description is missing.
ch_idxs – The description is missing.
- classmethod from_pretrained(model: SignalJEPA, n_outputs: int, n_spat_filters: int = 4, chs_info: list[dict[str, Any]] | None = None)[source]#
Instantiate a new model from a pre-trained
SignalJEPAmodel.- Parameters:
model (SignalJEPA) – Pre-trained model.
n_outputs (int) – Number of classes for the new model.
n_spat_filters (int) – Number of spatial filters.
chs_info (list of dict | None) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.
- class braindecode.models.signal_jepa.SignalJEPA_PostLocal(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, *, n_spat_filters: int = 4, feature_encoder__conv_layers_spec: ~typing.Sequence[tuple[int, int, int]] = ((8, 32, 8), (16, 2, 2), (32, 2, 2), (64, 2, 2), (64, 2, 2)), drop_prob: float = 0.0, feature_encoder__mode: str = 'default', feature_encoder__conv_bias: bool = False, activation: type[~torch.nn.modules.module.Module] = <class 'torch.nn.modules.activation.GELU'>, pos_encoder__spat_dim: int = 30, pos_encoder__time_dim: int = 34, pos_encoder__sfreq_features: float = 1.0, pos_encoder__spat_kwargs: dict | None = None, transformer__d_model: int = 64, transformer__num_encoder_layers: int = 8, transformer__num_decoder_layers: int = 4, transformer__nhead: int = 8, _init_feature_encoder: bool = True)[source]#
Bases:
_BaseSignalJEPAPost-local downstream architecture introduced in signal-JEPA Guetschel, P et al (2024) [1].
This architecture is one of the variants of
SignalJEPAthat can be used for classification purposes.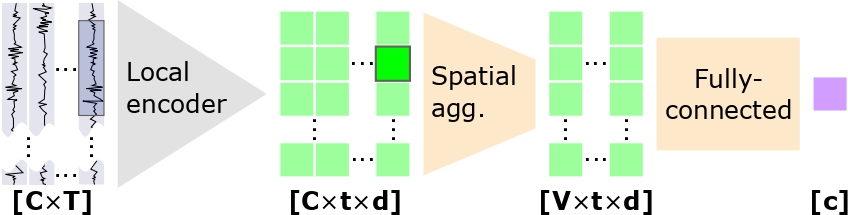
Added in version 0.9.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_spat_filters (int) – Number of spatial filters.
feature_encoder__conv_layers_spec (list of tuple) –
tuples have shape
(dim, k, stride)where:dim: number of output channels of the layer (unrelated to EEG channels);k: temporal length of the layer’s kernel;stride: temporal stride of the layer’s kernel.
drop_prob (float)
feature_encoder__mode (str) – Normalisation mode. Either
defaultorlayer_norm.feature_encoder__conv_bias (bool)
activation (nn.Module) – Activation layer for the feature encoder.
pos_encoder__spat_dim (int) – Number of dimensions to use to encode the spatial position of the patch, i.e. the EEG channel.
pos_encoder__time_dim (int) – Number of dimensions to use to encode the temporal position of the patch.
pos_encoder__sfreq_features (float) – The “downsampled” sampling frequency returned by the feature encoder.
pos_encoder__spat_kwargs (dict) – Additional keyword arguments to pass to the
nn.Embeddinglayer used to embed the channel names.transformer__d_model (int) – The number of expected features in the encoder/decoder inputs.
transformer__num_encoder_layers (int) – The number of encoder layers in the transformer.
transformer__num_decoder_layers (int) – The number of decoder layers in the transformer.
transformer__nhead (int) – The number of heads in the multiheadattention models.
_init_feature_encoder (bool) – Do not change the default value (used for internal purposes).
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[1]Guetschel, P., Moreau, T., & Tangermann, M. (2024). S-JEPA: towards seamless cross-dataset transfer through dynamic spatial attention. In 9th Graz Brain-Computer Interface Conference, https://www.doi.org/10.3217/978-3-99161-014-4-003
- forward(X)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
X – The description is missing.
- classmethod from_pretrained(model: SignalJEPA, n_outputs: int, n_spat_filters: int = 4)[source]#
Instantiate a new model from a pre-trained
SignalJEPAmodel.- Parameters:
model (SignalJEPA) – Pre-trained model.
n_outputs (int) – Number of classes for the new model.
n_spat_filters (int) – Number of spatial filters.
chs_info (list of dict | None) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.
- class braindecode.models.signal_jepa.SignalJEPA_PreLocal(n_outputs=None, n_chans=None, chs_info=None, n_times=None, input_window_seconds=None, sfreq=None, *, n_spat_filters: int = 4, feature_encoder__conv_layers_spec: ~typing.Sequence[tuple[int, int, int]] = ((8, 32, 8), (16, 2, 2), (32, 2, 2), (64, 2, 2), (64, 2, 2)), drop_prob: float = 0.0, feature_encoder__mode: str = 'default', feature_encoder__conv_bias: bool = False, activation: type[~torch.nn.modules.module.Module] = <class 'torch.nn.modules.activation.GELU'>, pos_encoder__spat_dim: int = 30, pos_encoder__time_dim: int = 34, pos_encoder__sfreq_features: float = 1.0, pos_encoder__spat_kwargs: dict | None = None, transformer__d_model: int = 64, transformer__num_encoder_layers: int = 8, transformer__num_decoder_layers: int = 4, transformer__nhead: int = 8, _init_feature_encoder: bool = True)[source]#
Bases:
_BaseSignalJEPAPre-local downstream architecture introduced in signal-JEPA Guetschel, P et al (2024) [1].
This architecture is one of the variants of
SignalJEPAthat can be used for classification purposes.
Added in version 0.9.
- Parameters:
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_chans (int) – Number of EEG channels.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
n_spat_filters (int) – Number of spatial filters.
feature_encoder__conv_layers_spec (list of tuple) –
tuples have shape
(dim, k, stride)where:dim: number of output channels of the layer (unrelated to EEG channels);k: temporal length of the layer’s kernel;stride: temporal stride of the layer’s kernel.
drop_prob (float)
feature_encoder__mode (str) – Normalisation mode. Either
defaultorlayer_norm.feature_encoder__conv_bias (bool)
activation (nn.Module) – Activation layer for the feature encoder.
pos_encoder__spat_dim (int) – Number of dimensions to use to encode the spatial position of the patch, i.e. the EEG channel.
pos_encoder__time_dim (int) – Number of dimensions to use to encode the temporal position of the patch.
pos_encoder__sfreq_features (float) – The “downsampled” sampling frequency returned by the feature encoder.
pos_encoder__spat_kwargs (dict) – Additional keyword arguments to pass to the
nn.Embeddinglayer used to embed the channel names.transformer__d_model (int) – The number of expected features in the encoder/decoder inputs.
transformer__num_encoder_layers (int) – The number of encoder layers in the transformer.
transformer__num_decoder_layers (int) – The number of decoder layers in the transformer.
transformer__nhead (int) – The number of heads in the multiheadattention models.
_init_feature_encoder (bool) – Do not change the default value (used for internal purposes).
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[1]Guetschel, P., Moreau, T., & Tangermann, M. (2024). S-JEPA: towards seamless cross-dataset transfer through dynamic spatial attention. In 9th Graz Brain-Computer Interface Conference, https://www.doi.org/10.3217/978-3-99161-014-4-003
- forward(X)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
X – The description is missing.
- classmethod from_pretrained(model: SignalJEPA, n_outputs: int, n_spat_filters: int = 4)[source]#
Instantiate a new model from a pre-trained
SignalJEPAmodel.- Parameters:
model (SignalJEPA) – Pre-trained model.
n_outputs (int) – Number of classes for the new model.
n_spat_filters (int) – Number of spatial filters.
chs_info (list of dict | None) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.
braindecode.models.sinc_shallow module#
- class braindecode.models.sinc_shallow.SincShallowNet(num_time_filters: int = 32, time_filter_len: int = 33, depth_multiplier: int = 2, activation: ~torch.nn.modules.module.Module | None = <class 'torch.nn.modules.activation.ELU'>, drop_prob: float = 0.5, first_freq: float = 5.0, min_freq: float = 1.0, freq_stride: float = 1.0, padding: str = 'same', bandwidth: float = 4.0, pool_size: int = 55, pool_stride: int = 12, n_chans=None, n_outputs=None, n_times=None, input_window_seconds=None, sfreq=None, chs_info=None)[source]#
Bases:
EEGModuleMixin,ModuleSinc-ShallowNet from Borra, D et al (2020) [borra2020].

The Sinc-ShallowNet architecture has these fundamental blocks:
- Block 1: Spectral and Spatial Feature Extraction
- Temporal Sinc-Convolutional Layer:
Uses parametrized sinc functions to learn band-pass filters, significantly reducing the number of trainable parameters by only learning the lower and upper cutoff frequencies for each filter.
- Spatial Depthwise Convolutional Layer:
Applies depthwise convolutions to learn spatial filters for each temporal feature map independently, further reducing parameters and enhancing interpretability.
Batch Normalization
- Block 2: Temporal Aggregation
Activation Function: ELU
Average Pooling Layer: Aggregation by averaging spatial dim
Dropout Layer
Flatten Layer
- Block 3: Classification
Fully Connected Layer: Maps the feature vector to n_outputs.
Implementation Notes:
- The sinc-convolutional layer initializes cutoff frequencies uniformly
within the desired frequency range and updates them during training while ensuring the lower cutoff is less than the upper cutoff.
- Parameters:
num_time_filters (int) – Number of temporal filters in the SincFilter layer.
time_filter_len (int) – Size of the temporal filters.
depth_multiplier (int) – Depth multiplier for spatial filtering.
activation (nn.Module, optional) – Activation function to use. Default is nn.ELU().
drop_prob (float, optional) – Dropout probability. Default is 0.5.
first_freq (float, optional) – The starting frequency for the first Sinc filter. Default is 5.0.
min_freq (float, optional) – Minimum frequency allowed for the low frequencies of the filters. Default is 1.0.
freq_stride (float, optional) – Frequency stride for the Sinc filters. Controls the spacing between the filter frequencies. Default is 1.0.
padding (str, optional) – Padding mode for convolution, either ‘same’ or ‘valid’. Default is ‘same’.
bandwidth (float, optional) – Initial bandwidth for each Sinc filter. Default is 4.0.
pool_size (int, optional) – Size of the pooling window for the average pooling layer. Default is 55.
pool_stride (int, optional) – Stride of the pooling operation. Default is 12.
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is based on the implementation from [sincshallowcode].
References
[borra2020]Borra, D., Fantozzi, S., & Magosso, E. (2020). Interpretable and lightweight convolutional neural network for EEG decoding: Application to movement execution and imagination. Neural Networks, 129, 55-74.
[sincshallowcode]Sinc-ShallowNet re-implementation source code: marcellosicbaldi/SincNet-Tensorflow
- forward(x: Tensor) Tensor[source]#
Forward pass of the model.
- Parameters:
x (torch.Tensor) – Input tensor of shape [batch_size, num_channels, num_samples].
- Returns:
Output logits of shape [batch_size, num_classes].
- Return type:
braindecode.models.sleep_stager_blanco_2020 module#
- class braindecode.models.sleep_stager_blanco_2020.SleepStagerBlanco2020(n_chans=None, sfreq=None, n_conv_chans=20, input_window_seconds=None, n_outputs=5, n_groups=2, max_pool_size=2, drop_prob=0.5, apply_batch_norm=False, return_feats=False, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, chs_info=None, n_times=None)[source]#
Bases:
EEGModuleMixin,ModuleSleep staging architecture from Blanco et al. (2020) from [Blanco2020]
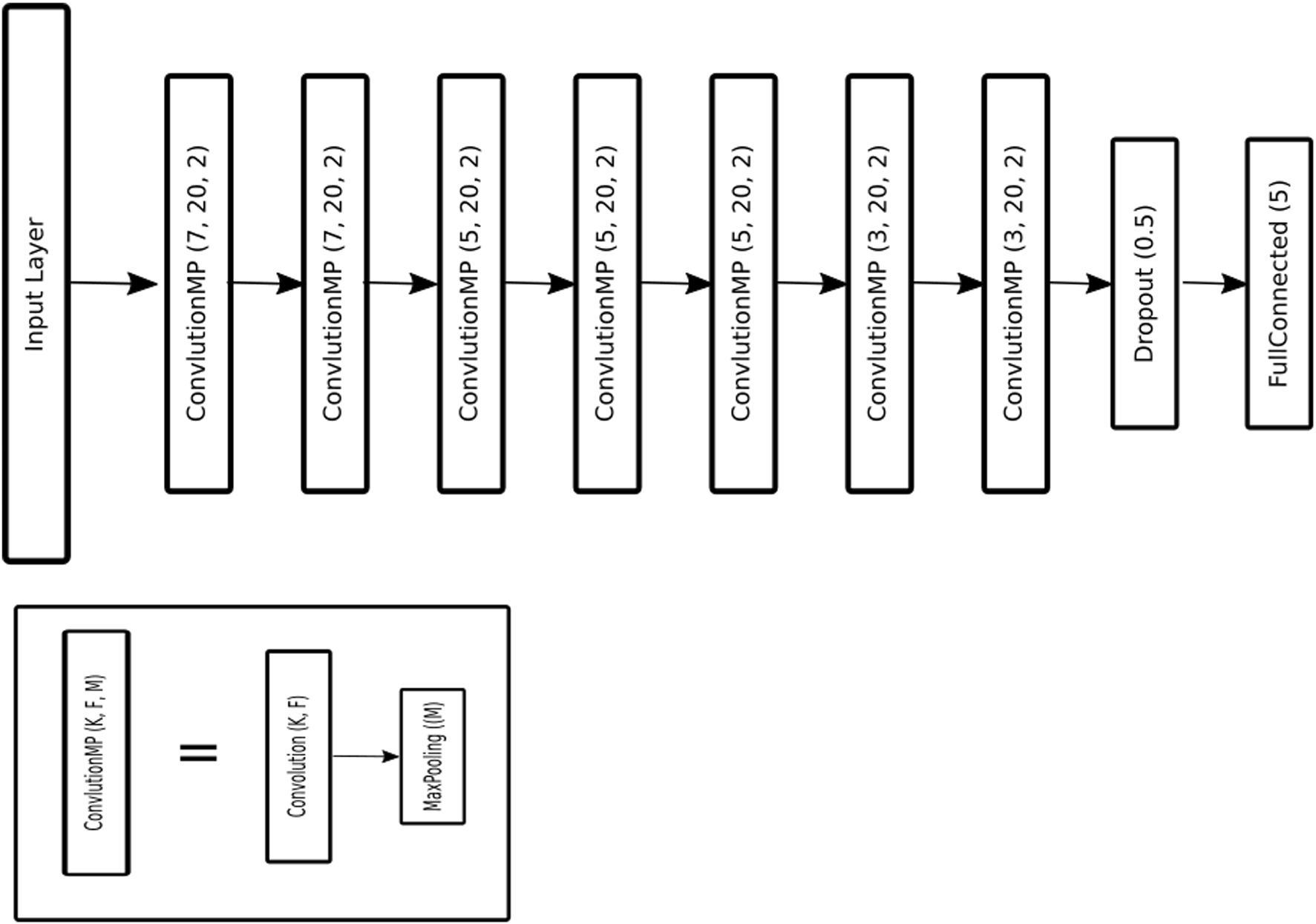
Convolutional neural network for sleep staging described in [Blanco2020]. A series of seven convolutional layers with kernel sizes running down from 7 to 3, in an attempt to extract more general features at the beginning, while more specific and complex features were extracted in the final stages.
- Parameters:
n_chans (int) – Number of EEG channels.
sfreq (float) – Sampling frequency of the EEG recordings.
n_conv_chans (int) – Number of convolutional channels. Set to 20 in [Blanco2020].
input_window_seconds (float) – Length of the input window in seconds.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_groups (int) – Number of groups for the convolution. Set to 2 in [Blanco2020] for 2 Channel EEG. controls the connections between inputs and outputs. n_channels and n_conv_chans must be divisible by n_groups.
max_pool_size – The description is missing.
drop_prob (float) – Dropout rate before the output dense layer.
apply_batch_norm (bool) – If True, apply batch normalization after both temporal convolutional layers.
return_feats (bool) – If True, return the features, i.e. the output of the feature extractor (before the final linear layer). If False, pass the features through the final linear layer.
activation (nn.Module, default=nn.ReLU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ReLU.chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Blanco2020] (1,2,3,4)Fernandez-Blanco, E., Rivero, D. & Pazos, A. Convolutional neural networks for sleep stage scoring on a two-channel EEG signal. Soft Comput 24, 4067–4079 (2020). https://doi.org/10.1007/s00500-019-04174-1
- forward(x)[source]#
Forward pass.
- Parameters:
x (torch.Tensor) – Batch of EEG windows of shape (batch_size, n_channels, n_times).
braindecode.models.sleep_stager_chambon_2018 module#
- class braindecode.models.sleep_stager_chambon_2018.SleepStagerChambon2018(n_chans=None, sfreq=None, n_conv_chs=8, time_conv_size_s=0.5, max_pool_size_s=0.125, pad_size_s=0.25, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, input_window_seconds=None, n_outputs=5, drop_prob=0.25, apply_batch_norm=False, return_feats=False, chs_info=None, n_times=None)[source]#
Bases:
EEGModuleMixin,ModuleSleep staging architecture from Chambon et al. (2018) [Chambon2018].
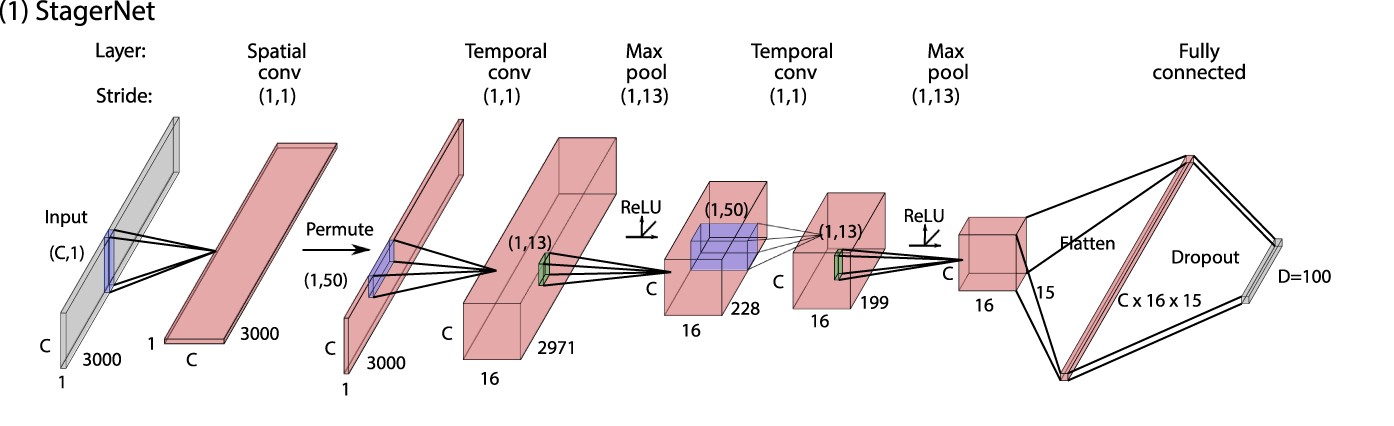
Convolutional neural network for sleep staging described in [Chambon2018].
- Parameters:
n_chans (int) – Number of EEG channels.
sfreq (float) – Sampling frequency of the EEG recordings.
n_conv_chs (int) – Number of convolutional channels. Set to 8 in [Chambon2018].
time_conv_size_s (float) – Size of filters in temporal convolution layers, in seconds. Set to 0.5 in [Chambon2018] (64 samples at sfreq=128).
max_pool_size_s (float) – Max pooling size, in seconds. Set to 0.125 in [Chambon2018] (16 samples at sfreq=128).
pad_size_s (float) – Padding size, in seconds. Set to 0.25 in [Chambon2018] (half the temporal convolution kernel size).
activation (nn.Module, default=nn.ReLU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ReLU.input_window_seconds (float) – Length of the input window in seconds.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
drop_prob (float) – Dropout rate before the output dense layer.
apply_batch_norm (bool) – If True, apply batch normalization after both temporal convolutional layers.
return_feats (bool) – If True, return the features, i.e. the output of the feature extractor (before the final linear layer). If False, pass the features through the final linear layer.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
[Chambon2018] (1,2,3,4,5,6)Chambon, S., Galtier, M. N., Arnal, P. J., Wainrib, G., & Gramfort, A. (2018). A deep learning architecture for temporal sleep stage classification using multivariate and multimodal time series. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 26(4), 758-769.
- forward(x: Tensor) Tensor[source]#
Forward pass.
- Parameters:
x (torch.Tensor) – Batch of EEG windows of shape (batch_size, n_channels, n_times).
braindecode.models.sleep_stager_eldele_2021 module#
- class braindecode.models.sleep_stager_eldele_2021.SleepStagerEldele2021(sfreq=None, n_tce=2, d_model=80, d_ff=120, n_attn_heads=5, drop_prob=0.1, activation_mrcnn: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.GELU'>, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, input_window_seconds=None, n_outputs=None, after_reduced_cnn_size=30, return_feats=False, chs_info=None, n_chans=None, n_times=None)[source]#
Bases:
EEGModuleMixin,ModuleSleep Staging Architecture from Eldele et al. (2021) [Eldele2021].
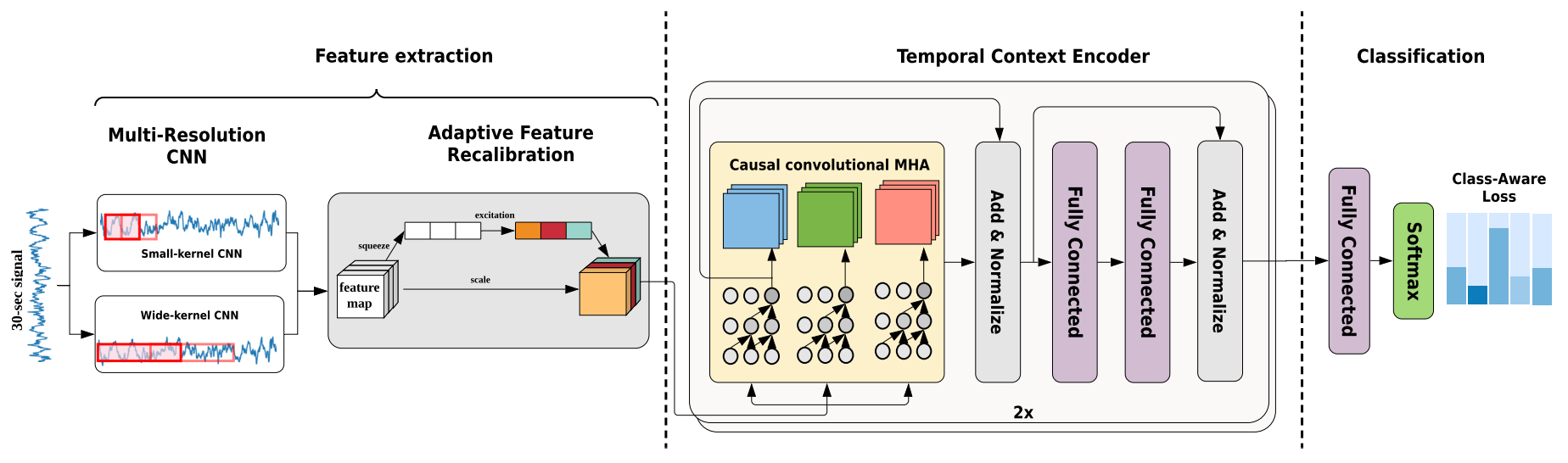
Attention based Neural Net for sleep staging as described in [Eldele2021]. The code for the paper and this model is also available at [1]. Takes single channel EEG as input. Feature extraction module based on multi-resolution convolutional neural network (MRCNN) and adaptive feature recalibration (AFR). The second module is the temporal context encoder (TCE) that leverages a multi-head attention mechanism to capture the temporal dependencies among the extracted features.
Warning - This model was designed for signals of 30 seconds at 100Hz or 125Hz (in which case the reference architecture from [1] which was validated on SHHS dataset [2] will be used) to use any other input is likely to make the model perform in unintended ways.
- Parameters:
sfreq (float) – Sampling frequency of the EEG recordings.
n_tce (int) – Number of TCE clones.
d_model (int) – Input dimension for the TCE. Also the input dimension of the first FC layer in the feed forward and the output of the second FC layer in the same. Increase for higher sampling rate/signal length. It should be divisible by n_attn_heads
d_ff (int) – Output dimension of the first FC layer in the feed forward and the input dimension of the second FC layer in the same.
n_attn_heads (int) – Number of attention heads. It should be a factor of d_model
drop_prob (float) – Dropout rate in the PositionWiseFeedforward layer and the TCE layers.
activation_mrcnn (nn.Module, default=nn.ReLU) – Activation function class to apply in the Mask R-CNN layer. Should be a PyTorch activation module class like
nn.ReLUornn.GELU. Default isnn.GELU.activation (nn.Module, default=nn.ReLU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ReLU.input_window_seconds (float) – Length of the input window in seconds.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
after_reduced_cnn_size (int) – Number of output channels produced by the convolution in the AFR module.
return_feats (bool) – If True, return the features, i.e. the output of the feature extractor (before the final linear layer). If False, pass the features through the final linear layer.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_chans (int) – Number of EEG channels.
n_times (int) – Number of time samples of the input window.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
- forward(x: Tensor) Tensor[source]#
Forward pass.
- Parameters:
x (torch.Tensor) – Batch of EEG windows of shape (batch_size, n_channels, n_times).
- return_feats#
if return_feats: raise ValueError(“return_feat == True is not accepted anymore”)
braindecode.models.sparcnet module#
- class braindecode.models.sparcnet.SPARCNet(n_chans=None, n_times=None, n_outputs=None, block_layers: int = 4, growth_rate: int = 16, bottleneck_size: int = 16, drop_prob: float = 0.5, conv_bias: bool = True, batch_norm: bool = True, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, chs_info=None, input_window_seconds=None, sfreq=None)[source]#
Bases:
EEGModuleMixin,ModuleSeizures, Periodic and Rhythmic pattern Continuum Neural Network (SPaRCNet) from Jing et al. (2023) [jing2023].
This is a temporal CNN model for biosignal classification based on the DenseNet architecture.
The model is based on the unofficial implementation [Code2023].
Added in version 0.9.
- Parameters:
n_chans (int) – Number of EEG channels.
n_times (int) – Number of time samples of the input window.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
block_layers (int, optional) – Number of layers per dense block. Default is 4.
growth_rate (int, optional) – Growth rate of the DenseNet. Default is 16.
bottleneck_size – The description is missing.
drop_prob (float, optional) – Dropout rate. Default is 0.5.
conv_bias (bool, optional) – Whether to use bias in convolutional layers. Default is True.
batch_norm (bool, optional) – Whether to use batch normalization. Default is True.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors.
References
[jing2023]Jing, J., Ge, W., Hong, S., Fernandes, M. B., Lin, Z., Yang, C., … & Westover, M. B. (2023). Development of expert-level classification of seizures and rhythmic and periodic patterns during eeg interpretation. Neurology, 100(17), e1750-e1762.
[Code2023]Yang, C., Westover, M.B. and Sun, J., 2023. BIOT Biosignal Transformer for Cross-data Learning in the Wild. GitHub ycq091044/BIOT (accessed 2024-02-13)
- forward(X: Tensor)[source]#
Forward pass of the model.
- Parameters:
X (torch.Tensor) – The input tensor of the model with shape (batch_size, n_channels, n_times)
- Returns:
The output tensor of the model with shape (batch_size, n_outputs)
- Return type:
braindecode.models.syncnet module#
- class braindecode.models.syncnet.SyncNet(n_chans=None, n_times=None, n_outputs=None, chs_info=None, input_window_seconds=None, sfreq=None, num_filters=1, filter_width=40, pool_size=40, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, ampli_init_values: tuple[float, float] = (-0.05, 0.05), omega_init_values: tuple[float, float] = (0.0, 1.0), beta_init_values: tuple[float, float] = (0.0, 0.05), phase_init_values: tuple[float, float] = (0.0, 0.05))[source]#
Bases:
EEGModuleMixin,ModuleSynchronization Network (SyncNet) from Li, Y et al (2017) [Li2017].
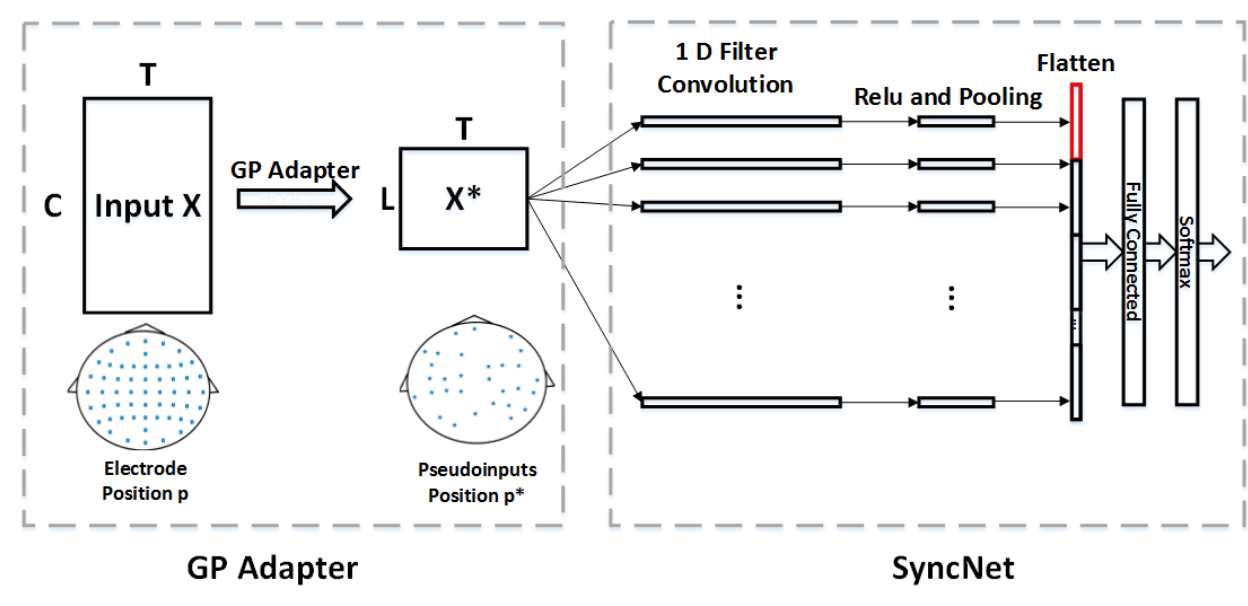
SyncNet uses parameterized 1-dimensional convolutional filters inspired by the Morlet wavelet to extract features from EEG signals. The filters are dynamically generated based on learnable parameters that control the oscillation and decay characteristics.
The filter for channel
cand filterkis defined as:\[f_c^{(k)}(\tau) = amplitude_c^{(k)} \cos(\omega^{(k)} \tau + \phi_c^{(k)}) \exp(-\beta^{(k)} \tau^2)\]where: - \(amplitude_c^{(k)}\) is the amplitude parameter (channel-specific). - \(\omega^{(k)}\) is the frequency parameter (shared across channels). - \(\phi_c^{(k)}\) is the phase shift (channel-specific). - \(\beta^{(k)}\) is the decay parameter (shared across channels). - \(\tau\) is the time index.
- Parameters:
n_chans (int) – Number of EEG channels.
n_times (int) – Number of time samples of the input window.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
num_filters (int, optional) – Number of filters in the convolutional layer. Default is 1.
filter_width (int, optional) – Width of the convolutional filters. Default is 40.
pool_size (int, optional) – Size of the pooling window. Default is 40.
activation (nn.Module, optional) – Activation function to apply after pooling. Default is
nn.ReLU.ampli_init_values (tuple of float, optional) – The initialization range for amplitude parameter using uniform distribution. Default is (-0.05, 0.05).
omega_init_values (tuple of float, optional) – The initialization range for omega parameters using uniform distribution. Default is (0, 1).
beta_init_values (tuple of float, optional) – The initialization range for beta parameters using uniform distribution. Default is (0, 1). Default is (0, 0.05).
phase_init_values (tuple of float, optional) – The initialization range for phase parameters using normal distribution. Default is (0, 1). Default is (0, 0.05).
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct! it has not been checked by original authors. The modifications are based on derivated code from [CodeICASSP2025].
References
[Li2017]Li, Y., Dzirasa, K., Carin, L., & Carlson, D. E. (2017). Targeting EEG/LFP synchrony with neural nets. Advances in neural information processing systems, 30.
[CodeICASSP2025]Code from Baselines for EEG-Music Emotion Recognition Grand Challenge at ICASSP 2025. SalvoCalcagno/eeg-music-challenge-icassp-2025-baselines
- forward(x)[source]#
Forward pass of the SyncNet model.
- Parameters:
x (torch.Tensor) – Input tensor of shape (batch_size, n_chans, n_times)
- Returns:
out – Output tensor of shape (batch_size, n_outputs).
- Return type:
braindecode.models.tcn module#
- class braindecode.models.tcn.BDTCN(n_chans=None, n_outputs=None, chs_info=None, n_times=None, sfreq=None, input_window_seconds=None, n_blocks=3, n_filters=30, kernel_size=5, drop_prob=0.5, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>)[source]#
Bases:
EEGModuleMixin,ModuleBraindecode TCN from Gemein, L et al (2020) [gemein2020].

See [gemein2020] for details.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
sfreq (float) – Sampling frequency of the EEG recordings.
input_window_seconds (float) – Length of the input window in seconds.
n_blocks (int) – number of temporal blocks in the network
n_filters (int) – number of output filters of each convolution
kernel_size (int) – kernel size of the convolutions
drop_prob (float) – dropout probability
activation (nn.Module, default=nn.ReLU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ReLU.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References
- forward(x)[source]#
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.- Parameters:
x – The description is missing.
- class braindecode.models.tcn.TCN(n_chans=None, n_outputs=None, n_blocks=3, n_filters=30, kernel_size=5, drop_prob=0.5, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>)[source]#
Bases:
ModuleTemporal Convolutional Network (TCN) from Bai et al. 2018 [Bai2018].
See [Bai2018] for details.
Code adapted from locuslab/TCN
- Parameters:
n_filters (int) – number of output filters of each convolution
n_blocks (int) – number of temporal blocks in the network
kernel_size (int) – kernel size of the convolutions
drop_prob (float) – dropout probability
activation (nn.Module, default=nn.ReLU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ReLU.
References
- forward(x: Tensor) Tensor[source]#
Forward pass.
- Parameters:
x (torch.Tensor) – Batch of EEG windows of shape (batch_size, n_channels, n_times).
braindecode.models.tidnet module#
- class braindecode.models.tidnet.TIDNet(n_chans=None, n_outputs=None, n_times=None, input_window_seconds=None, sfreq=None, chs_info=None, s_growth: int = 24, t_filters: int = 32, drop_prob: float = 0.4, pooling: int = 15, temp_layers: int = 2, spat_layers: int = 2, temp_span: float = 0.05, bottleneck: int = 3, summary: int = -1, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.LeakyReLU'>)[source]#
Bases:
EEGModuleMixin,ModuleThinker Invariance DenseNet model from Kostas et al. (2020) [TIDNet].

See [TIDNet] for details.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
n_times (int) – Number of time samples of the input window.
input_window_seconds (float) – Length of the input window in seconds.
sfreq (float) – Sampling frequency of the EEG recordings.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.s_growth (int) – DenseNet-style growth factor (added filters per DenseFilter)
t_filters (int) – Number of temporal filters.
drop_prob (float) – Dropout probability
pooling (int) – Max temporal pooling (width and stride)
temp_layers (int) – Number of temporal layers
spat_layers (int) – Number of DenseFilters
temp_span (float) – Percentage of n_times that defines the temporal filter length: temp_len = ceil(temp_span * n_times) e.g A value of 0.05 for temp_span with 1500 n_times will yield a temporal filter of length 75.
bottleneck (int) – Bottleneck factor within Densefilter
summary (int) – Output size of AdaptiveAvgPool1D layer. If set to -1, value will be calculated automatically (n_times // pooling).
activation (nn.Module, default=nn.LeakyReLU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.LeakyReLU.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
Code adapted from: SPOClab-ca/ThinkerInvariance
References
- forward(x: Tensor) Tensor[source]#
Forward pass.
- Parameters:
x (torch.Tensor) – Batch of EEG windows of shape (batch_size, n_channels, n_times).
- property num_features#
braindecode.models.tsinception module#
- class braindecode.models.tsinception.TSceptionV1(n_chans=None, n_outputs=None, input_window_seconds=None, chs_info=None, n_times=None, sfreq=None, number_filter_temp: int = 9, number_filter_spat: int = 6, hidden_size: int = 128, drop_prob: float = 0.5, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.LeakyReLU'>, pool_size: int = 8, inception_windows: tuple[float, float, float] = (0.5, 0.25, 0.125))[source]#
Bases:
EEGModuleMixin,ModuleTSception model from Ding et al. (2020) from [ding2020].
TSception: A deep learning framework for emotion detection using EEG.

The model consists of temporal and spatial convolutional layers (Tception and Sception) designed to learn temporal and spatial features from EEG data.
- Parameters:
n_chans (int) – Number of EEG channels.
n_outputs (int) – Number of outputs of the model. This is the number of classes in the case of classification.
input_window_seconds (float) – Length of the input window in seconds.
chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
sfreq (float) – Sampling frequency of the EEG recordings.
number_filter_temp (int) – Number of temporal convolutional filters.
number_filter_spat (int) – Number of spatial convolutional filters.
hidden_size (int) – Number of units in the hidden fully connected layer.
drop_prob (float) – Dropout rate applied after the hidden layer.
activation (nn.Module, optional) – Activation function class to apply. Should be a PyTorch activation module like
nn.ReLUornn.LeakyReLU. Default isnn.LeakyReLU.pool_size (int, optional) – Pooling size for the average pooling layers. Default is 8.
inception_windows (list[float], optional) – List of window sizes (in seconds) for the inception modules. Default is [0.5, 0.25, 0.125].
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
This implementation is not guaranteed to be correct, has not been checked by original authors. The modifications are minimal and the model is expected to work as intended. the original code from [code2020].
References
[ding2020]Ding, Y., Robinson, N., Zeng, Q., Chen, D., Wai, A. A. P., Lee, T. S., & Guan, C. (2020, July). Tsception: a deep learning framework for emotion detection using EEG. In 2020 international joint conference on neural networks (IJCNN) (pp. 1-7). IEEE.
[code2020]Ding, Y., Robinson, N., Zeng, Q., Chen, D., Wai, A. A. P., Lee, T. S., & Guan, C. (2020, July). Tsception: a deep learning framework for emotion detection using EEG. deepBrains/TSception
- forward(x: Tensor) Tensor[source]#
Forward pass of the TSception model.
- Parameters:
x (torch.Tensor) – Input tensor of shape (batch_size, n_channels, n_times).
- Returns:
Output tensor of shape (batch_size, n_classes).
- Return type:
braindecode.models.usleep module#
- class braindecode.models.usleep.USleep(n_chans=None, sfreq=None, depth=12, n_time_filters=5, complexity_factor=1.67, with_skip_connection=True, n_outputs=5, input_window_seconds=None, time_conv_size_s=0.0703125, ensure_odd_conv_size=False, activation: ~torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ELU'>, chs_info=None, n_times=None)[source]#
Bases:
EEGModuleMixin,ModuleSleep staging architecture from Perslev et al. (2021) [1].
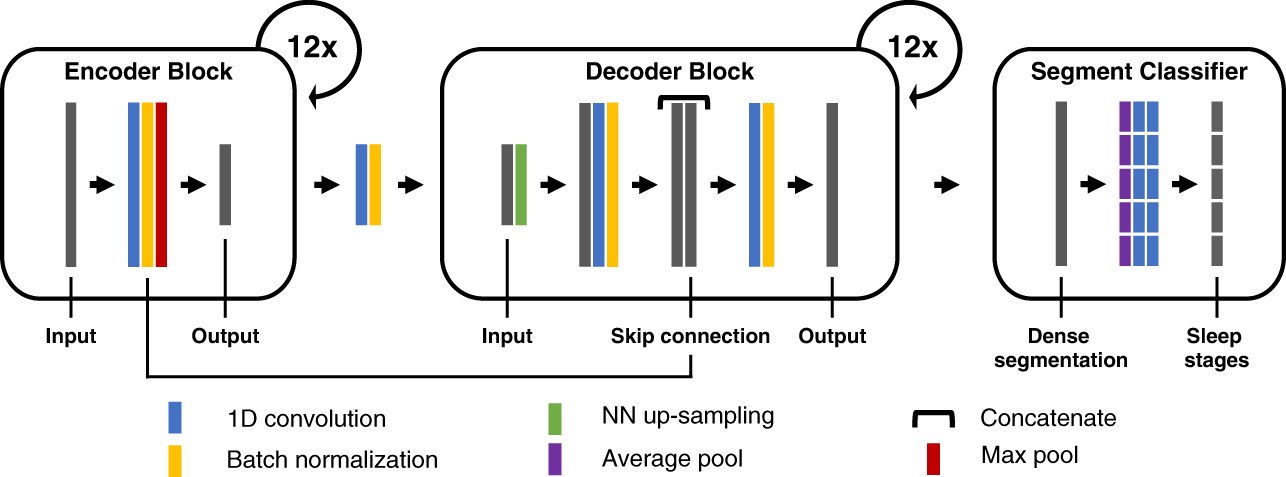
U-Net (autoencoder with skip connections) feature-extractor for sleep staging described in [1].
- For the encoder (‘down’):
the temporal dimension shrinks (via maxpooling in the time-domain)
the spatial dimension expands (via more conv1d filters in the time-domain)
- For the decoder (‘up’):
the temporal dimension expands (via upsampling in the time-domain)
the spatial dimension shrinks (via fewer conv1d filters in the time-domain)
Both do so at exponential rates.
- Parameters:
n_chans (int) – Number of EEG or EOG channels. Set to 2 in [1] (1 EEG, 1 EOG).
depth (int) – Number of conv blocks in encoding layer (number of 2x2 max pools). Note: each block halves the spatial dimensions of the features.
n_time_filters (int) – Initial number of convolutional filters. Set to 5 in [1].
complexity_factor (float) – Multiplicative factor for the number of channels at each layer of the U-Net. Set to 2 in [1].
with_skip_connection (bool) – If True, use skip connections in decoder blocks.
n_outputs (int) – Number of outputs/classes. Set to 5.
input_window_seconds (float) – Size of the input, in seconds. Set to 30 in [1].
time_conv_size_s (float) – Size of the temporal convolution kernel, in seconds. Set to 9 / 128 in [1].
ensure_odd_conv_size (bool) – If True and the size of the convolutional kernel is an even number, one will be added to it to ensure it is odd, so that the decoder blocks can work. This can be useful when using different sampling rates from 128 or 100 Hz.
activation (nn.Module, default=nn.ELU) – Activation function class to apply. Should be a PyTorch activation module class like
nn.ReLUornn.ELU. Default isnn.ELU.chs_info (list of dict) – Information about each individual EEG channel. This should be filled with
info["chs"]. Refer tomne.Infofor more details.n_times (int) – Number of time samples of the input window.
- Raises:
ValueError – If some input signal-related parameters are not specified: and can not be inferred.
Notes
If some input signal-related parameters are not specified, there will be an attempt to infer them from the other parameters.
References